Here I outline an algorithm to parse and efficiently store gigabytes of financial snapshots of thousands of companies in order to graph fundamental changes in their health over time, and to perform machine-learning experiments on the fundamental value of those companies.
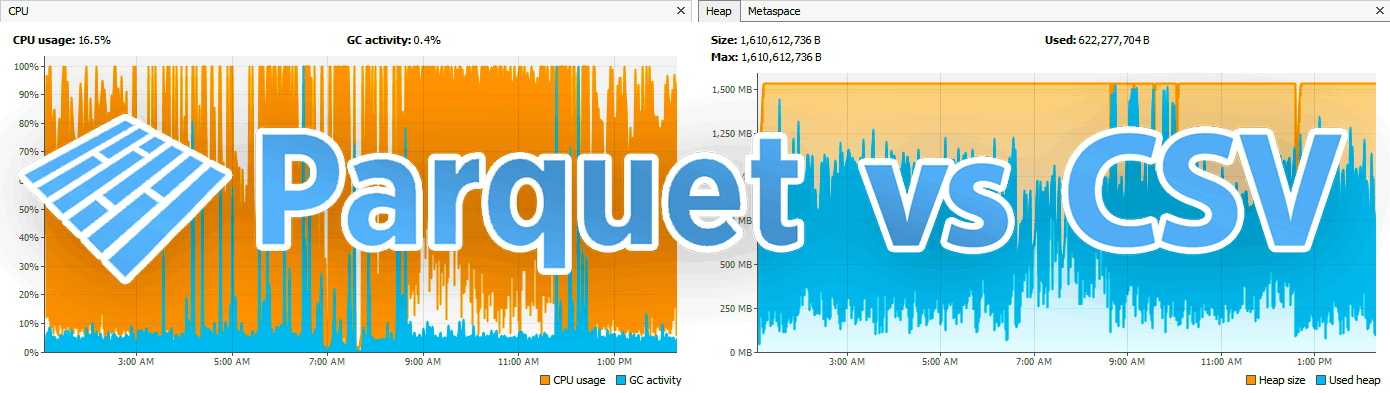
Efficiently transport integer-based financial time-series data to dedicated machines and research partners by experimenting with the smallest data transport format(s) among Avro, Parquet, and compressed CSVs.
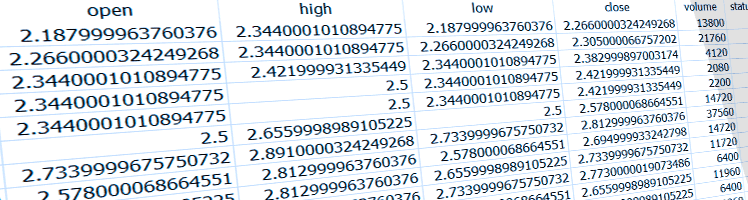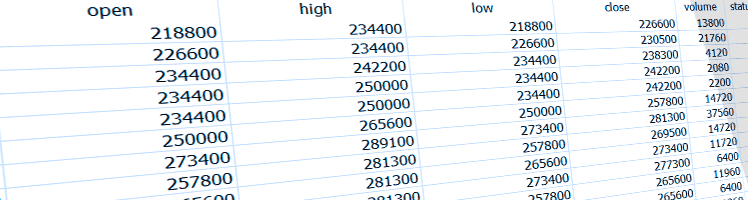
Here I demonstrate the benefits of storing financial numbers as integers instead of doubles in SQLite, maintain a five-decimal precision, and greatly reduce my database size in the process.
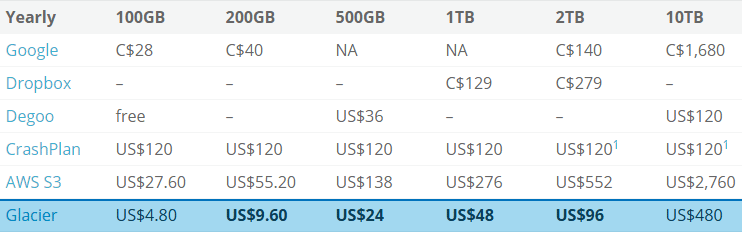
Why use AWS Glacier for big data backup? It’s exceedingly inexpensive to archive data for disaster recovery on Glacier. AWS Glacier is only US$0.004 per GB/mo, and their SDK is beautiful. Here I outline a pricing matrix for cloud storage providers, and I take a look at the Java SDK for working with AWS Glacier to effectively archive 200GB a week.
This is a problem story about how I preferred Java to other languages to communicate with a troublesome financial REST API endpoint because Java is a strongly-typed and verbose language where it is easy to write unit tests and build up solid modules to make a complete, resilient project.
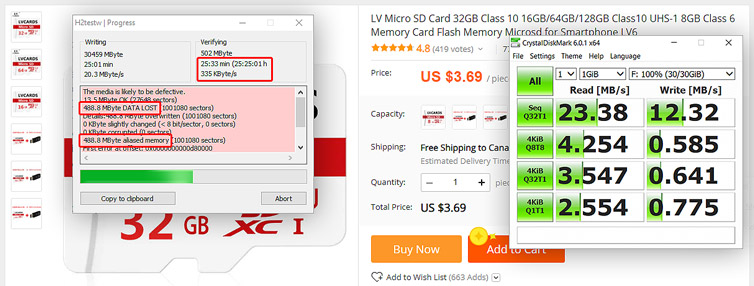
Given a cluster computing rig of twenty-eight processors, each can have either a USB 2.0 or microSD local flash storage. Which type of flash and maker is the fastest? Make the wrong choice and the cluster is painfully slow. Not all microSD cards or USB drives are made the same, and interestingly random read and write speeds vary wildly. Here I test several storage configurations with striking benchmark results.
For the cluster computing project I’m working on, I need 28 microSD cards. There was an AliExpress sale with good reviews, so I ordered a batch of 30 microSD cards, and at a great price point at the time. As long as the cards are Class 10 and work then we should be good, right? Results: Half are fake or defective. The rest are painfully slow. No refunds.
Let’s build a 112-core 1.2GHz A53 cluster with 56GB of DDR3 RAM and 584GiB of high-availability distributed file storage, running at most 200W. The goal is to use cluster computing to perform fast Apache Spark operations on Big Data, and all on-prem for a fraction of what cloud computing costs.
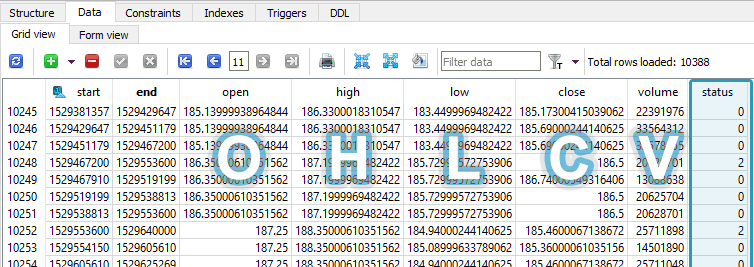
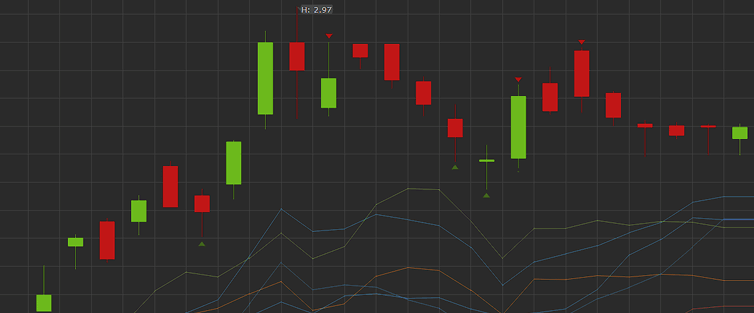
Problem: How to clean the raw OHLCV candle data from the broker for time series analysis? Suppose we have an autonomous program that prioritizes and continually downloads the latest minute and day candles, as well as periodically gets new symbols from the broker. The problem is that the candles are not guaranteed to be full-period […]
Before acquiring financial time-series candles, I need to know the database schema, storage growth, and cost of maintaining the database. How large could financial data grow and cost?
This would make a good interview question: There are about 120,000 public North American securities, bonds, rights, and index symbols. You have a paid API that can access all of them in OHLCV format if they are quotable. There are two critical API constraints: 15,000 calls per hour 20 calls per second Napkin math Minute […]