I show you how I permanently un-adblock Google Analytics to get full visitor insights on my pages through some zany techniques. I thought about patenting these, but it’s more fun to share. Enjoy total visitor analytics despite regex-based adblockers and DNS blockers (e.g. Pi-Hole).
Here I outline an algorithm to parse and efficiently store gigabytes of financial snapshots of thousands of companies in order to graph fundamental changes in their health over time, and to perform machine-learning experiments on the fundamental value of those companies.
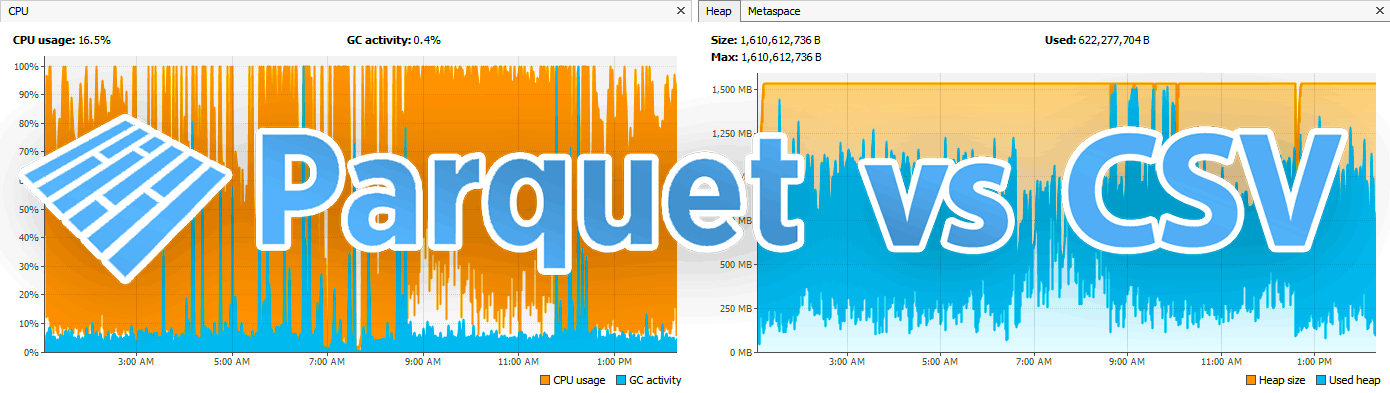
Efficiently transport integer-based financial time-series data to dedicated machines and research partners by experimenting with the smallest data transport format(s) among Avro, Parquet, and compressed CSVs.
Because I enjoy using Java so much, and maybe as a reference for the next time I’m playing code golf, I’ve noted some of the lesser-known, obscure features and quirks of Java 8+. You probably know them already, but I find them neat and want to reference them here.
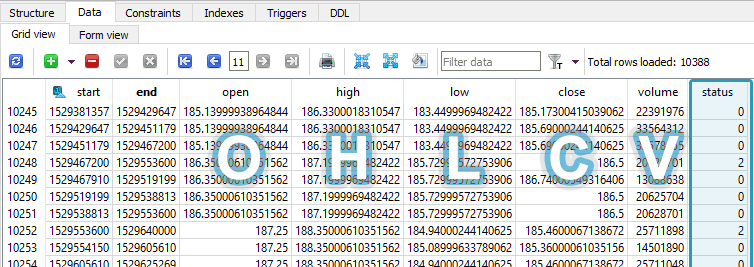
Problem: How to clean the raw OHLCV candle data from the broker for time series analysis? Suppose we have an autonomous program that prioritizes and continually downloads the latest minute and day candles, as well as periodically gets new symbols from the broker. The problem is that the candles are not guaranteed to be full-period […]
This would make a good interview question: There are about 120,000 public North American securities, bonds, rights, and index symbols. You have a paid API that can access all of them in OHLCV format if they are quotable. There are two critical API constraints: 15,000 calls per hour 20 calls per second Napkin math Minute […]
I’d like to share my efforts to prevent page breaks in the middle of paragraphs and maximize the use of page space when printing web pages to PDF. I’ll outline how this PHP+NodeJS+Chrome tool and algorithm accomplish this. The motivation is to prevent pictures from being cut off, cut halfway through, or from being pushed […]