Being at the tail end of a hosting contract with GoDaddy, the renewal fees have gone way up, plus the Linux kernel and PHP interpreter are outdated – a rebuild is needed. I’ll use this opportunity to migrate my sites to AWS S3 and Cloudflare to save big money, save resources, have fine-grain server control, and squeeze out every drop of performance and get a nice SEO bump.
In Part Two, I show you how to handle the Htaccess file, use Cloudflare Workers to serve dynamic content, create cron jobs, protect your S3 buckets, cache hard, handle comments, and set up a WAF and firewall, and more advanced topics.
Here I outline an algorithm to parse and efficiently store gigabytes of financial snapshots of thousands of companies in order to graph fundamental changes in their health over time, and to perform machine-learning experiments on the fundamental value of those companies.
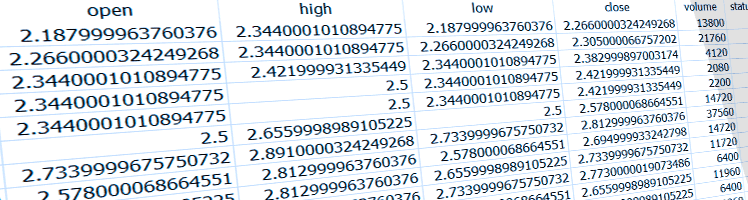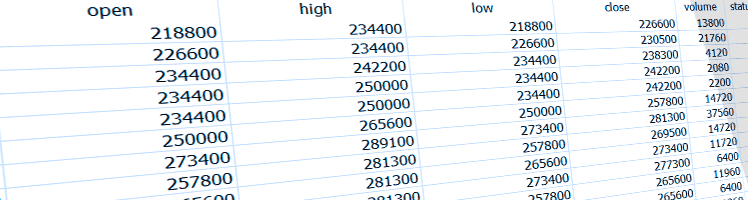
Here I demonstrate the benefits of storing financial numbers as integers instead of doubles in SQLite, maintain a five-decimal precision, and greatly reduce my database size in the process.
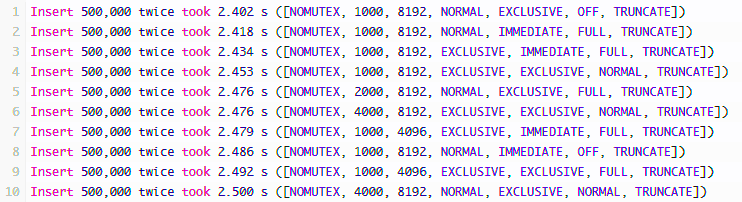
This exercise gave me the opportunity to re-read the docs on the SQLite parameters and confirm their advice with imperial testing. I was able to identify a good page size and understand how the WAL journal works better with the normal synchronous mode. My applications are already running faster.
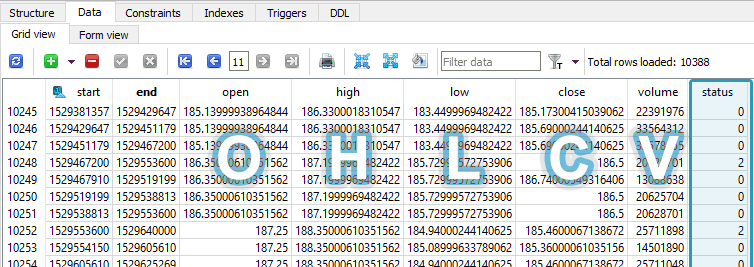
Problem: How to clean the raw OHLCV candle data from the broker for time series analysis? Suppose we have an autonomous program that prioritizes and continually downloads the latest minute and day candles, as well as periodically gets new symbols from the broker. The problem is that the candles are not guaranteed to be full-period […]
Before acquiring financial time-series candles, I need to know the database schema, storage growth, and cost of maintaining the database. How large could financial data grow and cost?