Big Data Backup to S3 Glacier via Java SDK with Spend Evaluation
Why Glacier (or Glacier storage class)? It’s exceedingly inexpensive to archive data for disaster recovery in Glacier. Glacier storage is only US$0.004 per GB/mo, and its SDK is beautiful. Ordinary S3 alone is relatively expensive for the use case, Google Drive and Dropbox are overpriced for big-data archival, and the others are unknowns.
Let’s compare apples to apples on cost first.
Expected Cost
| Monthly | 100GB | 200GB | 500GB | 1TB | 2TB | 10TB |
|---|---|---|---|---|---|---|
| C$2.79 | C$4 | – | – | C$14 | C$140 | |
| Dropbox | – | – | – | C$13 | C$28 | – |
| Degoo | free | – | US$3 | – | – | US$10 |
| CrashPlan | US$10 | US$10 | US$10 | US$10 | US$101 | US$101 |
| AWS S3 | US$2.30 | US$4.60 | US$11.50 | US$23 | US$46 | US$230 |
| Glacier | US$0.40 | US$0.80 | US$2 | US$4 | US$8 | US$40 |
| Yearly | 100GB | 200GB | 500GB | 1TB | 2TB | 10TB |
|---|---|---|---|---|---|---|
| C$28 | C$40 | NA | NA | C$140 | C$1,680 | |
| Dropbox | – | – | – | C$129 | C$279 | – |
| Degoo | free | – | US$36 | – | – | US$120 |
| CrashPlan | US$120 | US$120 | US$120 | US$120 | US$1201 | US$1201 |
| AWS S3 | US$27.60 | US$55.20 | US$138 | US$276 | US$552 | US$2,760 |
| Glacier | US$4.80 | US$9.60 | US$24 | US$48 | US$96 | US$480 |
The pricing sweet spot for big data storage is between 200GB and 2TB with Glacier, plus Amazon has an easy-to-use Java SDK and Maven dependencies already available. I added Degoo and CrashPlan because of their interesting pricing models.
A First Look at the AWS Glacier Java SDKs
Before settling on the AWS ecosystem, first I experimented with the ListVaults example. It was quick to set up a custom AWS policy for Glacier uploads, assign this policy to a new user who will have a Glacier-only scope, allow programmatic interaction (to get the secret keys for API interaction), and create a Vault.
Set up Maven Dependencies
Setting up the Maven SDK BOM (bill of materials) dependency manager and the Glacier plugin was quick. But, the overwhelming majority of sample code is in version 1 of the SDK, so I chose to include both v1 and v2 SDKs side-by-side. Here are the API differences between the two versions.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | <!-- pom.xml --> ... <!-- https://docs.aws.amazon.com/sdk-for-java/v2/migration-guide/side-by-side.html --> <dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.534</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>software.amazon.awssdk</groupId> <artifactId>bom</artifactId> <version>2.5.25</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <!-- AWS Glacier API --> <dependency> <groupId>software.amazon.awssdk</groupId> <artifactId>glacier</artifactId> </dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-glacier</artifactId> </dependency> ... |
List Glacier Vaults
My Java SDK v2 test code to get the vault descriptors is below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | public class VaultTest { static { // User: Questrade System.setProperty( "aws.region", Region.US_WEST_2.id() ); System.setProperty( "aws.accessKeyId", "****" ); System.setProperty( "aws.secretAccessKey", "****" ); } public static void main( String[] args ) { GlacierClient client = GlacierClient.builder().build(); // New SDK v2 - automatic pagination client.listVaultsPaginator().vaultList().forEach( v -> { System.out.println( "Describing the vault: " + v.vaultName() ); System.out.print( "CreationDate: " + v.creationDate() + "\nLastInventoryDate: " + v.lastInventoryDate() + "\nNumberOfArchives: " + v.numberOfArchives() + "\nSizeInBytes: " + v.sizeInBytes() + "\nVaultARN: " + v.vaultARN() + "\nVaultName: " + v.vaultName() ); System.out.println(); } ); } } # Output: # Describing the vault: example # CreationDate: 2019-04-14T08:19:28.893Z # LastInventoryDate: null # NumberOfArchives: 0 # SizeInBytes: 0 # VaultARN: arn:aws:glacier:us-west-2:054307950064:vaults/example # VaultName: example |
Create a Glacier Vault
Next, I try to create a vault with the SDKv2.
1 2 3 4 5 6 7 | GlacierClient glacier = GlacierClient.builder().build(); CreateVaultRequest request = CreateVaultRequest.builder().vaultName( "testvault" ).build(); CreateVaultResponse response = glacier.createVault( request ); System.out.println( response.toString() ); # Output: # CreateVaultResponse(Location=/054317950074/vaults/testvault) |
This short snippet creates a new vault perfectly. In fact, repeated calls to create the same vault raise no exceptions.
Upload a Test Archive to Glacier
Next, I’d like to use the high-level upload manager library (v1 only) to test uploading to Glacier. When this is available for v2 I may come back and refactor the code.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | // Start a timer - Google Guava Stopwatch stopwatch = Stopwatch.createStarted(); String vaultName = "testvault"; File archiveToUpload = new File( "... test.zip" ); ArchiveTransferManagerBuilder builder = new ArchiveTransferManagerBuilder(); ArchiveTransferManager atm = builder.build(); atm.upload( vaultName, "AAPL-8049 April 13, 2019", archiveToUpload); // Get the timing System.out.println( "Upload took " + stopwatch.stop() ); |
Uploading worked for a 44MB test file, albeit slowly, taking about 1.2 minutes with an upload speed of about 5Mbps – that’s 0.6MB/s.
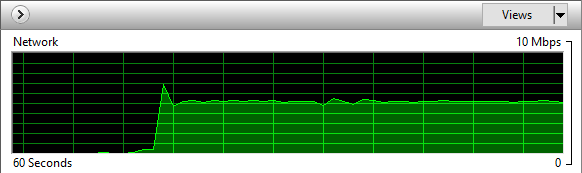
Deal Breaker: List Glacier Vault Contents
Here is a wrinkle I encountered. It takes from a few hours to half a day to inventory each vault. I cannot verify the archives were uploaded nor their checksums. After creating a job and hours of waiting for that inventory job to complete, I could get back a stream that resolved into a JSON response. Here is a sample response:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | [ { "VaultARN": "arn:aws:glacier:us-west-2:054307950064:vaults/testvault", "InventoryDate": "2019-04-15T13:48:39Z", "ArchiveList": [ { "ArchiveId": "FfQsTMP1oeRWGKXKNopeEIvtEuulcpTB0TYmWAgM3Y47WoSOHisRXmmLgDld8gciKePHyyT2JPUHd1Eea_mtb-ReYYRREdHagIm4sFUD74iwnWSRz0_tYu6i6AJi48vTjXKsxzRo_g", "ArchiveDescription": "AAPL-8049 April 13, 2019", "CreationDate": "2019-04-15T01:15:48Z", "Size": 17915904, "SHA256TreeHash": "b7f68c1964db4ae21d2d1ddfc04b98c54b4195631186f8e8fef8f556eb3b4614" }, { "ArchiveId": "sVElfOq1B82siJ0RJX5_LCI7pawnwuGy2EKa16ongy4dcNu8m4zoBAX_ST1V95OEGmLR0GDu72lH3ortG1LTXo2hUhq8FDMUroUt8-LSNGMhO1fHWVsuVPK9AeETeJcKtkTAUvuhNg", "ArchiveDescription": "AAPL-8049 April 13, 2019", "CreationDate": "2019-04-15T01:23:10Z", "Size": 17915904, "SHA256TreeHash": "b7f68c1964db4ae21d2d1ddfc04b98c54b4195631186f8e8fef8f556eb3b4614" }, { "ArchiveId": "WDMG0uSTymjVv4V9UxScg9CbY-zbcgiWVkPVxe_hIgLvXtA67JEpJ0EFvSUBbP1U2BjVt2WF9JMY-faKWdgXJ50hZF4C0UjREqyNlqCFXRBcEtsYldPycPphAXRQEF70JZh6ZQkJKA", "ArchiveDescription": "AAPL-8049 April 13, 2019", "CreationDate": "2019-04-15T01:26:28Z", "Size": 17915904, "SHA256TreeHash": "b7f68c1964db4ae21d2d1ddfc04b98c54b4195631186f8e8fef8f556eb3b4614" }, ... |
I noticed is that even though I uploaded the same file multiple times, the data is treated as an object with a description, a timestamp, and some unique id. There is no file name associated with the object. That means I had better include the original filename in the description. Also, files are not overwritten. This is definitely different than uploading to S3 or casual-user cloud storage. This storage workflow is a deal-breaker.
Next Idea: AWS S3 Glacier Storage Class and Lifecycle Policies
Searching out how others solved this problem I discovered that some people upload their archives to expensive AWS S3 but store them as the Glacier storage class. This can be set up with so-called lifecycle policies to do this automatically. The uploads are Glacier-priced but are accessed via the S3 API, and bucket (not vault) inventory is instantaneous. However, there is no notion of vaults and vault locks with the S3 API, and retrieval times are just as long.
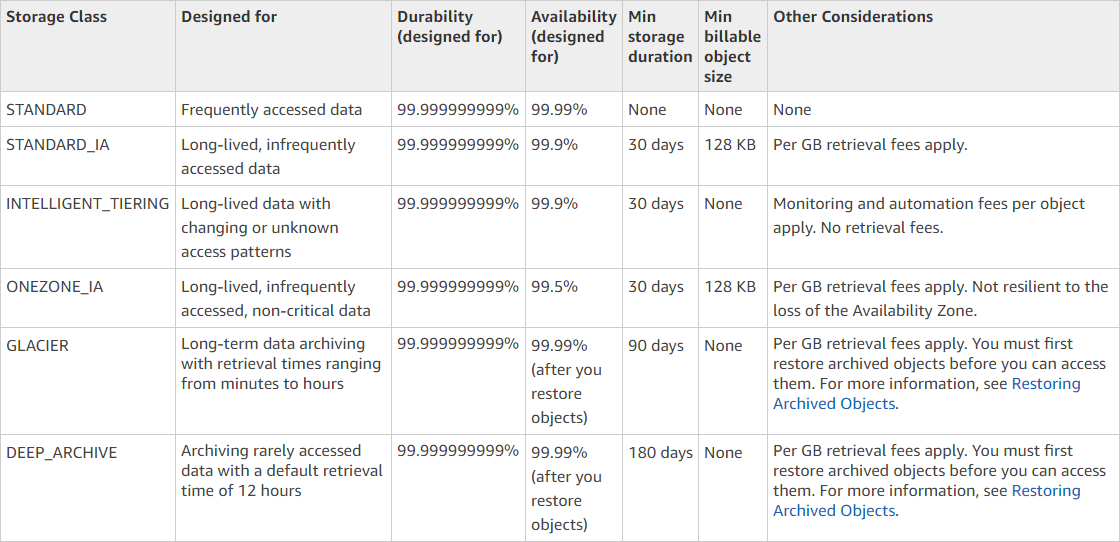
Here is an example of setting the bucket lifecycle policy to transition S3 objects immediately to the Glacier storage class (set days to 0). Interestingly, through S3 only (not Glacier), there is a Deep Glacier storage class that has a minimum billing time of 6 months but is even cheaper than Glacier at $0.00099 per GB/mo. Since Glacier requires a minimum billing time of 90 days, the objects will transition from the Glacier class to the Deep Glacier class after 90 days, and there will be no S3 billing.
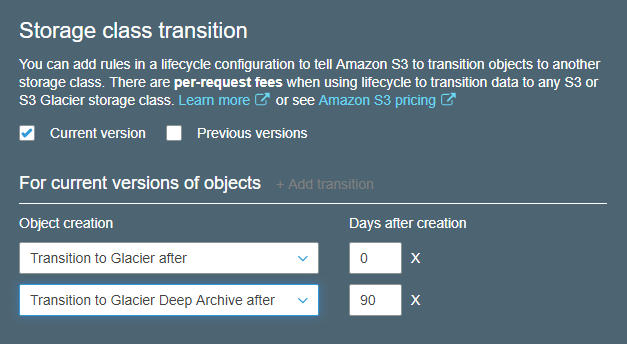
Having experienced the limitations of a pure-Glacier implementation, the S3 with Glacier and Deep Glacier storage classes looks to be a better alternative I will explore next.
Update the Maven Dependencies
I’ll remove SDK v1 dependencies to get used to SDK v2.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | <!-- pom.xml --> ... <dependencyManagement> <dependencies> <dependency> <groupId>software.amazon.awssdk</groupId> <artifactId>bom</artifactId> <version>2.5.25</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <!-- AWS S3 API --> <dependency> <groupId>software.amazon.awssdk</groupId> <artifactId>s3</artifactId> </dependency> ... |
Upload a Test Archive to S3
After manually setting up a bucket with permissions, encryption, and more whiz-bang settings, my first test in code was to upload a file to S3. There are no folders in S3 as it is like a giant key:value data store, so I abstracted the concept of folders to stay consistent with my workflow. The simplest upload code follows.
1 2 3 4 5 6 7 8 9 | PutObjectRequest request = PutObjectRequest.builder() .bucket( bucketName ) .key( remoteObjectPath ) .metadata( metadata ) .storageClass( StorageClass.STANDARD ) // Set to Glacier? .build(); PutObjectResponse response = s3.putObject( request, localFile.toPath() ); # PutObjectResponse(ETag="1888b9dc2fa4c6958b0feb5ef88e96d0", ServerSideEncryption=AES256) |
Sure enough, my file appears in the AWS console. This is much more convenient than uploading directly to Glacier.
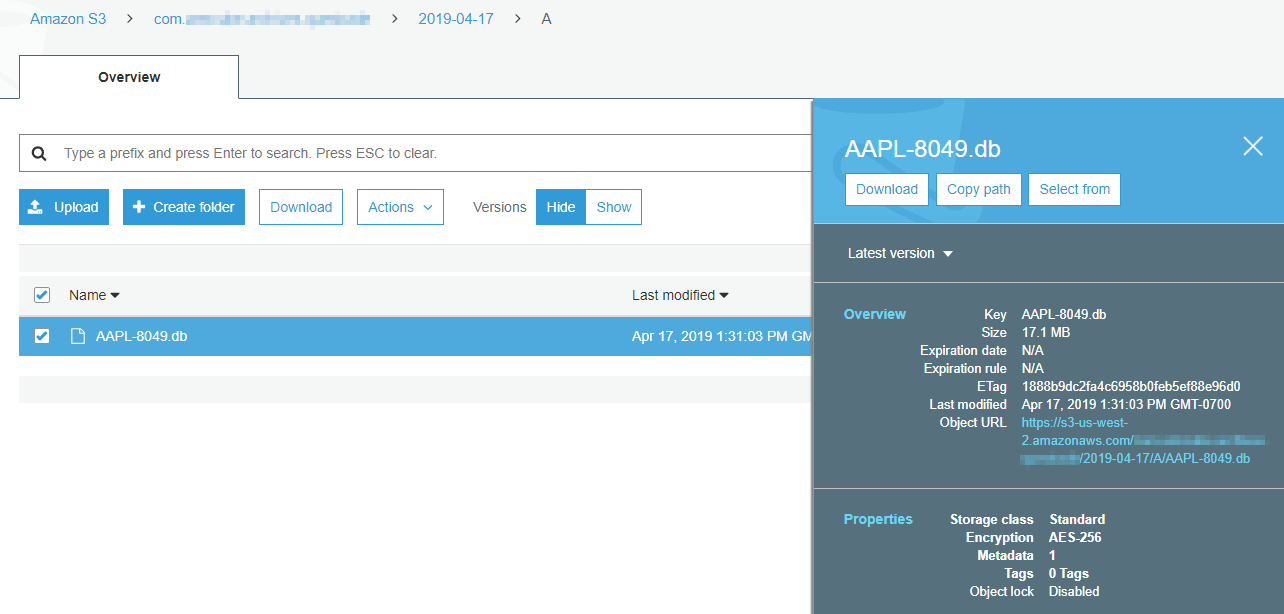
However, the object (file) didn’t immediately transition to Glacier storage. I tried again without specifying the storage class parameter. Again, nothing. Finally, I tried again and specified StorageClass.GLACIER which did work. I need to explore why the lifecycle policies didn’t kick in.
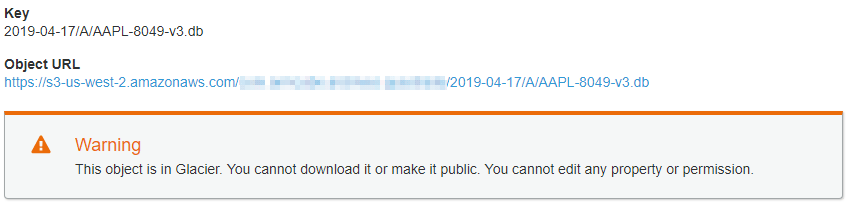
STANDARD storage class becomes GLACIER. Also, because I keep uploading the same test file, it kicks the file out of the lifecycle pipeline as if waiting for me to make up my mind.Paranoid Data-Integrity Checks
AWS allows you to calculate the MD5 digest locally, upload the object, then it will calculate the MD5 digest also and compare them. If they are different, the job will fail. I added this bit of paranoid defensive code below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | // Calculate MD5 manually String md5; try ( InputStream is = Files.newInputStream( localFile.toPath() ) ) { // Calculate the MD5 ourselves and encode is as base64 for AWS to check md5 = new String(Base64.encodeBase64( DigestUtils.md5( is ) )); } catch ( IOException e ) { logger.error( getMessage( e ) ); throw e; } // TODO: Explore more parameters PutObjectRequest request = PutObjectRequest.builder() .bucket( bucketName ) .key( remoteObjectPath ) .metadata( metadata ) .contentLength( localFile.length() ) // File sizes must match .contentMD5( md5 ) // Digests must match .storageClass( storageClass ) .build(); |
Bottom Line on S3 with Glacier Storage Class
S3 with lifecycle policies to move objects to the Glacier storage class is the best solution for my use case. I can overwrite archives with the same name, inventory the S3 bucket immediately after upload, and deeply manage permission siloing. Using S3 without a deliberate workflow is not a panacea, however. I’m going to explore the cost of many PUT requests to S3 – they can add up quickly – and how to reduce this cost.
Strategies for Continually Archiving Big Data
I’m at a crossroads. With a 5Mbps upload speed, it will take 22.8 hours to upload a 50GB compressed archive of my financial time-series data to S3+Glacier periodically. I could make this a scheduled weekly job on Sunday (all-day Sunday), or I could explore faster internet providers. Unfortunately, the telcos in British Columbia, Canada all have mutually slow upload speeds, possibly in an effort to nudge power users to business plans. Fiber optic coverage is spotty in Metro Vancouver or else that would be perfect as the symmetric internet speeds of fiber are ideal. Let’s assume I’m limited to 5Mbps for now (recall that on-prem hardware is far less expensive than cloud processing).
1. Backup Atomically
One option is to run a start-to-finish S3+Glacier upload job every Sunday taking 23 hours to upload a 50GB-and-growing compressed archive. With S3, the backup can be uploaded in parts. If the upload is interrupted, it can be resumed as long as it is within 24 hours. This provides 24 hours for a 23-hour job at 5Mbps, weekly.
2. Backup Individually
Before any ETL, all the big data is stored over 55,000+ SQLite files totally nearly 200GB. Each one can be compressed individually and uploaded to S3+Glacier. Over the course of the week, the previous week’s archives can be uploaded steadily. This provides 168 hours for a 23-hour job at 5Mbps, weekly.
It’s minute, but I discovered that Amazon reserves 32KB for metadata per object within Glacier, and 8KB per object in S3, both of which are charged back to the user. For this workflow, that is about 55,000 files at 8KB each or 430MB of overhead (US$0.002/month). However, what is not minute is that this strategy requires 55,000 x 4 (weekly) PUT requests, or 220,000 PUT requests a month (US$1.10/month). If you’re keeping track, this doubles our monthly storage cost!
3. Backups Deltas
Every week a rolling copy of the most recent one-week data is updated. Uncompressed this is about 5GB (2.3 hours to upload at 5Mbps). Compressed this is about 1GB (28 minutes at 5Mbps). This strategy provides 168 hours for a 28-minute job, weekly.
4. Backup Chaining with Archive Volumes
Every weekend a 50GB+ full archive is created (taking 5 hours). Every weekday a rolling 1GB+ delta archive is created (taking 2 hours). These archives are split into parts like Zip volumes. These parts are then uploaded in the background over the course of the week, taking about half an hour for the dailies, and 23 hours for the full archive.
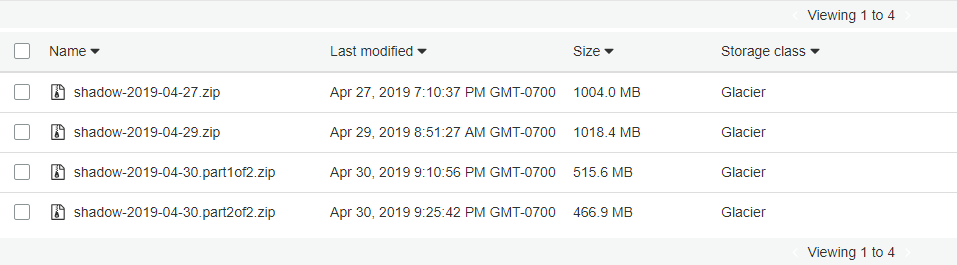
In the screenshot below I first uploaded the entire dailies, then I switched to uploading 512MB parts as a proof of concept.
Backup Strategy in Practice
I’ve decided to do what I do with my desktop hard drive backups: create a full backup, create a chain of deltas, create another full backup, and repeat.
First, a full archive is created each weekend. Below is a console snapshot showing about 57,000 SQLite database files being compressed to zip files. An x means the DB file hasn’t changed and doesn’t need re-compression. This takes about 5 hours to compress 200GB+ to around 50GB cumulative. These zipped files are then stored in a single archive (like tar) with a common name so the hard disk doesn’t fill up. This single archive is then rsync’d to another machine on the LAN at gigabit speeds, but not to S3, yet.

Similarly, an archive of daily deltas (with a few days of overlap) is created occupying about 1GB. This happens daily in the evening. The reason for the overlap is because if a day is missed or lost, for whatever reason, then the subsequent delta will include the missing day.

Next, the single 50GB archive is split into about one-hundred approximately-512MB parts. Each part is uploaded to S3 in a background worker so after about 23 hours at 5Mbps the entire archive is transferred. After each part is uploaded, it is removed from the local machine. If there is an interruption, the upload queue continues from the last pending part to upload. This strategy incurs a cost on the order of only 100 PUT requests.
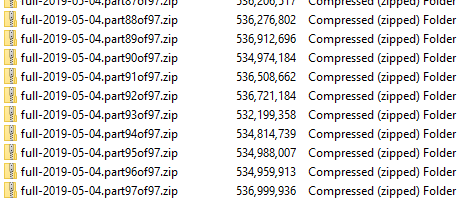
After nearly a day all 97 parts are uploaded to S3 without issue.
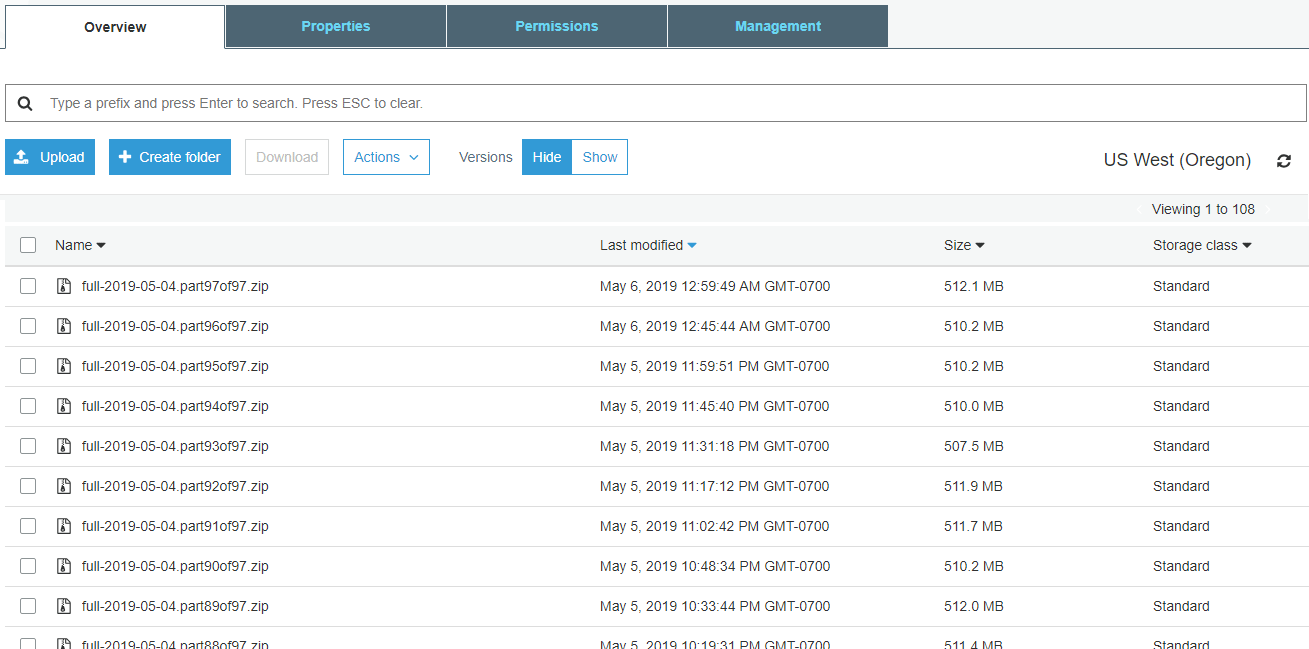
Half a day later the storage class changes to Glacier according to the lifecycle rules. It all works as intended.
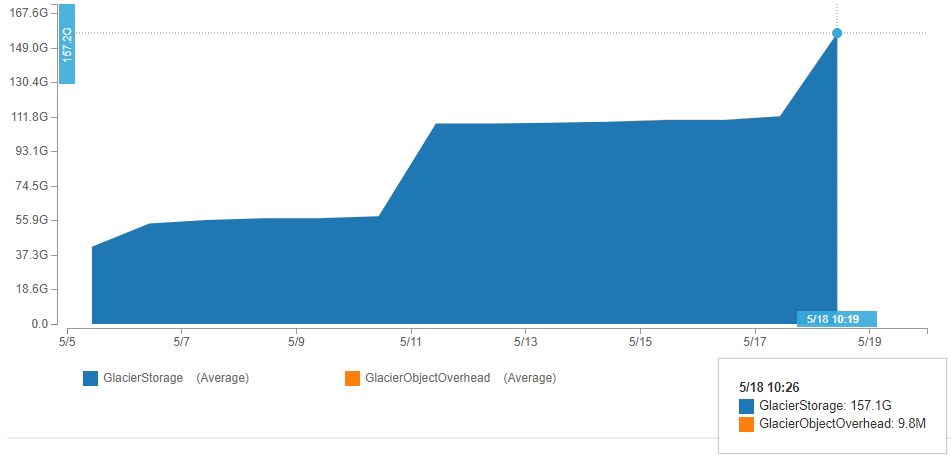
Update: Here is a graph over time of the size of my S3 archives bucket showing the progression of full archives and incremental archives. The latter two slopes indicating the upload of the full archives are steeper than the leftmost slope because I upgraded my internet package from 5 Mbps up to 7.5 Mbps upload.
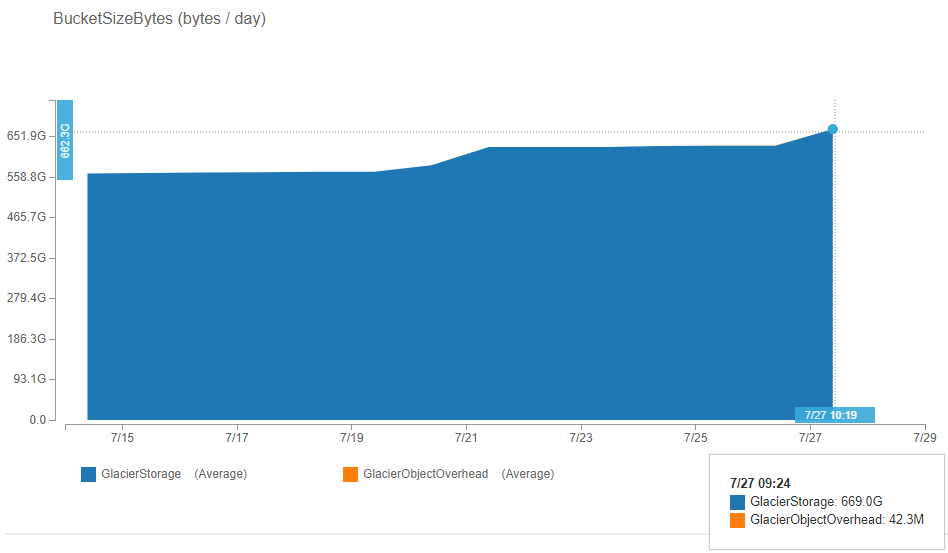
Update: Here are the graphs of my S3 Glacier storage volume and costs as of July 27, 2019. I’ve reached about 660GB and my costs are around US$2. Very nice.
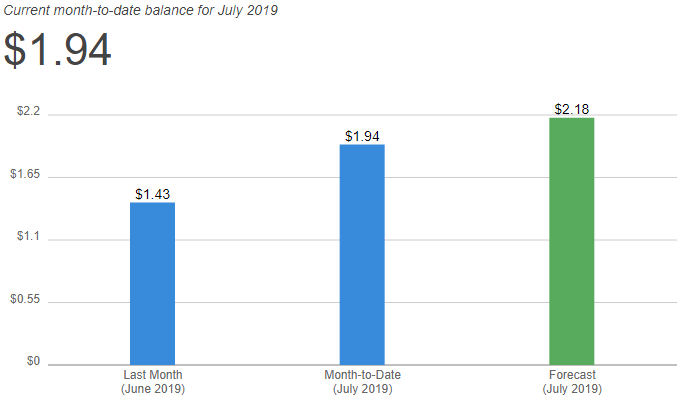
One interesting hidden cost that I didn’t know about is that AWS charges you to promote an object storage class to S3 Glacier. It’s small, but if you are working with thousands and thousands of little files, say backing up a git repo, then this could add up.

Notes:
- They say unlimited data for the same price ↩