Parse, Store, and Graph Large Company Financials Data for ML Experiments
In this instance, we’ll go from ~100GB of JSON to only 10GB of SQL.
Motivation
Say a given company’s financials are represented by about 50kB of JSON. How to store this for every company daily? You’d be forgiven for thinking this only changes once a quarter, but as shares are issued, or bought back, the float changes. Not to mention corrections happen. Additionally, looking at all companies together, a quarter can end in any month and the audited financials can come anytime after that. It makes sense to check the financials of all companies daily.
That poses the problem of how to store, say, 50kB x 10,000 companies per day. Among friends, let’s round that to about a half a gigabyte of JSON text consumed per day.
Sample Data
Say I have some semi-structured, nested financials JSON data that starts like the following:
1 | {"cashflowStatementHistory":{"cashflowStatements":[{"investments":58093000000,"changeToLiabilities":-2548000000,"totalCashflowsFromInvestingActivities":45896000000,"netBorrowings":-7819000000,"totalCashFromFinancingActivities":-90976000000,"changeToOperatingActivities":-896000000,"issuanceOfStock":781000000,"netIncome":55256000000,"changeInCash":24311000000,... ~49kB more |
How to parse and store this in a way that lets us maintain company financials as a time series without storing an incredible amount of redundant data?
Possible Strategies
Here are some pros and cons of a handful of storage strategies.
- SQL DB – Flatten the financials object tree into several hundred properties and thus table columns.
- Time-series analysis is easy and convenient.
- Over 700 columns!
- Graph DB – Store the object tree as a graph and add timestamped-nodes as values change.
- Minimal data storage.
- Time-series analysis is inconvenient and slow.
- Text files – Store the raw JSON text to disk as files with timestamps.
- Very easy to store the data.
- Requires ~500MB per day and time-series analysis is not possible.
- Diffs – Diff the JSON text and store the differences.
- Minimal data storage.
- The order of properties in the JSON is not guaranteed so diffs can be large.
Chosen Strategy
My plan is to develop a superset of all financial data structures by analyzing several of the largest companies with complex financials.
With this superset, most if not all companies’ financials will be a subset of the available structures. We then parse the JSON financials into object trees using well-defined DTO classes (discussed soon). A treatment of annotating fields that we would like to ignore will reduce the data footprint.
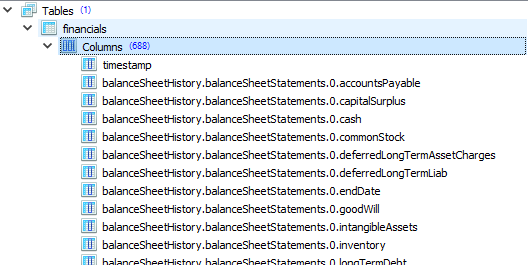
Next, I flatten the object graph and generate unique column names and data types to create a DB schema. There are over 700 columns. Here is a sample of column names and data types:
1 2 3 4 5 6 | balanceSheetHistory.balanceSheetStatements.0.accountsPayable: Long balanceSheetHistory.balanceSheetStatements.0.capitalSurplus: Long balanceSheetHistory.balanceSheetStatements.0.cash: Long balanceSheetHistory.balanceSheetStatements.0.commonStock: Long balanceSheetHistory.balanceSheetStatements.0.deferredLongTermAssetCharges: Long ... |
The vast majority of columns are Long types, but there are some Double types (e.g. dividend rate). I love storing financial numbers as integers, but let’s not kick up a fuss about 5% of the columns being Double types.
Here is what the auto-generated DB schema will start looking like:
1 2 3 4 5 6 7 | CREATE TABLE IF NOT EXISTS financials ( [balanceSheetHistory.balanceSheetStatements.0.accountsPayable] INTEGER, [balanceSheetHistory.balanceSheetStatements.0.capitalSurplus] INTEGER, [balanceSheetHistory.balanceSheetStatements.0.cash] INTEGER, [balanceSheetHistory.balanceSheetStatements.0.commonStock] INTEGER, [balanceSheetHistory.balanceSheetStatements.0.deferredLongTermAssetCharges] INTEGER, ... |
Even if there are 700 columns, that’s about 700 x 8B = 5.5kB per company for large companies (few null fields). Then daily the data footprint becomes 5.5kB x 10,000 companies which is only about 55MB per day! Huge savings over the previous 500MB per day.
Part 1
First, let’s map the JSON to DTOs (POJOs).
Step 1 – IntelliJ IDEA and Json2Pojo
IntelliJ IDEA has a plugin in Marketplace called Json2Pojo with Lombok (GitHub) that accepts a well-formed JSON string and can generate classes with Lombok @Data annotations.
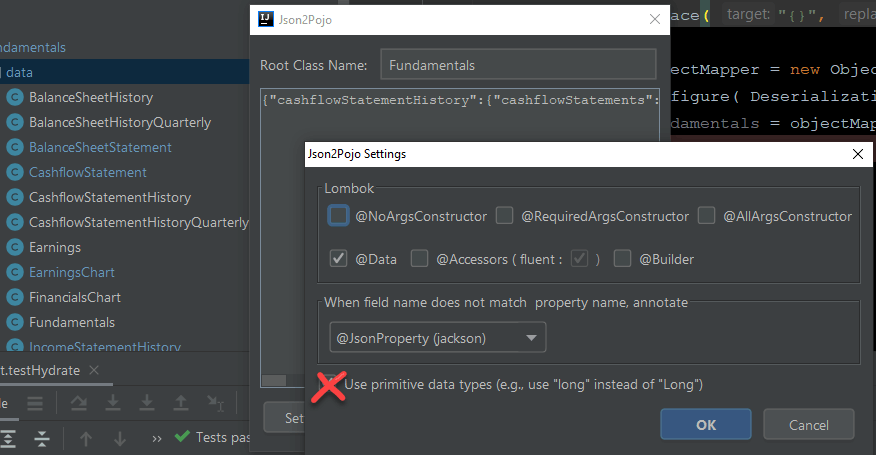
This does a decent job, however, it will generate a lot of empty classes if properties are found with the value {}. Also, don’t use primitive data types so we can preserve nulls in the database if needed.
{} to null beforehand to avoid generating empty classes.Here is a sample of a generated POJO with Lombok.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import lombok.Data; @Data @SuppressWarnings("unused") public class BalanceSheetStatement { private Long accountsPayable; private Long capitalSurplus; private Long cash; private Long commonStock; private Long deferredLongTermAssetCharges; private Long deferredLongTermLiab; private Long endDate; private Long goodWill; private Long intangibleAssets; private Long inventory; private Long longTermDebt; ... |
Step 2 – Repeat several times
Create a feature branch in Git and generate classes from the JSON string for a given company. Commit. Generate classes for another company.
You’ll notice that fields may be added or removed and a git-diff shows these changes. With git tools, keep the additive changes and revert the subtractive hunks. Repeat this as many times as necessary to build a POJO1 (or DTO2) profile of the available overall financial data for all companies we have access to.
Step 3 – Prepare to parse any JSON representation
Be sure to replace {} to null. Also, make sure to not fail on unknown properties (unless you really want to discover obscure, additional properties).
A successful hydration of the DTOs looks like this:
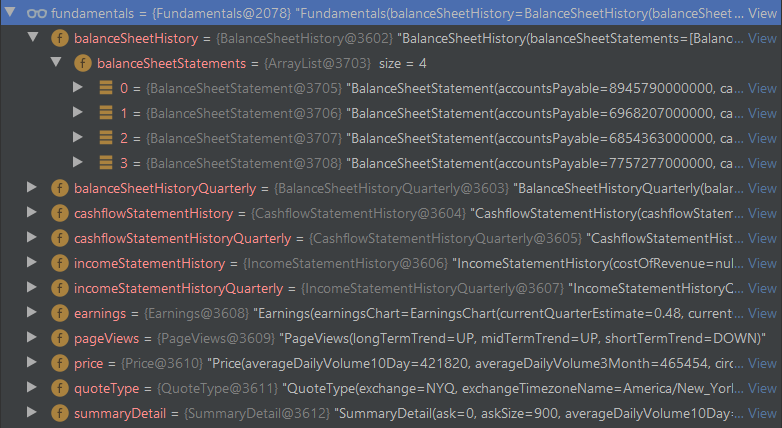
Step 4 – Deal with exceptions
Every now and then curveballs like this will fly at you.
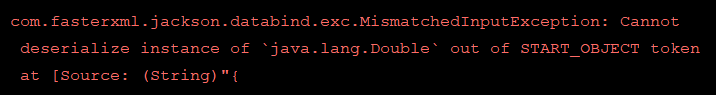
In my case, one DTO has this generated field:
1 | private Double priceToSalesTrailing12Months; |
Then one day the field isn’t a Double; it’s an Object. Here is the offending JSON snippet:
1 2 3 | "priceToSalesTrailing12Months": { "raw": "Infinity" }, |
We could change the field type from a Double to an Object or JsonNode. With logging on exceptions, we could manually update the DTO fields and remember in code to check the instanceof of those fields if they are Long, Double, or what have you. You could do this.
Another way is to annotate an explicit setter. If the JsonNode is not of a numeric type, it will remain null which is what we want.
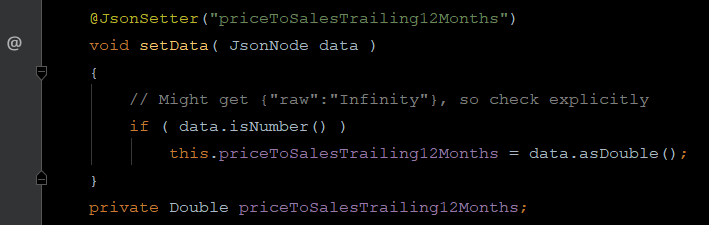
Even better, way better, is to use a custom deserializer on Double types.
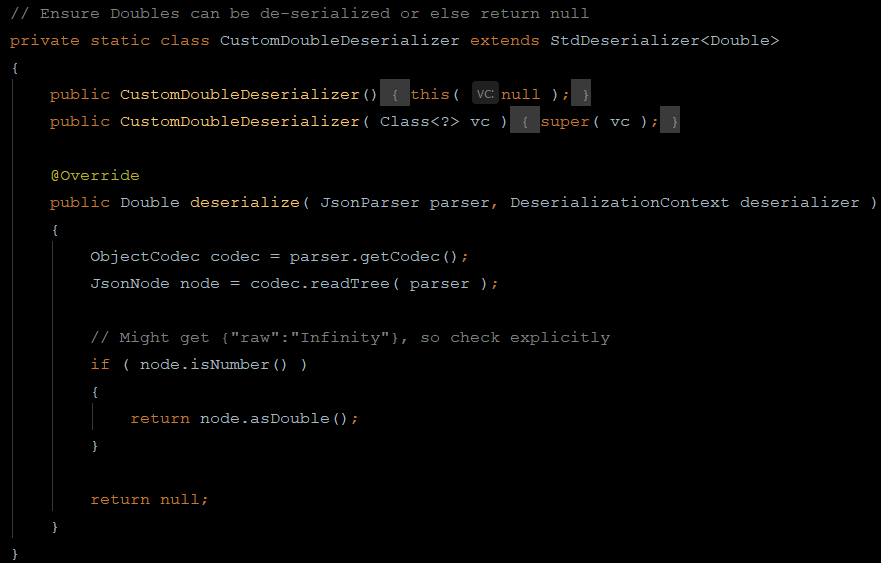
The ObjectMapper can then be configured like so:
1 2 3 4 5 6 7 | ObjectMapper objectMapper = new ObjectMapper(); objectMapper.configure( DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, true ); SimpleModule module = new SimpleModule( "CustomDoubleDeserializer", new Version( 1, 0, 0, null, null, null ) ); module.addDeserializer( Double.class, new CustomDoubleDeserializer() ); objectMapper.registerModule( module ); |
Step 5 – Ignored Financials Fields
Through experience, there will be fields that never change or we are not interested in. For example, some things like stockSymbol and currentPrice can be ignored. I like to create a custom annotation @Ignore on them so that when I flatten the object tree (next step) they will not be included, but keeping them into the DTOs reminds me I know about them.
1 2 3 4 5 6 | @Ignore private String shortName; @Ignore private String stockSymbol; @Ignore private String underlyingSymbol; |
Step 6 – DTO Validation Checking
This is optional, but without it, we may get data like this in the database:
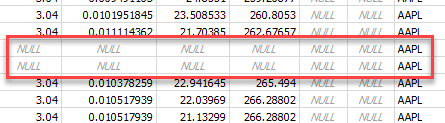
We can see that the rows are not completely filled with nulls as the AAPL symbol is present at the end, but this is clearly bad data we do not want. Perhaps this data came as a glitch in the upstream API. To avoid this, I like to use javax.validation annotations on the fields of my DTOs. Here is a sample:
1 2 3 4 5 6 | @NotNull private SummaryDetail summaryDetail; @NotNull private QuoteType quoteType; @NotBlank private String symbol; |
Then on-demand these DTOs can be validated programmatically to get a list of violations and throw an exception. Given the above sample fields with annotations, the unit test below will give three violation messages on an empty object.
1 2 3 4 5 6 7 8 9 10 11 12 | @Test void testViolation() throws IOException { ObjectMapper objectMapper = new ObjectMapper(); FinancialsData data = objectMapper.readValue( "{}", FinancialsData.class ); // Clear consstraint violations ValidatorFactory factory = Validation.buildDefaultValidatorFactory(); Validator validator = factory.getValidator(); Set<ConstraintViolation<FinancialsData>> violations = validator.validate(data); assertThat(violations, hasSize(3)); } |
Part 2
Let’s save the DTOs to the DB without ORM3.
Step 7 – Flatten the Object Tree
This is the most fun step. Here we walk the object tree (say, AAPL) and collect an ordered set of properties and value types (not values themselves!) using Reflection. This is where a structure like
1 2 3 4 5 | FinancialsData BalanceSheetHistory balanceSheetHistory List<BalanceSheetStatement> balanceSheetStatements 0 Long accountsPayable |
becomes
1 | balanceSheetHistory.balanceSheetStatements.0.accountsPayable: Long |
There are gotchas:
- For list fields, make sure the entries are sorted before flattening.
- List entries may be primitives.
- For lists with over 10 known entries, left-pad the indices with zeros to allow natural string sort.
- Using a TreeMap keeps the properties sorted alphabetically.
1,12,..19,2,21 is not what we want. We want 01,02,03,...,19,20,21.Step 8 – Generate the DB Schema
Now that we can walk the object tree and flatten it to unique properties and types, it’s quick to transform
1 2 3 4 5 6 | balanceSheetHistory.balanceSheetStatements.0.accountsPayable: Long balanceSheetHistory.balanceSheetStatements.0.capitalSurplus: Long balanceSheetHistory.balanceSheetStatements.0.cash: Long balanceSheetHistory.balanceSheetStatements.0.commonStock: Long balanceSheetHistory.balanceSheetStatements.0.deferredLongTermAssetCharges: Long ... |
into
1 2 3 4 5 6 7 8 9 | CREATE TABLE IF NOT EXISTS financials ( timestamp INTEGER DEFAULT (cast(strftime('%s','now') as INTEGER)) PRIMARY KEY, [balanceSheetHistory.balanceSheetStatements.0.accountsPayable] INTEGER, [balanceSheetHistory.balanceSheetStatements.0.capitalSurplus] INTEGER, [balanceSheetHistory.balanceSheetStatements.0.cash] INTEGER, [balanceSheetHistory.balanceSheetStatements.0.commonStock] INTEGER, [balanceSheetHistory.balanceSheetStatements.0.deferredLongTermAssetCharges] INTEGER, ... ); |
For various reasons, I consume data and store it to SQLite databases with my edge machines. For my purposes, I only need to concern myself with INTEGER, REAL, and TEXT data types in SQLite. Column names need to be enclosed in square brackets due to the dot-notation of the column names. A SQLite file is then created for each public company.
You may be asking yourself why the primary key is the timestamp. Just like with storing candle data, we don’t need an auto-incrementing primary key with this flat data. What we do need is a unique timestamp column which is declared above.
Step 9 – Store JSON to the DB
We now have a JSON parser, a mechanism to ignore some fields, a way to flatten the data, and a schema to store the data in the DB.
To store real data, we proceed like so: parse the JSON, flatten, and generate an insertion query on the fly. Why not use prepared statements? We could, and being clever with Reflection we could dynamically invoke methods like statement.setInt(). The thing is, these statements are designed for reuse across multiple queries; here, we open a DB, write one row, then close the DB.
Also, 99% of fields are numeric. If we are careful, and lean on the DTO validation during JSON parsing, we can craft raw queries and avoid SQL-injection pitfalls and sneaky double-quotes. Essentially, everything except integers and booleans needs quotes in raw queries. Here is a sample insert query:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | INSERT OR REPLACE INTO financials ( timestamp, [balanceSheetHistory.balanceSheetStatements.0.accountsPayable], [balanceSheetHistory.balanceSheetStatements.0.capitalSurplus], [balanceSheetHistory.balanceSheetStatements.0.cash], [balanceSheetHistory.balanceSheetStatements.0.commonStock], ... [summaryDetail.yield], [summaryDetail.ytdReturn], [symbol] ) VALUES ( 1593293477 37294000000, 31251000000, 20484000000, 1474675200, ... "27.634352", "294.87332", "AAPL" ); |
In Practice
Months ago, I started with strategy three – saving text files to disk. What happened was after several months I accumulated about 4 million JSON text files for every company – representing a financial snapshot a few times a day – coming to an impressive 110GB.
I came up with a script to iterate over the 4 million JSON text files, parse them, flatten the objects, and insert the rows in timestamp-order for the over 10,000 companies. This took about 6 days to complete on spinning HDDs. A little time-intensive? Sure, but it only needed to be done once. Now, all that data is represented by and is SQL-queryable from only 10GB of SQLite DBs.
Results
Let’s see how AAPL’s financials change from quarter to quarter so far in 2020.
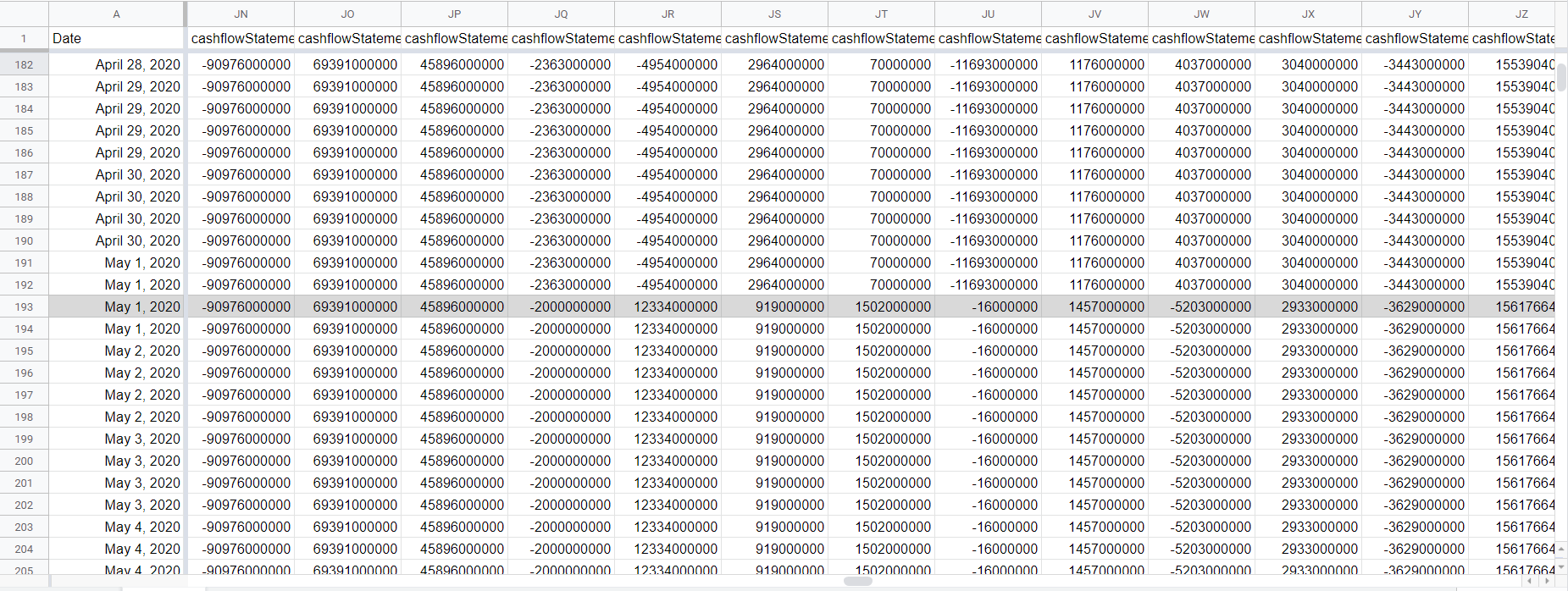
From this, we know May 1st is an interesting day. Note that May 1st was checked twice, but only from the third check the financials were observed to change.
Once this obvious change in financials has been detected – signaling a quarter change – we could wait for a quarter (three months) before checking for new financials, right? Consider the following view for May 1st and May 2nd where some correction took place.
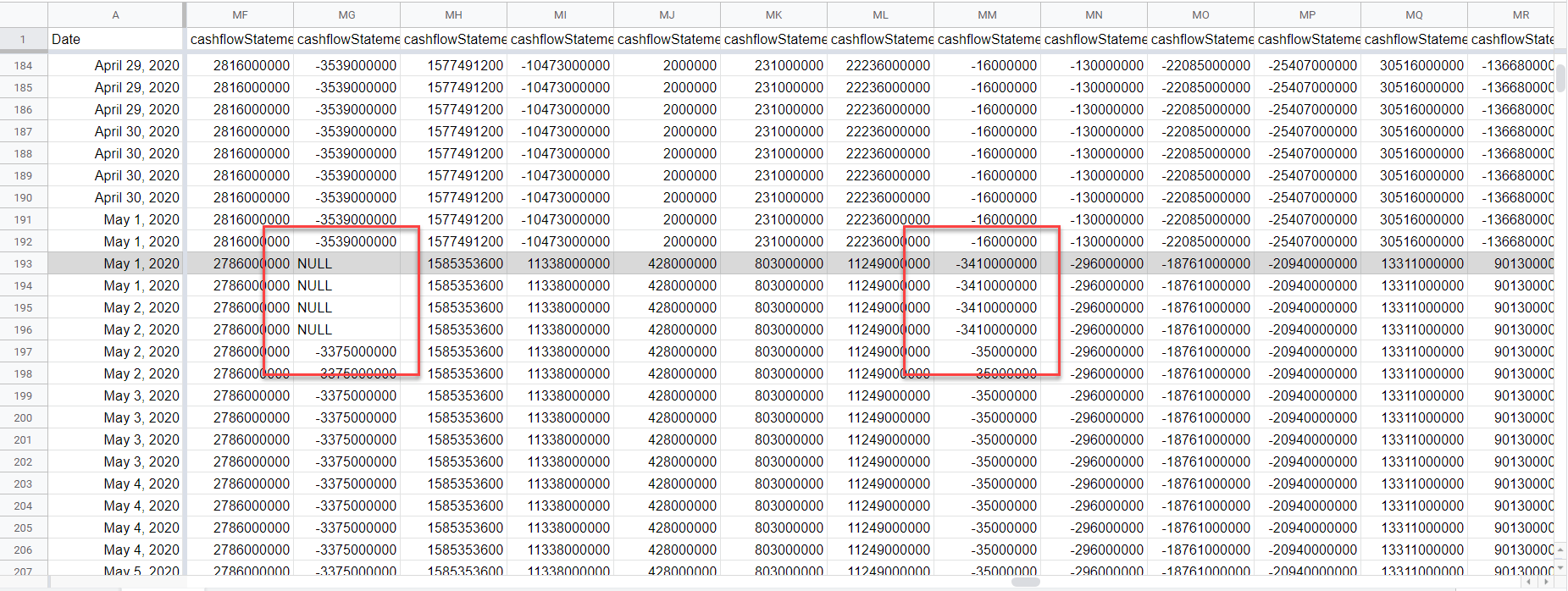
For this reason, it is prudent to at least check the financials daily if using them to make financial decisions, like calculating the Altman-Z Score4, or keeping an eye on P/E ratios.
Conclusion
With this successful approach, we can now consume a vast amount of financial data on a regular basis, parse rich data structures with initially-unknown JSON schema, flatten the data, and store the data into a time-series-friendly database in order to perform our own machine-learning experiments on the fundamental value of companies over time. In practice, I reduced 110GB of JSON text files to 10GB of SQL data.
Notes: