Learning Python as a Java Developer: Write a Linux RGB-LED CPU Monitor and Daemon
Given a FadeStick to handle animations itself, let’s write some Python 3 driver code.

Sections
- First Python Observations as a Java Developer
- Which Python IDE?
- Goal 1: Understand Some Python Code
- Goal 2: Write Unit Tests
- Goal 3: Run all Unit Tests Everywhere in PyCharm (demo)
- Goal 4: Issue USB Color Animation Commands
- Goal 5: Interrogate the CPU (demo)
- Goal 6: Write a Daemon in Python (demo)
- Goal 7: Package the App into a Standalone Executable
- Results (source code)
— - Bonus: Automatic Code Formatting on File Save
- Bonus: Inter-Process Communication (IPC)
- Bonus: Reduce Standalone Binary Size
First Python Observations as a Java Developer
Here is a Reader’s Digest of my first Python observations as a Java developer.
- Python is five years older than Java (released in ’91 vs ’96).
- A char (
'') and a string ("") can be mixed and matched, but not in Java. - String multiplication is new. E.g.
print("a" * 5)results in “aaaaa”. - Negative indices wrap around, but just once. E.g.
"abc"[-1]isc, but"abc"[-3]is an error. - Multiple ways to format strings exist. E.g.
print('%d %d' % (1, 2)),print(f'{1} {2}'), … - String formatting is a joy to work with in Python 3.
- Python has Heredoc strings using
""". Java got that late in JDK 15. - I have no idea how lists, tuples, and dictionaries use memory under the hood, and I’m worried.
- It will take a while to get used to
TrueandFalse– Pascal case. if not x % 2:is valid syntax, butif ! x % 2is not. In Java it’sif( x % 2 != 0 ){...}.- Python functions can have default values like PHP and C++. E.g.
def println(x=""):. - PyCharm wants two blank lines after a class or function definition.
- Class variables are public by default.
- There is no
newkeyword when instantiating new objects (but__new__exists). selfis a parameter that can be passed to class members similar to JavaScript.- Class variables can be first “declared” in the
__init__method of a class. Quite JS-like. - Displaying dates and times is much more convenient in Python than in Java.
- Importing classes and functions feels very NodeJS-like.
- Lists can end with a trailing comma like in TypeScript.
- Variables and functions are all lowercase. Coming from Java, this feels unnatural.
- Python uses
Noneinstead ofnull, and automatically returnsNonewithoutreturn. - Python hints at private methods with an underscore prefix. E.g.
def _privateMethod(): - Empty collections evaluate to
False. E.g.assert not []is valid. - The order of imports matters – it’s possible to get circular dependencies.
- Python has interval comparisons. E.g.
if 0 <= number <= 255:. That’s cool. - There is no ternary operator (
?and?:). - Lambdas exist, kind of. Observations are here.
- Python uses named parameters (ordered by default). Love this.
- Class variables are also called “fields” like in Java.
- Try-with-Resources is accomplished with the
withkeyword. Nice. - Python can return (
yield) from atry-raisethen come back to thefinally. Not in Java. - There is no
switchstatement in Python – useif-elif. - Serializing “objects” is called pickling. De-serializing is called _unpickling_1.
Let’s go from for-loops right to our featured project with no ramp-up.
Which Python IDE?
Which IDE to use for this project? Books and tutorials seem to favor Sublime Text. Let’s use JetBrains PyCharm Professional in Linux. I’ve not used it before, but it’ll probably be my new favorite IDE because JetBrains consistently makes my development life convenient and enjoyable. We have breakpoints, jumping to methods, Code With Me, Docker integration, and much more.
Hello, what is this PyCharm Edu?

Some helpful people put together courses on Python which run right in PyCharm, and it even integrates into Coursera online learning. Thoughtful.
Goal 1: Understand Some Python Code
Most of the boilerplate is done for us, so we just have to extract the IO features for USB communication of the BlinkStick, update the code for Python 3, and add in a lot of custom driver code, CPU monitoring code, and daemonize the app. First, let’s reverse engineer BlinkStick-Python to understand what a Python app looks like.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | from ._version import __version__ import time import sys import re import collections if sys.platform == "win32": import pywinusb.hid as hid from ctypes import * else: import usb.core # Not found import usb.util # Not found from random import randint """ Main module to control BlinkStick and BlinkStick Pro devices. """ ... |
This ~1600 LOC looks readable enough. Let’s write a main file that checks if the FadeStick is in the USB.
usb.core?Here a first attempt to access a USB device.
1 2 3 4 5 6 7 8 9 10 | import usb.core # Not found def main(): print(f'Found FadeStick:') print(usb.core.find(find_all=False, idVendor=FS_VENDOR_ID, idProduct=FS_PRODUCT_ID)) if __name__ == "__main__": # This is the entrypoint to the script main() |
There are underlines in PyCharm asking if we want to import usb.core and usb.util. Research shows that if we add a requirements.txt to the project root with the following entry, the problem is solved.
1 2 | # requirements.txt pyusb~=1.1.1 |
The “hello world” script now succeeds with:
1 2 3 4 5 6 7 8 9 | /home/build/PycharmProjects/CPUFadeStick/venv/bin/python /home/build/PycharmProjects/CPUFadeStick/main.py Found FadeStick: DEVICE ID 20a0:41e5 on Bus 002 Address 004 ================= bLength : 0x12 (18 bytes) bDescriptorType : 0x1 Device bcdUSB : 0x110 USB 1.1 bDeviceClass : 0x0 Specified at interface bDeviceSubClass : 0x0 ... |
Coming from C++, Objective-C, and Java, camelcase is the only case that gives me pride in my work. Let’s turn off these case errors in PyCharm.
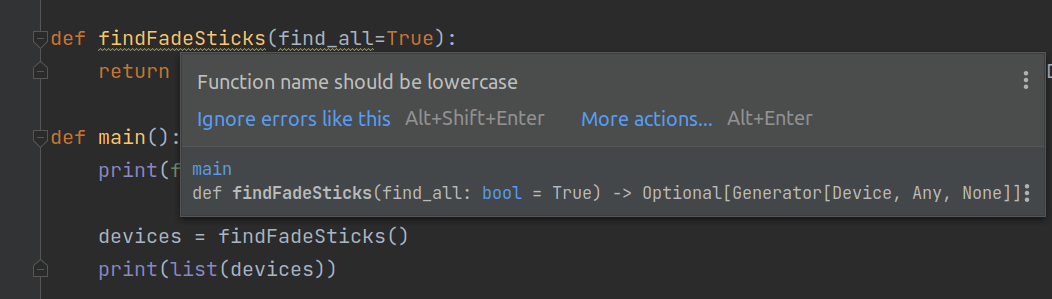
Coming from Java (and this being day one of Python), let’s use camelcase and place each class is in its own file. This should make unit testing cleaner, right?
No idea. However, as of Python 3.8 (Oct 2019), there is typing.Final so we can write constants like so:
1 2 3 | from typing import Final VENDOR_ID: Final = 0x20a0 # VENDOR_ID now cannot be changed |
As of Python 3.5 (Sept. 2015), we can take advantage of type hinting like so.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | def findAllFadeSticks() -> List[FadeStick]: # Return type hinting results: List[FadeStick] = [] # List elements type hinting for d in findFadeSticksAsGenerator(): results.extend([FadeStick(device=d)]) return results def findFadeStickBySerial(serial=None) -> FadeStick: devices: List[FadeStick] = [] for d in findFadeSticksAsGenerator(): try: if usb.util.get_string(d, 3, 1033) == serial: devices = [d] break except Exception as e: print("{0}".format(e)) if devices: return FadeStick(device=devices[0]) |
Additionally, and this is like TypeScript, we can hint multiple types as well. For example:
1 2 3 | def sendData(Union[bytes, list]) -> bool: ... # or even better def sendData(Union[bytes, bytearray, List[int]]) -> bool: ... |
We can use the magic method __repr__ in each object to achieve this. If __str__ is not defined, then a str(my_object) call will use __repr__. Here is an example:
1 2 3 4 5 6 7 8 9 | class FadeStick(FadeStickBase): # Called when print([FadeStick, FadeStick]) def __repr__(self): return "<" + self.__str__() + ">" # Called when print(FadeStick) def __str__(self): string = f"FadeStick[{self.device if self.device else ''}]" return string |
Goal 2: Write Unit Tests
My FadeStickUSB.py USB abstraction class is getting complex. Let’s write some unit tests in Python, but how?
PyCharm helpfully auto-generates a unit test stub, but we have to name it. From research, many people prefer to prefix or affix unit tests with test_ or _test.py and place them in the same folder as the source code. Coming from Java, we know that a dedicated tests folder holds JUnit tests (which I’m told inspired Python unit tests). Why the same folder as code? I’m told it makes refactoring safer. Here is a generated stub.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # FadeStickUSB_test.py import unittest from unittest import TestCase class TestFadeStickUSB(TestCase): def test_find_all_fade_sticks(self): self.fail() def test_find_fade_stick_by_serial(self): self.fail() def test__find_fade_sticks_as_generator(self): self.fail() def test__get_usbstring(self): self.fail() if __name__ == '__main__': unittest.main() |
We’ve discovered that the order of imports matters, and that the file name should not normally be the same as the class name (unlike in Java), or else the import may import the file, not the class in the file, by accident. This is more of a human error and happens in NodeJS as well. See below.
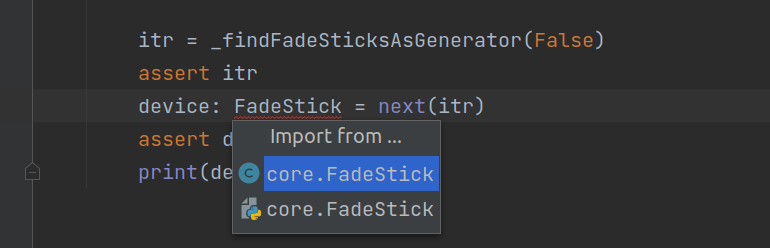
Alternatively, imports can be local, meaning we can import modules and methods in the middle of a class or function. This is so very odd coming from C++ and Java.
1 2 3 4 5 6 7 8 9 10 | def __init__(self, device=None, error_reporting=True): self.error_reporting = error_reporting if device: # Local imports are odd for a C++ and Java developer from core.FadeStickUSB import openUSBDevice, getUSBString self.device = device openUSBDevice(device) self.serial = getUSBString(device, FS_BYTE_INDEX) |
Another pattern to prevent circular imports due to type-hinting is to add the following at the beginning of a file (until it is enabled by default in Python 4). Why? Type hints are a fantastic addition to Python, but custom objects as type hints need to be resolved/imported, so that can lead to circular imports. Yikes.
1 2 | # Resolve type hints at runtime from __future__ import annotations |
Yet another pattern is to prevent offending imports due to type hinting until runtime with a bit of logic.
1 2 3 4 | import typing if typing.TYPE_CHECKING: # False at runtime import expensive_mod |
In Java, we throw specialized exceptions left and right to control flow. I suspect the Pythonic way is to return None. But, you know what? Personally, it feels clean and satisfying to throw a specialized exception with a helpful message than return None (null, in Java).
1 2 3 4 5 | # Return None if a FadeStick isn't found def findFirstFadeStick() -> FadeStick: device: Device = _findFadeSticksAsGenerator(False) if device: return FadeStick(device=device) |
The same as above, but with a helpful exception:
1 2 3 4 5 6 | def findFirstFadeStick() -> FadeStick: device: Device = _findFadeSticksAsGenerator(False) if device: return FadeStick(device=device) raise FadeStickUSBException("No FadeSticks found") |
Apparently, functions are not first-class citizens, so many code writers use guards and if-else statements to accept dynamic (non-typed or Any) parameters instead of writing polymorphic functions. My instinct is to write polymorphic methods/functions like this.
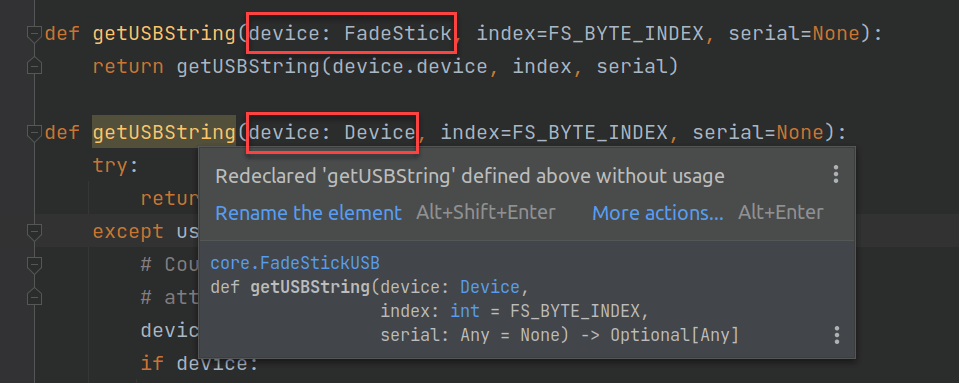
Let’s see if anyone else prefers to overload functions as well… and they do, sort of. Python uses decorators from community libraries to achieve @overload, @dispatch, @multimethod, and more. Here is a readable solution that works well for me using parameter types in the annotation.
1 2 3 4 5 6 7 8 | from multipledispatch import dispatch @dispatch(FadeStick, int) def getUSBString(fs: FadeStick, index: int, serial: str = None) -> str: return getUSBString(fs.device, index, serial) @dispatch(USBDevice, int) def getUSBString(device: USBDevice, index: int, serial: str = None) -> str: ... |
and
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from multipledispatch import dispatch class FadeStick(object): ... @dispatch(str) def setColor(self, name_or_hex: str) -> RGB: try: return self.setColor(hexToRGB(colorToHex(name_or_hex))) except FadeStickColorException: return self.setColor(hexToRGB(name_or_hex)) @dispatch(int, int, int) def setColor(self, red: int, green: int, blue: int) -> RGB: return self.setColor(RGB(red, green, blue)) @dispatch(RGB) def setColor(self, rgb: RGB) -> RGB: ... |
Yes, in Python, functions can float around a script outside a class, but the order of declaration matters. It feels like a .py file acts like a filename-based namespace for its functions.
It looks like we can instantiate a variable in a try-catch block (try-except in Python), and said variable is available outside the try block. This is auto-hoisting in JavaScript. This is personally worrisome, especially since JS introduced the let keyword to specifically to prevent auto-hoist-related bugs. Here is an example.
1 2 3 4 5 6 7 | try: hex_octets: Final = HEX_COLOR_RE.match(hex_str).groups()[0] # hex_octets is auto-hoisted except AttributeError: raise ValueError(f"'{hex_str}' is not a valid hexadecimal color value.") hex_lower = hex_octets.lower() # hex_octets was instantiated in a try-block return int(hex_lower[0:2], 16), int(hex_lower[0:2], 16), int(hex_lower[0:2], 16) |
Java uses annotations. Python uses decorators to modify method functionality that resembles Java annotations. Let’s make our own @disabled annotation (decorator) to mark Python unit tests as disabled.
1 2 3 4 5 6 | # Decorators.py # Copyright (c) Eric Draken, 2021. def disabled(f): def _decorator(self): print(f"{f.__name__} has been disabled") return _decorator |
Then in unit tests, we can disable tests easily with a custom message as well.
1 2 3 4 5 6 7 | class TestColors(TestCase): def test_color_to_hex(self): self.assertEqual("0x000000", colorToHex("black")) @disabled def test_hex_to_rgb(self): self.fail() |
Java has JUnit parameterized tests to use test values from files or some collection of input-expected pairs. Having just discovered lambdas exist in Python, and poring over the unit test framework source code, here is my first attempt at parameterized unit testing in Python with a lambda. We see that we need to bind outer variables to lambda parameters.
1 2 3 4 5 6 7 8 9 | def test_all_colors(self): suite = unittest.TestSuite() for h, c in [("0xff0000", "red"), ("0x00ff00", "green"), ("0x0000ff", "blue")]: suite.addTest( unittest.FunctionTestCase( lambda _h=h, _c=c: self.assertEqual(_h, colorToHex(_c)))) self.assertTrue(unittest.TextTestRunner().run(suite).wasSuccessful()) |
And the output is similar to this.
1 2 3 4 5 | ... ---------------------------------------------------------------------- Ran 3 tests in 0.000s OK |
Finally, Python has test class/method setup and teardown patterns too. For instance,
1 2 3 4 5 6 7 8 9 10 11 12 13 | class TestFadeStick(TestCase): device: FadeStick @classmethod def setUpClass(cls) -> None: super().setUpClass() cls.device = findFirstFadeStick() @classmethod def tearDownClass(cls) -> None: super().tearDownClass() if cls.device: cls.device.turnOff() |
Let’s move on to the next goal now that we can write unit tests effectively in Python.
Goal 3: Run all Unit Tests Everywhere in PyCharm
PyCharm isn’t like IntelliJ IDEA Pro where there is a convenient green arrow button to run all JUnit tests in all folders. From research, unless all the test files are in the same folder, PyCharm will not test them all as a suite.
In PyCharm, one cannot simply left-click on the project root folder and hope the “run tests” button will appear in the context menu.
We could drop to the shell and execute the unit tests with a recursive search pattern, but then we lose the satisfying visual green bar that grows across the IDE showing us all our tests have passed.
Let’s try something cool: let’s write a script to symlink and synchronize tests throughout the project to a git-ignored tests folder in which we can run all the tests in one go. The result looks like the following.
Each time the following script is run, the previous symlinks are cleared and new symlinks are created to keep tests in sync. Here is the script in the project root.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | # {project_root}/symlink_tests.py # Copyright (c) Eric Draken, 2021. import os import sys from pathlib import Path from typing import Final TESTS_FOLDER: Final = "tests" TEST_PATTERN: Final = "*_test.py" if sys.platform == "win32": raise NotImplementedError("Windows is not supported") def symlink_tests(): project_root: str = os.path.dirname(os.path.abspath(__file__)) # Sanity check that we are in the project root if not {"requirements.txt", TESTS_FOLDER, "utils", "core"} <= set(os.listdir(project_root)): raise FileNotFoundError(f"Make sure this is script is run in the project root folder: {project_root}") # Remove all test file symlinks test_folder: Path = Path(os.path.abspath(os.path.join(project_root, TESTS_FOLDER))) for path in test_folder.rglob(TEST_PATTERN): if path.is_symlink(): path.unlink(True) print(f"Unlinked {path}") # Find test files, create new symlinks, prevent infinite loops for src in Path(project_root).rglob(TEST_PATTERN): if src.parent != test_folder: dest: Path = test_folder.joinpath(src.name) dest.symlink_to(src, False) print(f"Symlinked {TESTS_FOLDER}/{dest.name} --> {src}") if __name__ == "__main__": symlink_tests() |
We can now run all tests in one click in PyCharm.
Goal 4: Issue USB Color Animation Commands
The next goal is to make the LED change simple colors.
There is no ternary operator (? or ?:), so the following causes several syntax errors.
1 2 3 | rgb = RGB(device_bytes[1], device_bytes[2], device_bytes[3]) return self.inverse ? invertRGB(rgb) : rgb # Many syntax errors |
The Python way to write a similar ternary statement is:
1 2 3 4 5 6 | def getColor(self): from core.FadeStickUSB import sendControlTransfer device_bytes = sendControlTransfer(self, 0x80 | 0x20, 0x1, 0x0001, 0, 33) rgb = RGB(device_bytes[1], device_bytes[2], device_bytes[3]) return invertRGB(rgb) if self.inverse else rgb # Valid syntax |
Lambdas in Python can be used to postpone the execution of a method. Consider the following.
1 2 3 4 5 6 7 8 9 10 11 | list = [print("A"), print("B")] # A # B list2 = [lambda: print("C"), lambda: print("D")] # No output for λ in list2: λ() # C # D |
Since Python 3.8 (Oct 2019), we can actually instantiate temporary variables with := by enclosing the lambda in a tuple () and making each statement an entry in said tuple. Also, the lambda has to be of the form () -> None, so PyCharm warns about returning a tuple from the lambda. Also, local variables need to be bound – do not try to use a local variable directly in the lambda.
It feels like a hack to use a tuple to execute code in a lambda, but here is the most Java-like lambda I could make to test some colors.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | def test_try_all_colors(self): from utils.Colors import COLOR_DICT suite = unittest.TestSuite() for k in COLOR_DICT.keys(): suite.addTest( unittest.FunctionTestCase( # Using 'None if' because lambdas are () -> None # Bind color to local variable k lambda color=k: None if ( self.log.info(f"Testing color {color}"), setRGB := self.device.setColor(color), getRGB := self.device.getColor(), self.assertEqual(setRGB, getRGB, f"Testing color {color}"), time.sleep(0.2) # Pleasing delay to see the colors ) else None) ) self.assertTrue(unittest.TextTestRunner().run(suite).wasSuccessful()) |
Let’s use an RGB class that holds red, green, blue as integers, is immutable, and has in-built validation. We could use a class with an __init__ method and some Final type-hints, but let’s take this opportunity to write an immutable named tuple called RGB.
1 2 3 4 | class RGB(NamedTuple): red: int green: int blue: int |
The above worked great for a while until I wanted to add validation and unit test the above tuple. It then became the following because NamedTuple isn’t actually a class; it’s a function.
1 2 3 4 5 6 7 8 9 10 11 | class RGB(NamedTuple("RGB", [("red", int), ("green", int), ("blue", int)])): def __new__(cls, red, green, blue): if not all([ 0 <= red <= 255, 0 <= green <= 255, 0 <= blue <= 255, ]): raise FadeStickColorException(f"One ore more colors are " f"below 0 or above 255. Given {red}, {green}, {blue}.") # noinspection PyArgumentList return super().__new__(cls, int(red), int(green), int(blue)) |
Implement Original BlinkStick Methods
Instead of copying the original, verbose, Python 2 BlinkStick code, let’s rewrite it more simply with type hinting. For compatibility, let’s make a BlinkStick class that inherits from FadeStick to keep the CPU-sleep animation logic separate from the FadeStick code. Here we go.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | class BlinkStick(FadeStick): def __init__(self, fs: FadeStick = None): super().__init__(fs.device) # Original blink logic that slows the CPU def blink(self, color: RGB, repeats: int = 1, delay: int = 500): assert repeats > 0 assert delay > 0 ms_delay = float(delay) / float(1000) for x in range(repeats): if x: time.sleep(ms_delay) self.setColor(color) time.sleep(ms_delay) self.turnOff() # Original morph logic that slows the CPU def morph(self, end_color: RGB, duration: int = 1000, steps: int = 50): assert steps > 0 assert duration > 0 r_end, g_end, b_end = end_color start_color = self.getColor() r_start, g_start, b_start = start_color gradient: List[RGB] = [] steps += 1 for n in range(1, steps): d = 1.0 * n / steps r = (r_start * (1 - d)) + (r_end * d) g = (g_start * (1 - d)) + (g_end * d) b = (b_start * (1 - d)) + (b_end * d) gradient.append(RGB(r, g, b)) ms_delay = float(duration) / float(1000 * steps) self.setColor(start_color) for grad in gradient: self.setColor(grad) time.sleep(ms_delay) self.setColor(end_color) # Original pulse logic that slows the CPU def pulse(self, color: RGB, pulses: int = 1, duration: int = 1000, steps: int = 50): assert pulses > 0 assert steps > 0 assert duration > 0 self.turnOff() for x in range(pulses): self.morph(color, duration=duration, steps=steps) self.morph(RGB(0, 0, 0), duration=duration, steps=steps) |
The original code has been re-written and condensed into the above lines.
Unlike, say, SpringBoot annotations (e.g. @Max(255), @NotEmpty), Python doesn’t have parameter validation annotations or decorations. We could always use interval evaluations, but they would be needed for each parameter in each method. Can we do better?
Until I know better, I rolled my own int class (with unit tests) that allows for some range logic and helpful exceptions. Since everything in Python is an object, class RangeInt(int): is a valid construct, quite unlike Java.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | class RangeInt(int): def __init__(self, val: int, min: int, max: int, nice_name: str) -> None: self._min: int = min self._max: int = max self._nice_name: str = nice_name self._val: Final[int] = val def __new__(cls, *value): _val = int(value[0]) _min = int(value[1]) _max = int(value[2]) _nice_name = str(value[3]) if not _min < _max: raise RangeIntException(f"{_nice_name} has " f"a bad range [{_min}..{_max}]: {_val}") if not _min <= _val <= _max: raise RangeIntException(f"{_nice_name} is " f"out of range [{_min}..{_max}]: {_val}") return int.__new__(cls, _val) ... |
Then we can do something like Java’s val = Objects.assertNotNull(val) in Python.
1 2 3 4 5 6 7 8 9 10 | # Original pulse logic that slows the CPU def pulse(self, color: RGB, pulses: int = 1, duration: int = 1000, steps: int = 50): pulses = RangeInt(pulses, 1, 100, "pulses") duration = RangeInt(duration, 1, 5000, "duration") steps = RangeInt(steps, 1, 100, "steps") self.turnOff() for x in range(pulses): self.morph(color, duration=duration, steps=steps) self.morph(RGB(0, 0, 0), duration=duration, steps=steps) |
Implement New FadeStick Methods
Because we don’t want BlinkStick and FadeStick to share the same methods, it would be nice to implement some abstract methods in a base class I will call FadeStickBase.
Right away we see that Python doesn’t support abstract methods, so the following, while incomplete, permits the given class to be instantiated.
1 2 3 | def blink(self, color: RGB, blinks: int = 1, delay: int = 500): ... def morph(self, end_color: RGB, duration: int = 1000, steps: int = 50): ... def pulse(self, color: RGB, pulses: int = 1, duration: int = 1000, steps: int = 50): ... |
I’m told the Pythonic way to achieve abstract methods is the following:
1 2 3 | class BaseClass(): def someMethod(self): raise NotImplementedError("Extend this base class") |
However, coming from SpringBoot and desiring the base class to not be instantiated due to the “abstract” methods, the following does the trick.
1 2 3 4 5 6 7 8 9 10 | class FadeStickBase(object, metaclass=ABCMeta): # Notice the metaclass @abstractmethod # Notice the annotation def blink(self, color: RGB, blinks: int = 1, delay: int = 500): ... @abstractmethod def morph(self, end_color: RGB, duration: int = 1000, steps: int = 50): ... @abstractmethod def pulse(self, color: RGB, pulses: int = 1, duration: int = 1000, steps: int = 50): ... |
We can now go ahead and split BlinkStick and FadeStick into classes inheriting from FadeStickBase with mutually exclusive LED methods.
However, not yet being satisfied, here is the technique I will actually use going forward to get the best of both worlds: an @abstract annotation that raises Pythonic exceptions. As a bonus, the method name that caused the exception is in the message.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # Decorators.py def abstract(f): def _decorator(*_): # _ means ignore the parameter(s) raise NotImplementedError(f"Method '{f.__name__}' is abstract") return _decorator # FadeStickBase.py class FadeStickBase(object): @abstract def blink(self, color: RGB, blinks: int = 1, delay: int = 500): ... # FadeStickBase_test.py class TestFadeStickBase(TestCase): def test_abstract(self): with self.assertRaises(NotImplementedError) as m: cls = FadeStickBase() cls.blink(RGB(0, 0, 0)) self.assertIn("Method 'blink' is abstract", str(m.exception)) |
Let’s implement (read: override) those abstract methods according to the Java counterpart.
x++ and ++x work as expected?Given the following sample code, you may be surprised to discover that the ++i doesn’t increment i and the 0th array entry is repeatedly updated.
1 2 3 4 5 6 7 8 9 10 11 12 | def getIntPattern(self) -> List[int]: data: List[int] = [0] * self.PATTERN_BUFFER_BYTE_LENGTH i = 0 data[i] = len(self._pattern) for p in self._pattern: data[++i] = p.color.red data[++i] = p.color.green data[++i] = p.color.blue data[++i] = round(p.duration / self.DURATION_RESOLUTION) return data[:] |
Why? There is no unary increment operator in Python. In Python, ++i == i the same way +1 = 1, so ++1 == 1. Rats. Here is a workaround using enumerate to also get the ith position.
1 2 3 4 5 6 7 8 9 10 11 12 | def getIntPattern(self) -> List[int]: data: List[int] = [0] * self.PATTERN_BUFFER_BYTE_LENGTH data[0] = len(self._pattern) for i, p in enumerate(self._pattern): data[(i*4)+1:(i*4)+5] = [ p.color.red, p.color.green, p.color.blue, round(p.duration / self.DURATION_RESOLUTION) ] return data[:] |
The new FadeStick asynchronous pattern methods become thusly:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | def blink(self, color: RGB, blinks: int = 1, delay_ms: int = 500) -> None: blinks = RangeInt(blinks, 1, self.MAX_BLINKS, "blinks") delay_ms = RangeInt(delay_ms, 1, self.MAX_DELAY, "delay_ms") pattern = Pattern() for x in range(blinks): if x: pattern.addColorAndDuration(OFF, delay_ms) pattern.addColorAndDuration(color, delay_ms) pattern.addColorAndDuration(OFF, 0) from core.FadeStickUSB import sendControlTransfer, R_USB_SEND, R_SET_CONFIG sendControlTransfer(self, R_USB_SEND, R_SET_CONFIG, FS_MODE_PATTERN, pattern.getBytePattern()) # noinspection DuplicatedCode def morph(self, end_color: RGB, duration: int = 1000, steps: int = MAX_STEPS) -> None: duration = RangeInt(duration, 1, self.MAX_DURATION, "duration") steps = RangeInt(steps, 1, self.MAX_STEPS, "steps") r_end, g_end, b_end = end_color start_color = self.getColor() r_start, g_start, b_start = start_color pattern: Pattern = Pattern() ms_delay = floor(float(duration) / float(steps)) for n in range(0, steps): # Range is exclusive d = 1.0 * (n + 1) / float(steps) r = (r_start * (1 - d)) + (r_end * d) g = (g_start * (1 - d)) + (g_end * d) b = (b_start * (1 - d)) + (b_end * d) pattern.addColorAndDuration(RGB(r, g, b), ms_delay) from core.FadeStickUSB import sendControlTransfer, R_USB_SEND, R_SET_CONFIG sendControlTransfer(self, R_USB_SEND, R_SET_CONFIG, FS_MODE_PATTERN, pattern.getBytePattern()) |
Goal 5: Interrogate the CPU
In Linux, we can query the processing time of the CPU from /proc/stat directly without a third-party module like psutil or a program like htop. One caveat is that /proc/stat returns the processing time presumably since boot, not the near-instantaneous CPU time we need. A wonderful solution on StackOverflow led to the strategy of checking the CPU times (processing and idle) periodically and calculating the CPU use percent during a given slice.
1 2 3 4 5 6 7 8 9 10 | $ cat /proc/stat | head -1 cpu 2836105 61 1678375 202352050 11139 0 52788 0 0 0 $ cat /proc/stat | head -1 cpu 2836276 61 1678397 202353321 11139 0 52788 0 0 0 $ cat /proc/stat | head -1 cpu 2836356 61 1678408 202353920 11139 0 52788 0 0 0 $ cat /proc/stat | head -1 cpu 2836598 61 1678440 202355724 11140 0 52794 0 0 0 $ cat /proc/stat | head -1 cpu 2836849 61 1678473 202357621 11140 0 52795 0 0 0 |
Then, by performing the above cat programmatically in a loop, with a bit of math and string formatting we can see something resembling the following:
1 2 3 4 5 6 | CPU 2.19% CPU 2.79% CPU 1.90% CPU 3.98% CPU 17.95% CPU 1.52% |
An infinite loop with a sleep command to drive the LED color is a nice demo. Let’s use stress-ng to simulate a very high load on the CPU and show just the htop bars with htop -u nobody.
1 2 | # Use all the cores, full-blast, for 10s sudo stress-ng --cpu 8 --timeout 10 |
Here is the result.
Goal 6: Write a Daemon in Python
Can we write daemons in Python agnostic of Systemd and BusyBox, and without backgrounding a do-wait-while script that may generate CPU soft-lock warnings? It turns out we can. Here is a short proof-of-concept that spawns a singleton daemon, so if this same script is called repeatedly, only one daemon will be spawned.
1 2 3 4 5 6 7 8 9 10 11 12 | from daemonize import Daemonize def main(): ... if __name__ == '__main__': script_path = str(os.path.dirname(os.path.abspath(__file__))) # Script folder sha1 = hashlib.sha1(script_path.encode("utf-8")).hexdigest() # Unique ID of script app_name = f"cpufadestick-{sha1}" pidfile = f"/tmp/{app_name}" print(pidfile) daemon = Daemonize(app=app_name, pid=pidfile, action=main) # Only one daemon will run daemon.start() |
This is a nice toy example, but if this is going to be robust, let’s use the defacto standard library python-daemon. Why? We need signal handling to communicate with the daemon (e.g. stop, restart), as well as have the daemon log to Syslog. You’d be forgiven for thinking debugging a daemon (detached process – the PyCharm debugger won’t follow it) is easy, so we need Syslog.
When os.fork() is executed and the main thread terminates, logging pipes are closed so the daemon is in Plato’s cave. With a bit of fancy coding, we can keep those file descriptors open as follows.
Preserve the Logger in the Daemon
Here is a way that works to preserve the logging to Syslog and Stdout (just the main thread). I only post this here because it took a while with trial and error to engineer a solution if it helps anyone.
First, here is the logging setup. The trick which is important later is to attach the Syslog handler to the root logger and then create a named logger daemon. This is due to what variables survive a fork, and the root logger does.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | class CPUDaemon: # Log to /var/log/syslog _syslog_handler: Final = SysLogHandler( facility=SysLogHandler.LOG_DAEMON, address="/dev/log") _syslog_handler.setLevel(logging.INFO) # Console logging _console_handler: Final = StreamHandler(sys.stdout) _console_handler.setLevel(logging.WARNING) # noinspection PyArgumentList logging.basicConfig( level=logging.INFO, format="%(asctime)s [%(name)s] [%(levelname)s] %(message)s", handlers=[_syslog_handler] ) _main_log: Final = logging.getLogger("main") _main_log.addHandler(_console_handler) _daemon_log: Final = logging.getLogger("daemon") |
Next, we have to tell the daemon context to keep the Syslog socket open on fork.
1 2 3 4 5 6 7 8 9 10 | def _get_context(self) -> daemon.DaemonContext: """Return a daemon context to use with 'with'""" return daemon.DaemonContext( pidfile=pidfile.PIDLockFile(self._pidpath), stdout=sys.stdout, stderr=sys.stderr, detach_process=True, files_preserve=[self._syslog_handler.socket.fileno()], # Returns a number like '3' ) |
Now the daemon can log to /var/log/syslog.
Starting the Daemon
With a daemon context available, we can start the daemon process like so:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | def start(self): if os.path.exists(self.pidpath): self.main_log.info(f"Daemon already running according to {self.pidpath}.") return self.main_log.info("Daemon start requested") with self.getContext(): # We're in the daemon context, the main thread has gone away. # Logging pipes are still open. self.daemon_log.info("Daemon started") for _ in range(3): self.daemon_log.info("Hi, there") time.sleep(1) |
The output from the starting the daemon then looks like the following.
Console
1 2 3 4 | /home/build/PycharmProjects/CPUFadeStick/venv/bin/python /home/build/PycharmProjects/CPUFadeStick/main.py start 2021-05-04 13:43:42,269 [main] [INFO] Daemon start requested Process finished with exit code 0 |
Syslog
Using tail -F /var/log/syslog:
1 2 3 4 5 | May 4 13:43:42 buildtools 2021-05-04 13:43:42,269 [main] [INFO] Daemon start requested May 4 13:43:43 buildtools 2021-05-04 13:43:43,066 [daemon] [INFO] Daemon started May 4 13:43:43 buildtools 2021-05-04 13:43:43,066 [daemon] [INFO] Hi, there May 4 13:43:44 buildtools 2021-05-04 13:43:44,069 [daemon] [INFO] Hi, there May 4 13:43:45 buildtools 2021-05-04 13:43:45,071 [daemon] [INFO] Hi, there |
Stopping the Daemon
How to stop a detached process that is running on its own? Should we ps aux | grep pytho[n], find the zombie PID, and kill -9 ${PID}? We can be more sophisticated and graceful with stopping (and restarting) our daemon: send a signal programmatically.
1 2 3 4 5 6 7 8 9 | def stop(self): # Error handling omitted for brevity self._main_log.info("Daemon stop requested") ctx = self._get_context() pidf: pidfile.PIDLockFile = ctx.pidfile # The daemon PID was written to disk by the context pid = pidf.read_pid() self._main_log.debug(f"Sending {signal.SIGINT.name} to PID {pid}") os.kill(pid, signal.SIGINT) # <-- Send an interrupt signal |
Then how does the daemon catch the signal? Back to the context method, we can pass in a signal map so a prescribed method in the daemon runs on a given signal.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | def _get_context(self) -> daemon.DaemonContext: """Return a daemon context to use with 'with'""" return daemon.DaemonContext( pidfile=pidfile.PIDLockFile(self._pidpath), stdout=sys.stdout, stderr=sys.stderr, detach_process=True, files_preserve=get_log_file_handles(self._daemon_log), signal_map={ signal.SIGTERM: self._end, signal.SIGTSTP: self._end, signal.SIGINT: self._end, # <-- This method will run } ) |
When the _end() method runs, let’s toggle some flag that ends a while-true loop so the daemon then gracefully terminates.
1 2 3 | def _end(self, signum: int, _frame=None): self._daemon_log.debug(f"Daemon received {signal.Signals(signum).name}") self._is_running = False |
_run() and _end() code from the first time it was forked.Goal 7: Package the App into a Standalone Executable
As it stands, we have three modules we imported in requirements.txt. Are these the only external requirements?
1 2 3 | pyusb~=1.1.1 multipledispatch~=0.6.0 daemonize~=2.5.0 |
There some suggestions from the community: PyInstaller and Nuitka.
PyInstaller
Let’s give PyInstaller a shot from the PyCharm terminal.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | (venv) ~/PycharmProjects/CPUFadeStick$ ./venv/bin/pyinstaller -F -n cpufadestick main.py 32 INFO: PyInstaller: 4.3 32 INFO: Python: 3.8.5 40 INFO: Platform: Linux-5.4.0-62-generic-x86_64-with-glibc2.29 40 INFO: wrote /home/build/PycharmProjects/CPUFadeStick/cpufadestick.spec 42 INFO: UPX is not available. 43 INFO: Extending PYTHONPATH with paths ... (venv) ~/PycharmProjects/CPUFadeStick$ cd dist (venv) ~/PycharmProjects/CPUFadeStick/dist$ ls -lh total 6.8M -rwxr-xr-x 1 build build 6.8M Apr 30 19:53 cpufadestick (venv) ~/PycharmProjects/CPUFadeStick/dist$ file cpufadestick cpufadestick: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=24675b0091f38f45c5c1c5484cf24925b439b164, stripped |
We can see that a 6.8 MB 64-bit ELF executable was generated. The moment of truth is here. Let’s execute the daemon.
1 2 3 4 5 | (venv) ~/PycharmProjects/CPUFadeStick/dist$ ./cpufadestick /tmp/cpufadestick-dcf635f560e0b5568f4658fb8cda2efd7412518b (venv) ~/PycharmProjects/CPUFadeStick/dist$ ./cpufadestick /tmp/cpufadestick-d02e0e2baa49f5b982a93377e8d914488e06e8ef (venv) ~/PycharmProjects/CPUFadeStick/dist$ ./cpufadestick |
Nothing happens and the folder SHA1 changes between invocations. Let’s figure out why the SHA1 changes with some debug messages.
1 2 3 4 5 6 | (venv) ~/PycharmProjects/CPUFadeStick$ ./dist/cpufadestick /tmp/_MEIlJuKuV /tmp/cpufadestick-d8731af64a79b3546ffc429e0a6c9f3b581d7d83 (venv) ~/PycharmProjects/CPUFadeStick$ ./dist/cpufadestick /tmp/_MEIoegVP6 /tmp/cpufadestick-ca87662c3f5f85406f7f9b72866bafd52f63fb6b |
Ah, venv is using temp folders per execution. Let’s consult Syslog next with tail -f /var/log/syslog:
1 2 3 4 5 6 7 8 9 10 | Apr 30 20:01:25 build cpufadestick-26..: Starting daemon. Apr 30 20:01:25 build cpufadestick-26..: Traceback (most recent call last): Apr 30 20:01:25 build cpufadestick-26..: File "daemonize.py", line 248, in start Apr 30 20:01:25 build cpufadestick-26..: File "main.py", line 22, in main Apr 30 20:01:25 build cpufadestick-26..: File "core/FadeStickUSB.py", line 53, in findFirstFadeStick Apr 30 20:01:25 build cpufadestick-26..: File "core/FadeStickUSB.py", line 75, in _findFadeSticksAsGenerator Apr 30 20:01:25 build cpufadestick-26..: File "usb/core.py", line 1299, in find Apr 30 20:01:25 build cpufadestick-26..: usb.core.NoBackendError: No backend available Apr 30 20:01:25 build cpufadestick-26..: Apr 30 20:01:25 build cpufadestick-26..: Stopping daemon. |
Darn. We’re having USB problems too. Let’s execute the standalone binary in a system shell outside of PyCharm and check the Syslog.
1 2 3 4 5 6 7 8 9 10 | Apr 30 20:16:02 build cpufadestick-b1..: File "<frozen importlib._bootstrap_external>", line 1316, in _get_spec Apr 30 20:16:02 build cpufadestick-b1..: File "<frozen importlib._bootstrap_external>", line 1297, in _legacy_get_spec Apr 30 20:16:02 build cpufadestick-b1..: File "<frozen importlib._bootstrap>", line 414, in spec_from_loader Apr 30 20:16:02 build cpufadestick-b1..: File "<frozen importlib._bootstrap_external>", line 649, in spec_from_file_location Apr 30 20:16:02 build cpufadestick-b1..: File "<frozen zipimport>", line 191, in get_filename Apr 30 20:16:02 build cpufadestick-b1..: File "<frozen zipimport>", line 709, in _get_module_code Apr 30 20:16:02 build cpufadestick-b1..: File "<frozen zipimport>", line 536, in _get_data Apr 30 20:16:02 build cpufadestick-b1..: FileNotFoundError: [Errno 2] No such file or directory: '/tmp/_MEIY6osMZ/base_library.zip' Apr 30 20:16:02 build cpufadestick-b1..: Apr 30 20:16:02 build cpufadestick-b1..: Stopping daemon. |
I’m less than enamored with PyInstaller. Let’s explore Nuitka next.
Nuitka
Docker in Linux integrates very well in JetBrains products, so let’s have some fun making a Nuitka, Cython, and AppImage build pipeline to compile a standalone executable as a new Python+Docker skill.
fuse, which is a deal-breaker for Docker projects.After safely sidestepping the no-fuse-in-Docker issue (without elevating permissions), and reverse-engineering the hidden requirements to make this Dockerized tool run, we’ve made progress. Here are the issues we overcame:
- Fuse is needed in Docker
- An icon in XPM format is required
- The
filecommand is required - Run Python and Pip as a non-root user
When built, the main executable in the resulting AppDir folder of libraries runs perfectly, but the AppImage standalone binary doesn’t. Let’s visit syslog.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | May 1 11:29:55 buildtools cpufadestick: Starting daemon. May 1 11:29:55 build systemd[1]: tmp-.mount_cpufadIiJcP9.mount: Succeeded. May 1 11:29:55 build systemd[938]: tmp-.mount_cpufadIiJcP9.mount: Succeeded. May 1 11:29:55 build cpufadestick: Traceback (most recent call last): May 1 11:29:55 build cpufadestick: File "/tmp/.mount_cpufadIiJcP9/daemonize.py", line 248, in start May 1 11:29:55 build cpufadestick: File "/tmp/.mount_cpufadIiJcP9/main.py", line 22, in main May 1 11:29:55 build cpufadestick: File "/tmp/.mount_cpufadIiJcP9/core/FadeStickUSB.py", line 53, in findFirstFadeStick May 1 11:29:55 build cpufadestick: File "/tmp/.mount_cpufadIiJcP9/core/FadeStickUSB.py", line 75, in _findFadeSticksAsGenerator May 1 11:29:55 build cpufadestick: File "/tmp/.mount_cpufadIiJcP9/usb/core.py", line 1289, in find May 1 11:29:55 build cpufadestick: File "/tmp/.mount_cpufadIiJcP9/usb/backend/libusb1.py", line 41, in <module usb.backend.libusb1> May 1 11:29:55 build cpufadestick: File "/tmp/.mount_cpufadIiJcP9/usb/libloader.py", line 34, in <module usb.libloader> May 1 11:29:55 build cpufadestick: File "/tmp/.mount_cpufadIiJcP9/ctypes/util.py", line 3, in <module> May 1 11:29:55 build cpufadestick: File "/tmp/.mount_cpufadIiJcP9/subprocess.py", line 69, in <module> May 1 11:29:55 build cpufadestick: ImportError: /tmp/.mount_cpufadIiJcP9/_posixsubprocess.so: cannot open shared object file: No such file or directory May 1 11:29:55 build cpufadestick: May 1 11:29:55 build cpufadestick: Stopping daemon. |
No idea. We need to timebox this. Let’s import _posixsubprocess explicitly and move on.
1 2 3 4 5 6 | ... May 1 11:51:21 build cpufadestick: File "/tmp/.mount_cpufadpzNeMC/tempfile.py", line 45, in <module> May 1 11:51:21 build cpufadestick: File "/tmp/.mount_cpufadpzNeMC/random.py", line 54, in <module> May 1 11:51:21 build cpufadestick: ImportError: cannot import name 'sha512' from 'hashlib' (/tmp/.mount_cpufadpzNeMC/hashlib.py) May 1 11:51:21 build cpufadestick: May 1 11:51:21 build cpufadestick: Stopping daemon. |
This goes on a few more times until these manual imports are added.
1 2 3 4 5 6 7 8 9 | if __name__ == '__main__': app_name = f"cpufadestick" pidfile = f"/tmp/{app_name}" # Do NOT remove the following lines import _posixsubprocess import hashlib import _random daemon = Daemonize(app=app_name, pid=pidfile, action=main) daemon.start() |
Run. Failure. Syslog again.
1 2 3 4 5 6 | May 1 12:50:09 build cpufadestick: Starting daemon. May 1 12:50:09 build systemd[1]: tmp-.mount_cpufadS1PPIj.mount: Succeeded. May 1 12:50:09 build systemd[938]: tmp-.mount_cpufadS1PPIj.mount: Succeeded. May 1 12:50:09 build systemd[1]: Started Process Core Dump (PID 12097/UID 0). May 1 12:50:10 build systemd-coredump[12098]: Process 12095 (main) of user 1000 dumped core.#012#012Stack trace of thread 12095:#012#0 0x000056380a37237f n/a (/main + 0x11837f) May 1 12:50:10 build systemd[1]: systemd-coredump@2-12097-0.service: Succeeded. |
This is getting silly and points to a systemic problem. Actually, these libraries _posixsubprocess.so, _hashlib.so, etc. are present in the Nuitka build folder. Strange. Here is a Hail Mary pass with --appimage-extract-and-run:
1 2 3 4 5 6 | ~/PycharmProjects/CPUFadeStick/build$ ./cpufadestick --appimage-extract-and-run /tmp/appimage_extracted_f076c020893e8e2c5e3a9c6869e3bb10/.DirIcon /tmp/appimage_extracted_f076c020893e8e2c5e3a9c6869e3bb10/AppRun /tmp/appimage_extracted_f076c020893e8e2c5e3a9c6869e3bb10/_asyncio.so /tmp/appimage_extracted_f076c020893e8e2c5e3a9c6869e3bb10/_bisect.so ... |
And, it works! This must be either a fuse issue, or some issue with AppImageKit running in a Docker container. Good enough for now so we can move on. Below is a demo of the problem and the workaround.
One small note: With the extracted libraries this small daemon expands from 9MB to 25MB on disk.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | $ ls -alhSGg total 24M -rwxr-xr-x 1 9.4M May 1 10:20 main -rw-r--r-- 1 3.5M May 1 10:20 libpython3.8.so.1.0 -rw-r--r-- 1 2.9M May 1 10:20 libcrypto.so.1.1 <-- Yikes, 2.9MB? -rw-r--r-- 1 1.2M May 1 10:20 libsqlite3.so.0 <-- We're not using SQLite. Odd. -rw-r--r-- 1 1.1M May 1 10:20 unicodedata.so <-- It's all ASCII, though. -rw-r--r-- 1 580K May 1 10:20 libssl.so.1.1 <-- No networking at all, though. -rw-r--r-- 1 376K May 1 10:20 _decimal.so -rw-r--r-- 1 302K May 1 10:20 libreadline.so.7 -rw-r--r-- 1 267K May 1 10:20 _codecs_jp.so <-- Why are there CJK codecs? -rw-r--r-- 1 239K May 1 10:20 libexpat.so.1 -rw-r--r-- 1 226K May 1 10:20 libncursesw.so.6 -rw-r--r-- 1 180K May 1 10:20 libtinfo.so.6 -rw-r--r-- 1 174K May 1 10:20 _ssl.so ... |
Nuitka, Cython, AppImageKit Dockerfile
Here is the Dockerfile that powered the previous section. Bind your work folder to /workdir and change your uid:gid if they are not both 1000.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | # Nuitka Docker pipeline. Copywrite Eric Draken, 2021 FROM python:3.8-slim AS nuitkabuilder RUN apt-get update &&\ apt-get install -y \ curl build-essential ccache libfuse2 file # Note, fuse isn't needed, but some prerequisite logic checks for it # file is needed if ARCH isn't set # See: https://github.com/AppImage/AppImageKit/blob/8bbf694455d00f48d835f56afaa1dabcd9178ba6/src/appimagetool.c#L726 RUN pip3 install --no-cache-dir Cython nuitka FROM nuitkabuilder ARG user=nuitka ARG group=nuitka ARG uid=1000 ARG gid=1000 RUN groupadd -g ${gid} ${group} &&\ useradd -rm -d /home/${user} -s /bin/sh -g ${group} -u ${uid} ${user} USER nuitka WORKDIR /workdir ARG APPIMAGE=/home/${user}/.local/share/Nuitka/appimagetool-x86_64.AppImage/x86_64/12/appimagetool-x86_64.AppImage RUN curl -L \ https://github.com/AppImage/AppImageKit/releases/download/12/appimagetool-x86_64.AppImage \ -o ${APPIMAGE} \ --create-dirs &&\ chmod +x ${APPIMAGE} # Avoid the whole Fuse-Docker fiasco # REF: https://docs.appimage.org/user-guide/troubleshooting/fuse.html # REF: https://github.com/AppImage/AppImageKit/issues/912 ENV APPIMAGE_EXTRACT_AND_RUN=1 ENV NO_CLEANUP=1 # Run once for the cache effect RUN /home/${user}/.local/share/Nuitka/appimagetool-x86_64.AppImage/x86_64/12/appimagetool-x86_64.AppImage -h # Find some random XPM from the web COPY icon.xpm / CMD pip3 install --user -r requirements.txt &&\ python3 -m nuitka \ --follow-imports \ --standalone \ --onefile \ --show-progress \ --lto \ --linux-onefile-icon=/icon.xpm \ --output-dir=build \ # --remove-output \ --assume-yes-for-downloads \ main.py &&\ mv build/main.bin cpufadestick &&\ file cpufadestick &&\ echo "Success!" |
Results
With the background of a Java developer learning Python for the first time and an ambitious project in mind, in a few days, we learned how to set up PyCharm, type-hint, write unit tests to ensure correctness throughout, interact with the USB bus, write a system daemon, make a build pipeline in Docker directly in PyCharm, and deliver a portable binary to display a morphing color corresponding to the load of all the CPUs. Here is the source code.
Bonus: Automatic Code Formatting on File Save
Want to collaborate well with others? Want to follow 2001’s PEP 8 coding style for Python and make (keep) programming friends? Pressing ctrl+a (select all), ctrl+alt+l (reformat), and then ctrl+alt+o (optimize imports) works. However, with either PyCharm and the BlackConnect (plus blackd) or Save Actions plugin, you can do just that automatically. Here are the steps:
Bonus: Inter-Process Communication (IPC)
Let’s see what our daemon is up to. How is the CPU load now? Is it even running? Is the FadeStick plugged in? Let’s ask it.
Inter-process communication (IPC) is super simple a concept as it is, but let’s see if Python makes it easy to implement: we just need a named pipe and a lot of error handling.
This code sends a SIGUSR1 signal to the daemon similar to how we sent a SIGINT to ask it to terminate. It then polls a named pipe (which is just an ordinary file on disk with special attributes), and times out after five seconds if no reply is received (crashed daemon?).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | def status(self) -> str: self._main_log.info("Daemon status requested") pid = self._get_context().pidfile.read_pid() if not pid: return "Daemon not running." # Create the named pipe try: try: os.mkfifo(self._named_pipe) self._main_log.debug("Creating named IPC pipe") except FileExistsError: self._main_log.debug("IPC pipe already exists") pass # Open the pipe in non-blocking mode for reading pipe = os.open(self._named_pipe, os.O_RDONLY | os.O_NONBLOCK) self._main_log.debug("Opened IPC pipe") try: # Trigger the daemon to place a message in the queue self._main_log.debug(f"Sending {signal.SIGUSR1.name} to PID {pid}") os.kill(pid, signal.SIGUSR1) self._main_log.debug(f"Waiting for reply") # Create a polling object to monitor the pipe for new data poll = select.poll() poll.register(pipe, select.POLLIN) try: # Check if there's data to read. Timeout after 5 sec. self._main_log.debug("Starting IPC poll") if (pipe, select.POLLIN) in poll.poll(5000): return get_message(pipe) else: self._main_log.error("Daemon did not respond in time.") finally: poll.unregister(pipe) finally: os.close(pipe) finally: os.remove(self._named_pipe) self._main_log.debug("Finished status request") |
The daemon, registered for SIGUSR1, writes its status (just a string of text, but we could serialize (pickle) anything) to the named pipe and does not block.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | def _status(self, signum: int, _frame=None): self._daemon_log.debug(f"Daemon received {signal.Signals(signum).name}") try: with self._lock: if not self._fs_present: msg = "Daemon running, but FadeStick not present." else: msg = f"Daemon running. Current CPU load is {self._cpu_per * 100.0:.2f}% and is color {self._cur_color}." self._daemon_log.info(msg) # Pass messages from the daemon to the controller via a named pipe pipe = os.open(self._named_pipe, os.O_WRONLY) self._daemon_log.debug("Opened IPC pipe") packet = create_msg(msg.encode("ascii")) os.write(pipe, packet) self._daemon_log.debug("Wrote to IPC pipe") # Do not close the pipe in the daemon except Exception as e: self._daemon_log.error(f"Daemon status error: {e}") |
There are some details omitted, like how a string is converted to ASCII bytes, and I added a lock because I would synchronize in Java, but essentially we read and write to a shared named pipe for IPC in Python too. Neat.
Bonus: Reduce Standalone Binary Size
Remember this?
1 2 3 4 5 6 7 8 9 10 11 12 | $ ls -alhSGg total 24M -rwxr-xr-x 1 9.4M May 1 10:20 main -rw-r--r-- 1 3.5M May 1 10:20 libpython3.8.so.1.0 -rw-r--r-- 1 2.9M May 1 10:20 libcrypto.so.1.1 <-- Yikes, 2.9MB? -rw-r--r-- 1 1.2M May 1 10:20 libsqlite3.so.0 <-- We're not using SQLite. Odd. -rw-r--r-- 1 1.1M May 1 10:20 unicodedata.so <-- It's all ASCII, though. -rw-r--r-- 1 580K May 1 10:20 libssl.so.1.1 <-- No networking at all, though. -rw-r--r-- 1 376K May 1 10:20 _decimal.so -rw-r--r-- 1 302K May 1 10:20 libreadline.so.7 -rw-r--r-- 1 267K May 1 10:20 _codecs_jp.so <-- Why are there CJK codecs? ... |
Let’s see if we can get away without the crypto library, Unicode, and CJK codecs to shave off several megabytes from the standalone binary.
Notes:
- I cannot say pickling and unpickling with a straight face. ↩