A bare-metal compute node may soft-lock, spin-lock, deadlock, overheat, encounter resource starvation, the Docker daemon goes away, systemd becomes unstable, and on. In these cases, a watchdog timer acting like a dead man’s switch is not updated, a timer reaches zero and the watchdog circuit restarts all the hardware. However, the clusterboard A64 SoCs have a WDT reset problem which we solve satisfyingly.
Locate in one place all the hardware and software gotchas I’ve encountered from compiling and running the U-Boot bootloader to fixing timing issues in a cluster computer of Allwinner A64 SoCs in order to help others with similar issues and remember myself.
Each node of my cluster computer is nameless and stateless like an AWS Lambda, so the entire OS must reside in memory. Having explored minimal Debian, Alpine Linux, and even RancherOS, the most exciting conclusion is to learn to compile the embedded Linux kernel and bootloaders from scratch for ARM64 and learn how to network-boot bare-metal hardware over HTTP.
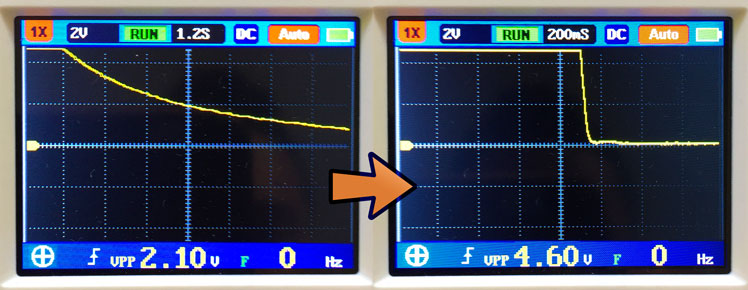
A power supply, when suddenly turned off, bleeds voltage slowly. Attached electronics experience a gradual voltage decline from 5V to 3.3V and eventually to zero. The problem is that microcontrollers and microprocessors don’t know how to behave with under-voltage. Their behavior and flash memory integrity is not defined. Flash memory can even be erased. Here I outline my attempts to achieve an efficient logic-level power supply.
Given a cluster computing rig of twenty-eight processors, each can have either a USB 2.0 or microSD local flash storage. Which type of flash and maker is the fastest? Make the wrong choice and the cluster is painfully slow. Not all microSD cards or USB drives are made the same, and interestingly random read and write speeds vary wildly. Here I test several storage configurations with striking benchmark results.
Let’s build a 112-core 1.2GHz A53 cluster with 56GB of DDR3 RAM and 584GiB of high-availability distributed file storage, running at most 200W. The goal is to use cluster computing to perform fast Apache Spark operations on Big Data, and all on-prem for a fraction of what cloud computing costs.