Defensive Programming for an Unreliable Financial API
This is one of the most difficult APIs I’ve ever had to work with, but it was satisfying to overcome the technological challenges of the endpoint(s) being unreliable. This real-time financial REST API is continuously called with data consumed around the clock but is prone to all kinds of server trouble: downtime, illogical errors, OAuth failures, server IP changes, rate-limiting, soft IP bans, and more. The API sink server must never crash or else one-shot data1 could be missed and lost forever.
Challenges:
- Rate limit of 20 calls/s, 15,000/hour
- Auth token exchange every 30 minutes
- API endpoint changes every night
- Servers go down for maintenance at different times
- Excessive rate limit violations result in a soft IP ban
- The auth server goes down nightly as well
- Easy to create a 400-error (bad request)
- Too many bad requests result in a soft IP ban
- Server errors could be: 50x, 401, 302, SSL handshake, timeouts, and DNS resolution errors
- Response bodies are usually around 2MB (no GZip enabled)
- The API sink server must never crash
The scenario:
This API is to be called continuously every day, every week.
The given API has a strict rate limit of 20 calls per second, 15,000 calls per hour, and auth token renegotiation every 30 minutes. Additionally, the API endpoint changes randomly every night, the servers go down for hours for maintenance semi-randomly, and if the rate limit is exceeded too often then the calling IP gets banned for the day. Finally, the auth server to renew the private token goes down at night as well, so if the renewal chain is broken then it needs to be reinitialized manually. The current auth token may be revoked at any time.
Once all the above is overcome, then the data needs to be requested carefully. Date ranges for historical data can be supplied. If we go too far in the past, then we get a 400 Bad Request error. If we go within range, but no data is found, then it is a 404 Not Found error. Too many 400-errors results in an IP ban for the day. Allowed date ranges for different REST queries are undocumented.
Additionally, server errors take the form of 50x errors, 401 errors, 302 redirects to error pages, SSL handshake errors, timeouts, and DNS name not resolved errors. There is no consistent way to determine if the API/auth server is down.

When all the above is working, the response body to each request may be around 2MB of uncompressed JSON as the API vendor does not want to enable GZip compression due to CPU overhead.
Design considerations:
What do we need to implement to successfully interact with this sensitive API?
- Database read/write concurrency
- Multi-threaded network requests
- Dynamic rate limiting
- Automatic VPN hopping
- Automatic token exchange
- Discover allowed date ranges
- Sink up to 60MiBps
- Back-off on server/network trouble
- Detect auth server trouble
- Manually introduce the first token
- Extensive logging
- Crash resilience
How challenges were overcome:
- Rate limiting – Use a network interceptor to issue permits (and threads) at the prescribed rate. Run at full throttle until there are only a few hundred calls remaining for the hour and adjust the rate. Reset the rate when the hour has elapsed.
- Token exchange – When a 401 unauthorized header is received, or the token has only a few seconds remaining, block all network requests and exchange the token.
- Back-off – On the first signs of wire trouble (timeouts, 50x errors) back off the number of network threads to a single thread to probe the servers. Increase the threads when connectivity resumes.
- Allowed date ranges – Manual trial and error. Store the results in some limits class as constants.
- Introduce the first token – Request the initial token on the CLI. After a timeout, check a private Slack channel for the auth token and mark it as read.
- VPN hopping – On tell-tale errors, change the VPN server via a shell command to the server running OpenVPN.
- Handle 60MiBps – Have a USB2 or better storage sink. Here, HDDs are better suited than SSDs.
- Extensive logging – Combine Logback with a Slack handler, create dedicated Slack channels, and assign log levels to each channel. Eventually, this could transition to a service like Sentry.
- Detect auth server trouble – Before any token exchange, ping the auth server, then submit an invalid token to examine the error response. If the auth server behaves as expected, it is likely up (but not guaranteed). You only have one chance to exchange a token.
- Crash resilience – Every class is minimal and specific to a job. Each class must have a battery of unit tests. Exceptions trigger network back-off, network probing, VPN hopping, and wait-for-retries. The JVM is not allowed to be killed by the OS (OOM). There is a manual garbage collection policy.
Which language to use:
Developing a connector in Python, C++, NodeJS, and Java were the possibilities.
Java
I chose Java because it is a strongly-typed language resulting in few coding surprises, and it is breezy and rewarding to create JUnit tests for each class, and integration tests between those classes, and finally application tests. Various server errors can be simulated with mock servers including timeouts, SSL handshakes, and servers that just go missing suddenly. Plus, there is an amazing codebase of libraries and frameworks for networking in Java already (Spring, Apache).
Unit tests
An important aspect of this project is the unit tests. This is a surprising API and it should be no surprise that it will keep on surprising. When the uneasy truce between developing the API connector and the undocumented aspects shift, the unit tests will pinpoint accurately how to proceed.
ETL
Finally, it isn’t specified what will be done with the data. The ETL/ELT can be done in any other language given the databases, so as a standalone application Java is just fine to constantly consume data from a service.
Results
API servers randomly change, servers go down for hours at a time at different times of day, and unexpected server errors arise frequently, but the sink server doesn’t crash. Hooray. Garbage collection is tuned and performed manually via code, and the Linux OOM-killer is not allowed to sacrifice the daemon. HDDs are used over SSDs because SSDs wear out much faster on continuous writes.
Recoverable errors and warnings are pushed to Slack with normal logging done on disk. Below, for example, I can see the auth server went down for maintenance at 01:37 in the morning.
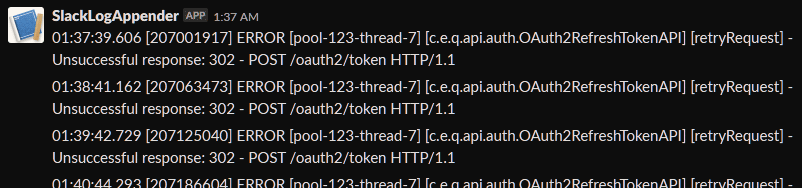
So far the Java daemon just runs and runs.
1 2 3 | # Use pidof to find the PID of the only java app running > ps -eo pid,lstart,etime | grep `pidof java` 7614 Mon Mar 11 16:07:34 2019 5-17:50:17 |

With the above ps command, at the time of this entry, I can see that the process was started 5 days and almost 18 hours ago. The daemon has indeed survived five nights of server trouble so far.
Notes:
- There is just one chance to consume some of the daily data. For example, the number of outstanding shares changes daily, but there is no history or archive of these changes. ↩