Cluster Computing – Hardware Planning
Let’s motivate taking up parallel computing and putting in the research time, taking the Coursera and Udemy courses, learning new cluster compute paradigms and frameworks, assembling a physical hardware machine, and yeah, spending thousands of dollars on the hardware with a fun little problem:
1. Motivation: All-Pairs Financial Time Series Correlations
Say we have historic intraday data for about 50,000 securities and indexes. How long will it take to compute some correlations between all pairs of symbols? Can we speed this up? The number of pairs to compute is:
50,000 choose 2 = 1,249,975,000 pairs
On a given machine using napkin math assume each pair takes 1ms to compute. Then it would take
1,249,975,000 * 0.001s = 1,249,975s = 347.2hr = 14.5d
two weeks and a morning to calculate the correlations between all unique symbol pairs. It’s by far more doable than brute-forcing a SHA256 collision (forget about it), but the markets will have well moved on by then. Can we do better?
Let’s scale the problem horizontally: add more processors.
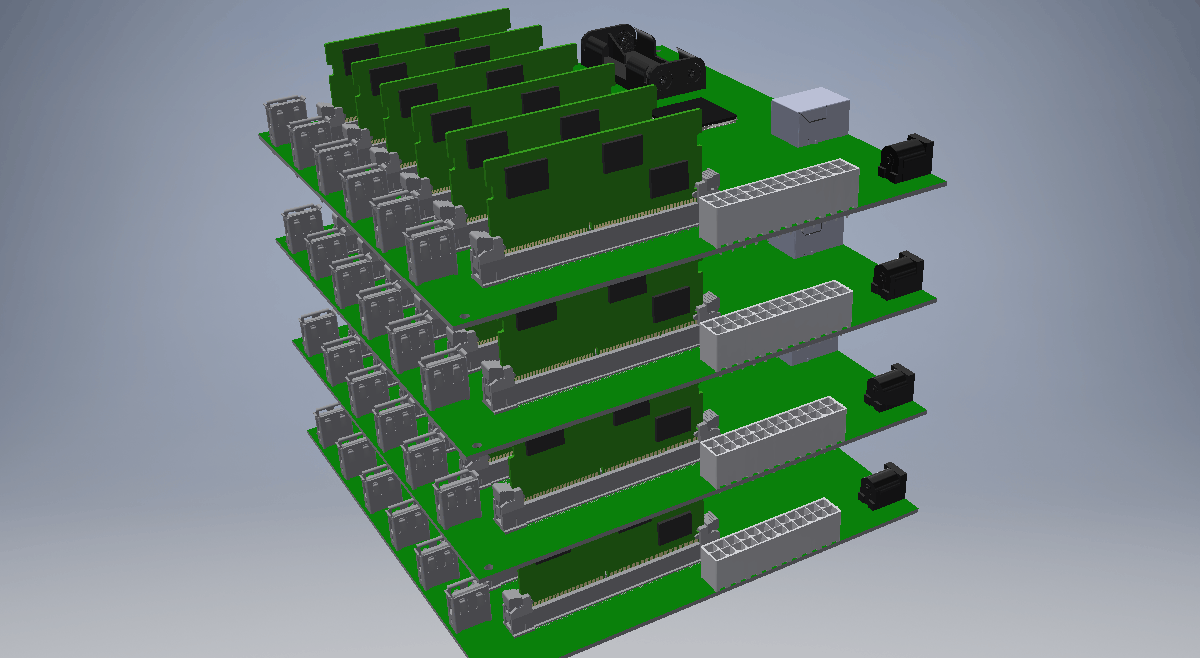
Say we have 27 identical machines and processors available1 and there is no network latency or map/reduce lag time, then in an ideal setup we can reduce the job time to
14.5d / 27 = 0.55d
just half a day. That’s much better than two weeks.
We can do better by not performing all-pairs on all pairs. We could ignore OTC/Pinx stocks and most NASDAQI indexes (see this article). Then we have on the order of 20,000-choose-2 pairs which is about 200 million pairs, which would take 2.3 days on one machine, or less than a couple of hours on our ideal cluster. Now we’re talking. Cluster computing makes sense so far.
2. Infrastructure: AWS/Google Cloud or Physical Hardware?
I was at the Google Cloud OnBoard convention in Vancouver in September this year2 and in an effort to assess cost I stood up and asked a question: Would it be better to do, say, crypto mining using Google Cloud resources, or on an equivalent on-prem hardware setup? There were five GCEs (Google Cloud Engineers) on the stage answering questions at the time, and they paused, looked at each other, then lightly chuckled. The response was that cloud computing was not meant for flat-out processing, but that they would gladly take payment.
Google Cloud Pricing
How expensive would a comparable 28-CPU rig cost per month with Google?
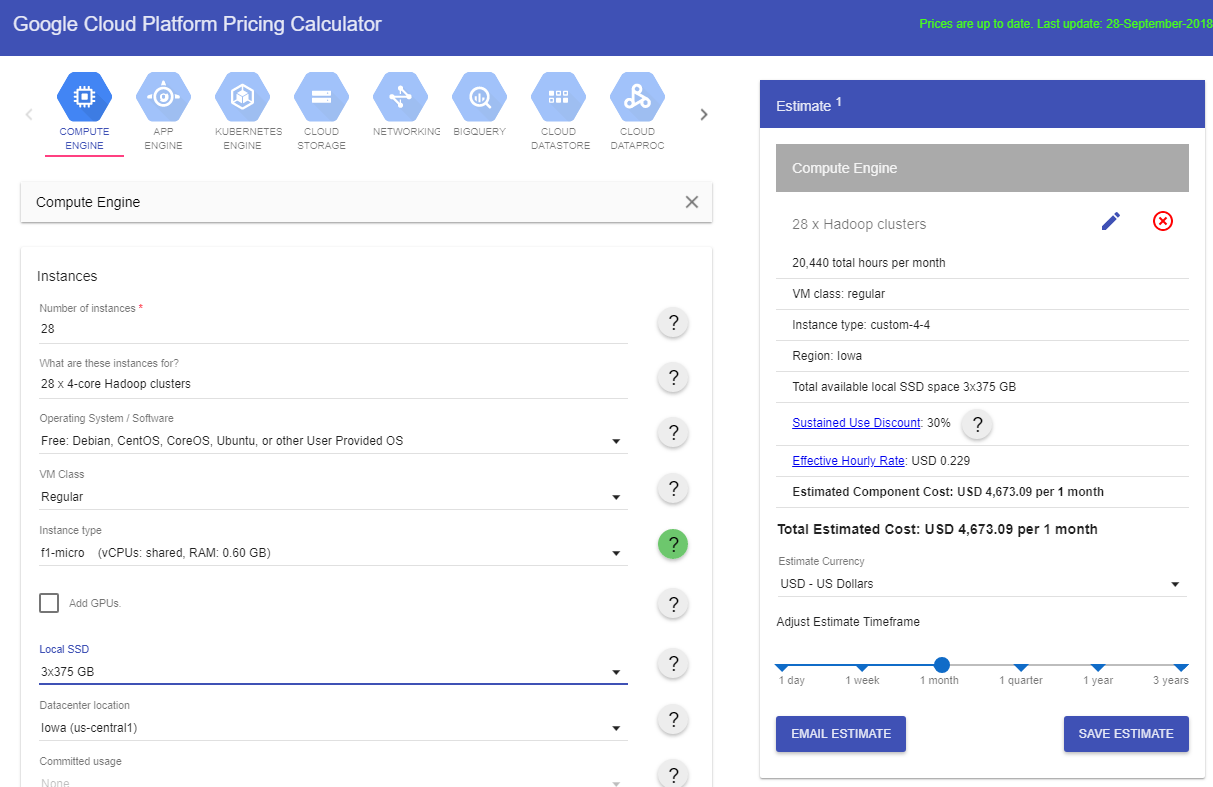
Using the Google Cloud pricing calculator3, I tried a few configurations:
| Instances | Cores | RAM | Preemptible | Local SSD | Usage | Region | Monthly Cost |
|---|---|---|---|---|---|---|---|
| 28 | 4 | 4 GB4 | x | 3×375 GB | 24×7 | Iowa | USD 4,673.09 |
| 28 | 4 | 8 GB | x | 3×375 GB | 24×7 | Iowa | USD 4,927.54 |
| 112 | 1 | 1 GB5 | x | 3×375 GB | 24×7 | Iowa | USD 8,873.13 |
| 1 | 966 | 96 GB7 | x | 3×375 GB | 24×7 | Iowa | USD 1,935.49 |
| 2 | 56 | 56 GB8 | x | 3×375 GB | 24×7 | Iowa | USD 2,333.07 |
| 2 | 56 | 56 GB8 | v | 0 GB | 24×7 | Iowa | USD 647.54 (+191.25)* |
| 2 | 56 | 112 GB | v | 0 GB | 24×7 | Iowa | USD 724.39 (+191.25)* |
*SSD Provisioned Space of 1,125 GB (=3×375 GB) will cost USD 191.25 per month9
Google does not allow a 2:1 cores-to-RAM configuration, so I used a 1:1 ratio in the base calculations. From the last two pricing calculations, it looks like 56 GB of RAM is about $86/mo over two instances.
$734 – $648 = $86 for double the total RAM, so
$648 – $86 = $562 for half the total RAM
On paper we reach a resource-comparable $753 per month ($648 – $86 + $191). Let’s take into account the vCPUs are great and are twice as fast as the CPUs we will be using, and our storage will not be SSD, so let’s use a goodwill factor of 0.4 to come to a Google cloud cost estimate:
$753/mo * 0.4 = USD $301 per month (resource equivalent)
However, if we really are trying to be consistent with the hardware configuration (local storage, not preemptible, 28 CPUs, etc), then we have to use the first calculation and adjust the cost of RAM using the second pricing calculation as such:
$4,928 – $4,673 = $255 for double the total RAM, so
$4,673 – $255 = $4,418 for half the total RAM
Let’s take into account the same good will factor of 0.4 to come to a Google cloud cost estimate:
$4,418 * 0.4 = USD $1,767 per month (hardware equivalent)
Amazon AWS Cloud Pricing
How expensive would a comparable 28-CPU rig cost per month with Amazon?
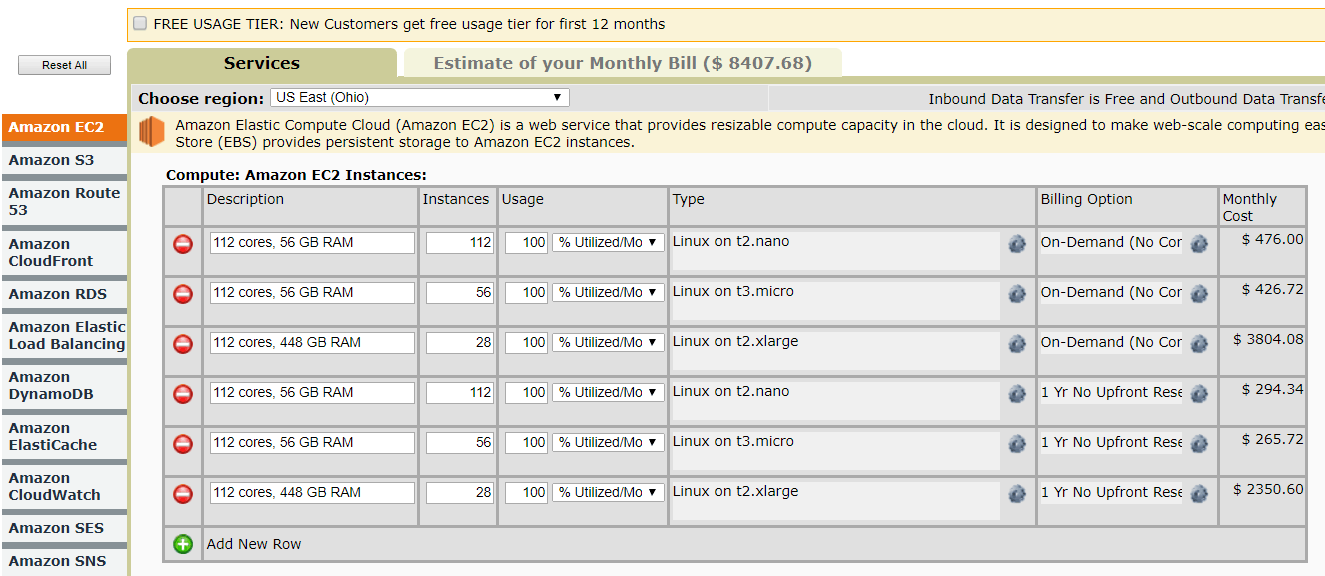
As for AWS, for comparable resources, I selected 112×1-core CPUs with 0.5 GB RAM each for the 112-cores and 56 GB RAM, as well as 1125 GB of basic S3 storage. I also selected 56×2-core CPUs with 1 GB RAM each. It is impossible to customize the instances, but to compare the cluster hardware more closely, I also selected 28×4-core CPUs with 16 GB RAM each – too much RAM, I know. Because the option was so prominent, I also selected a one-year reserve price so see how that affects monthly costs. Here are the results:
| Instances | Cores | RAM | S3 | Usage | Region | Reserved | Monthly Cost |
|---|---|---|---|---|---|---|---|
| 112 | 1 | 0.5 GB | 1125 GB | 24×7 | Ohio | x | USD 476.00 (+25.88)* |
| 56 | 2 | 1 GB | 1125 GB | 24×7 | Ohio | x | USD 426.72 (+25.88)* |
| 28 | 4 | 16 GB | 1125 GB | 24×7 | Ohio | x | USD 3,804.08 (+25.88)* |
| 112 | 1 | 0.5 GB | 1125 GB | 24×7 | Ohio | v | USD 294.34 (+25.88)* |
| 56 | 2 | 1 GB | 1125 GB | 24×7 | Ohio | v | USD 265.72 (+25.88)* |
| 28 | 4 | 16 GB | 1125 GB | 24×7 | Ohio | v | USD 2,350.60 (+25.88)* |
*1125 GB of S3 storage costs $25.88/mo
Let’s use the goodwill factor again, then the AWS compute estimate becomes:
$453 * 0.4 = USD $181 per month (resource equivalent), or
$292 * 0.4 = USD $117 per month (resource equivalent, reserved)
Conclusion: Physical Hardware is More Cost-Effective
On paper, a performance-adjusted 112-core cluster in the cloud is worth between $117 and $301 USD per month, and will cost between $292 and $753 USD per month. But of course this not the end of the story. This looks good on paper, but what can you do with a cloud node that only has 1 GB of RAM, or even just 0.5 GB of RAM? That’s akin to using networked Raspberry Pi Zeros in the cloud. Remember, the hardware I’m building uses 2 GB of DDR3 RAM per node. Also, the vCPUs are still shared with other tenants. Finally, network costs were not included at all. I’ve omitted hundreds of gigabytes per month of I/O traffic that will drive the costs higher.
3. Single-Board Computer (SBC) Design Considerations
Going in I have no idea what cluster compute framework or even languages I will use, but they will either be R or Java, and some kind of Hadoop or Apache Spark stack. I just want to build a box with a lot of wires and LAN cables, and blinking lights for the win. Just kidding. There are important design considerations. For the all-pairs problem, we’re going to need manpower over horsepower, and that means more cores with enough RAM available per core. Analyzing time-series data is not so processor-intensive, but there are thousands of stock symbols to analyze in parallel. Which processor (and SBC or SoC10) to use? Let’s compare.
Here is a condensed table from my larger spreadsheet. PPC is “Price per Core”, and PPCxR is “Price per Core-times-RAM”. All RAM is (LP)DDR311, and all boards have a MicroSD slot and true Gigabit Ethernet capability12. Prices in USD.
| SBC | Processor(s) | Cores | RAM | Storage | Cost | PPC | PPCxR |
|---|---|---|---|---|---|---|---|
| ROCK64 | RK3328 | 4 | 4GB | – | $56 | $14 | $3.50 |
| ROCK64 | RK3328 | 4 | 2GB | – | $35 | $8.75 | $4.38 |
| ROCKPro64 | RK3399 | 6 | 4GB | – | $80 | $13.33 | $3.33 |
| SOPINE | Cortex A53 | 4 | 2GB | – | $30 | $7.50 | $3.75 |
| PINE64-LTS | Cortex A53 | 4 | 2GB | – | $32 | $8.00 | $4.00 |
| ORDOID XU4 | Exynos5542 | 8 | 2GB | – | $62 | $7.75 | $3.88 |
| Parallella | A9+EpiphanyIII | 16 | 1GB | – | $135 | $8.44 | $8.44 |
| NanoPC-T4 | RK3399 | 6 | 4GB | 16GB | $110 | $18.33 | $4.58 |
| NanoPC-T3+ | A53 | 8 | 2GB | 16GB | $75 | $9.38 | $4.69 |
| UDOO X86 Ultra | N3710+Quark SE | 4 | 8GB | 32GB | $267 | $66.75 | $8.34 |
| UP Core | Atom x5-z8350 | 4 | 4GB | 32GB | $149 | $37.25 | $9.32 |
Out of all these performant single-board computers, the SOPINE module has the lowest price per core and second-lowest price per core-GB-RAM. The next closest is the ODROID XU4, but with 8 cores sharing 2GB of RAM, there is going to be more pagefile swapping which we must avoid at all costs. That is another reason why the 16-core Parallella board is out (it is suited for low-memory tasks like parallel password guessing). Some boards have internal eMMC storage, which is nice, but they can not be upgraded, so in a couple of years we will run out of storage (more on that later).


4. Storage Design Considerations
Now that we are moving forward with the SOPINE A64 modules, let’s decide on how to architect our distributed storage. The SOPINE modules have a microSD card slot and a USB 2.0 bus. For now, let’s proceed with a microSD solution on paper. At this time Class 10 are the best, so we are going to use Class 10 cards rated for 10MB/s sequential write, and a higher read speed.
Why not have all the big data on an SSD and shuttle it to the compute modules through the GbE network? With 28 modules (more on this number in a moment), and a NAS network best-bandwidth of 125MiB/s, each module can access only 4.46MiB/s. That’s less than half the sequential read speed of the Class 10 microSD cards. Also, at this time 32GB Class 10 U1 microSD cards are reasonably priced and they are easy to replace when they fail (more on redundancy soon).
Update: I went into detailed benchmarking of microSD cards and USB 2.0 flash storage, and it turns out random read and write speeds differ considerably between devices. We’ll actually be using A113 or A2 cards, not vanilla Class 10 cards.
5. Number of Processors
Pine64 makes a cluster board that holds seven SOPINE modules and has on-board power management and an 8-port Gigabit Realtek switch chip with a 16-gigabit backplane. It also provides USB 2.0 ports and header pins beside each module. Importantly, the cluster board minimizes the use of LAN cables that would otherwise be needed to network 28 SBCs.


Let’s be adventurous and use four cluster boards with seven SOPINE modules each, or 28 compute modules for a total of 56 GB of RAM and 112 cores. There is a sense of pride going past 100 cores, don’t you think? Actually, with four boards we’d only need a 5-port switch (GbE with 10Gb/s backplane capacity) to network them, plus they stack nicely into a cubic volume. Additionally, using four boards is the sweet spot with respect to power utilization (more on that below).
6. Distributed Storage Capacity
How well can we do with, say, twenty-eight 32GB microSD cards? You’d be forgiven for thinking you’d have 896GB of system capacity. You’d really have a third of that, or about 300 GB, which is more like 292 GiB, because HDFS14 has a default replication factor of 3. That’s why the microSD cards can be replaced easily when they eventually wear out without downtime or loss of data.
Is 292 GiB sufficient? At the time of this article, my store of securities data is 90GiB uncompressed and it is growing by 72GiB per year. That gives us a couple of years to see if the price of storage drops enough to warrant an upgrade. Nice.
Why not 64GB cards? At this time there is a generous price break for 32GB cards from several manufacturers, probably because snap-happy smartphone users (such as myself) require more storage than 32GB, so 64GB cards still have a lot of demand and are priced as such.

Update: 128GB cards are in high demand now, so 64GB A113 microSD cards have come down in price. The new plan is to have 584 GiB of redundant, distributed storage for big-data operations.
7. Power Supply Considerations
I’m told each SOPINE module may use up to 6W at peak utilization. At 5V, 6W is 1.2A. Then 1.2A times 7 modules is 8.4A per cluster board. With four cluster boards that is 33.6A. When the 5-port switch and the 4×8-port switch chips are included, that could be up around 40A! There are 200W power supplies that can handle this load. But, adding a fifth board would require a new switch, and a much bigger power supply (the next biggest power supply up is typically 350W). Power-wise, four cluster boards is the sweet spot.

8. Networking Design Considerations
Each cluster board has an RTL8370N-powered 8-port Gigabit network switch with 16Gb/s backplane capacity. This means each SOPINE has access to the full 1000Mb/s wire speed when communicating with a neighbouring SOPINE. If all seven modules try to share the 8th port (intermediate uplink connection), however, then each is limited to
1000Mb/s / 8b/B = 125MiB/s
125MiB/s / 7 = 17.86MiB/s each < ~20MiB/s (sequential microSD read speed)
Now, if there are four cluster boards, then there is another Gigabit switch with enough backplane capacity to allow wire speeds again15. With twenty-eight modules sharing the primary uplink, the math becomes:
125MiB/s / 28 = 4.46MiB/s each ≪ ~20MiB/s (sequential microSD read speed)
This is a better explanation of why we are not using a NAS SSD to supply data to each compute module: it would be far too slow. Granted, 20MiB/s sequential read speed is not great, but with optimizations such as caching the most frequently used stock symbols, we should be able to reduce the IO penalty.
This is where a distributed file system like Hadoop HDFS + Apache Spark shines: compute operations are sent to the data, not the other way around.

Let’s be sure to use Cat6 or Cat6a STP16 cable (rated for 10Gbps) to connect the cluster boards to the network switch. Just do not use Cat5 cable (rated for only 100Mbps). Cat5e cable is rated for 1Gbps, so it should theoretically be okay. I’ll actually be using Cat6 STP cable.
9. Cooling Considerations
These compute modules are going to get hot! Right away we are going to need passive heatsinks. I’ve researched and settled on low-profile aluminum-oxide ceramic heatsinks because they outperform metal heatsinks due to their increased surface area due to micro pits. They need to be low profile because I will need access to the header pins beside the SOPINEs.

The SOPINE modules will need to be actively cooled as well. They get hot, up to 70°C I’ve found, so adequate airflow is required.

I want this cluster to be ninja quiet, so after a lot of research into fans, I settled on ultra-quiet Arctic Air fans. They are 12V PWM fans, so a boost converter will be needed to increase the voltage from the PSU from 5V to 12V. The current should be low, less than 1 amp, so that is why I chose to boost the fan voltage up to 12V, not buck the clusterboard voltage down to 5V from a 12V power supply. A PWM fan controller is a nice touch too.


Update: I ordered and tried three efficient (>85% efficiency) 5V-to-12V boost converters to supply just under 1A of fan cooling but they all got extremely hot – one reached 83°C, and one is known to catch on fire! I’m now using a proper 12V switching power supply alongside the 5V switching supply with zero heat issues.
10. Next Steps
The biggest design considerations have been settled, so the plan now is to physically design and build this compact, and performant compute cluster. As a preview of things to come, the final enclosure is estimated to occupy a volume of only 24cm x 24cm x 24cm which you can hold in your open palm. For my next point of research, I will delve into performance measurements of the SOPINE A64 modules with the Phoronix Test Suite, as well as test the microSD cards, power supply, boost converter(s), PWM controllers, SOPINE thermal properties, and power consumption.
Next: Benchmarking Local Storage
Notes:
- I’m using twenty-seven as an example because I’m actually building a 28-processor cluster but one will be a name node. ↩
- https://cloudplatformonline.com/Onboard-Northam.html ↩
- https://cloud.google.com/products/calculator/ ↩
- The minimum RAM for a 4-core instance is a strange 3.6 GB ↩
- The minimum RAM for a 1-core instance is a strange 0.9 GB ↩
- 96 is the maximum allowed cores on a custom instance ↩
- The minimum RAM for a 96-core instance is a strange 86.4 GB ↩
- The minimum RAM for a 56-core instance is a strange 50.4 GB ↩
- We cannot use local SSD _and_ preemptible instances because we will lose data ↩
- SoC means System on a Chip ↩
- Raspberry Pi 3B+ still uses DDR2 RAM ↩
- Excluded boards may state Gigabit Ethernet, but will share the slow USB 2.0 bus. Another reason why Raspberry Pis were excluded. ↩
- A1 and A2 cards are purpose-built for Android phones and apps. ↩
- Hadoop Distributed File System ↩
- A 10Gbs switch could be used, but chances are we don’t have a 10Gbs router or NIC card in our lab machines, plus Hadoop or Spark makes this unnecessary. ↩
- STP is properly shielded cable, not to be confused with UTP cable which is not shielded ↩