Block YouTube Ads on AppleTV by Decrypting and Stripping Ads from Profobuf
I discovered that putting a man-in-the-middle proxy between my Apple TV and the world lets me decrypt HTTPS traffic. From there, I can read the Protocol Buffer data Google uses to populate YouTube with ads. It is too CPU-intensive to decode Protobuf on the fly, so instead I found a flaw in the YouTube implementation of a Protobuf feature that lets us reliably change one byte to obliterate ads.
What follows is a reference guide for setting up a bare-metal network router to block malicious ads, obnoxious ads, tracking, clickbait, cryptojackers, scam pop-ups, Windows spying on you, and more, using blocklists to protect all networked devices.
Sections
Part 1 – Set Up pfSense on Bare Metal
- Why Block Ads and Behavior Tracking?
- Required Router Hardware
- Unboxing the Hardware
- Install pfSense on Bare Metal
- First pfSense Boot
- Enable the AES-NI Cryptographic Instruction
- Enable RAM-Disk Caching
- Dashboard Widgets
- Ad Blocking with pfBlockerNG
- Isolate LANs for Security
- Class B IPv4 172.31.1.0/24 Network for Untrusted Devices
- Add Firewall Rules
Part 2 – Isolate Network LANs
- Set Up the Untrusted Wi-Fi AP
- Automatic pfSense Configuration Backups
- Unable to Reach 172.31.1.x from 192.168.10.x
- Replace Stock Firmware on the AC1200 Wi-Fi Access Point
- Archer C5 v2 to the Trash, R7000 as the New Wi-Fi AP
- Set Up the Trusted Wireless Network
- Network-Device Interconnectivity Check
- Windows File-Sharing Gotchas
- Public Service Announcement: Microsoft Edge Browser
Part 3 – Set Up DNS Ad Blocking
- Block Clickbait, Incessant Ads, and Dangerous Sites
- Intercept All DNS Requests, Even to Hard-coded DNS Servers
Part 4 – Trick the YouTube Ad Algorithm
- How to Restrict YouTube Ads on Apple TV?
- Trick the YouTube Ad Algorithm Instead
- Research Into YouTube Advertising Spend
- New Goal: Convince YouTube I’m 70 and in Italy
- Selectively Route Apple TV Through the VPN
- Selectively Route Apple TV YouTube Traffic Through the VPN
- Gotcha: DNS Race Condition
- Gotcha: Authentication Failure — 403 Forbidden Error
- Gotcha: YouTube Is Now Showing UK Ads, Not Italian Ads
- Find a VPN Exit Node Without an ASN Leak
- Hijack Google Video DNS Queries
- New Goal: Programmatically Add IPs to the Firewall Policy Rule
- Research Python Methods to Hijack DNS Queries
i. Perform an Rsync Disk Backup
ii. Install the pfSense REST API
iii. Explore the Unbound Python Module - Smoke Test: A Python DNS-Hijacking Script
Part 5 – Decrypt HTTPS Traffic
- New Goal: Research and Install a Squid-Like Proxy
i. Fun Fact: Jailbreaking iPhones in Japan - Install a Fake-but-Trusted CA Certificate on Apple TV and iPhone
- Experiment With Squid and SquidGuard
- Self-Host the CA Certificate
- Abandoning Squid: Too Slow, Too Heavy
i. Run an Rsync Diff of Changes - Install MITMProxy in a FreeBSD Jail
- Exploring MITMProxy
- Patch MITMProxy Source Code for Server SNI Interrogation
Part 6 – Intercept Apple TV and iOS YouTube Ads
- Smoke Test: Intercept YouTube Ads With MITMProxy
- Examine uBlock Origin Regex Patterns for Inspiration
- Surgically Alter the JSON Response to Remove Ads
- The iOS YouTube App Uses Protobuf, Not JSON
- Timing Analysis to Detect Ad Videos
- Decode the YouTube Protobuf Responses
- Ad-URL Polymorphism
- Smoke Test: Intercept and Decode Protobuf in Python
i. Pure-Python Benchmarks
ii. Pure C++ Benchmarks - Fuzzing the YouTube Video-Ad Responses
- Use Burp Suite Tools for Penetration Testing
- Exfiltrate the Proto Schemas From the App, Cleanly
Part 7 – Reverse-Engineer Protobuf Messages
- Hardcore Deep Dive into Protobuf and Wire Format
- Exploit a Protobuf Feature to Easily Remove All Ads by Changing One Byte
- Smoke Test: Remove Ads from Protobuf in O(n) time
- Analysis of This Successful Adblocking Technique
i. Summary
ii. Timing Analysis
iii. Knock-On Benefits
iv. Future-Proof
v. Should Google Be Worried? - The MITMProxy YouTube Adblocking Script
Part 8 – Summary
- YouTube Premium
i. Experiment in Ad Viewing
ii. $0.15 as a Ballpark CPV
iii. CPV from U.S. Advertising Spend Divided by Total Views
iv. Is YouTube Premium Worth It? - DMCA, Sony, Viacom
- Summary of Accomplishments
Why Block Malicious Ads and Behavior Tracking?
You are a valuable commodity, bought and sold without your knowledge or consent. You will be tricked with clickbait, distracted by intrusive ads, and enticed to leave the site you are on at every opportunity. Plus, everything you do online is monitored so your habits and searches can be remarketed and resold for years.
Privacy — Knowing what you watch and read, which phone you own, what you stream on Netflix, what you shop for, what you ask Alexa, your taste in music, and more is unbelievably valuable to advertisers. Spying on people became such a problem that Europe passed the GDPR, forcing every site to ask if you accept cookies (and we blindly click “OK” just to hide the banner). We need to wrestle privacy back ourselves.
Bandwidth — If privacy doesn’t concern you, consider this: between 25 % and 40 % of network traffic is ads, tracking scripts, and JavaScript loaders for trackers like fingerprint.js, googletagmanager.js, or real-time analytics such as Hotjar. Have a 100 Mbps connection? Functionally, it may run at 60 Mbps.
Clickbait — “You won’t believe what Tom Cruise did next—he…” You may click, and then you’re caught in the spider’s web. Fake news, “sponsored” posts disguised as articles, or “underscored” content can route you to pages with a dozen shady ads that bypass Google’s filters. Clickbait is incredibly profitable to scammers.
Cryptojacking — Some sites load crypto-mining JavaScript (e.g., CoinHive.js) that overheats and abuses your computer to earn a few pennies. Others inject scripts that try to drain your crypto wallet or trick you into sending cryptocurrency.
Required Router Hardware
Virtual machines, Docker images, and Raspberry Pis are not performant enough to protect an entire SMB network. Instead, we need dedicated hardware with a cryptographic instruction set whose only job is to route, decrypt, and monitor packets. Here’s what I used:
- A mini PC with the AES-NI instruction set (e.g., J4125)
- Several gigabytes of DDR4 RAM (e.g., 32 GiB)
- A decent mSATA SSD (e.g., 128 GiB)
- A USB drive to flash pfSense
Unboxing the Hardware
I ordered a J4125 mini PC from AliExpress, 32 GB of DDR4 RAM, and a 128 GB mSATA SSD from Amazon, and I’m about to assemble them for the first time.
A beautiful box, isn’t it? It has only three LAN ports, but you can expand those with network switches.


Install pfSense on Bare Metal
I’ve never used pfSense before, so let’s explore it together. The compressed image is about 360 MB and can be flashed to a USB drive with the Etcher AppImage—very cool. VGA install or serial? I thought about serial, but:

Serial access would be a hassle in an emergency: the port is internal, and there’s no RS-232 or JTAG connector—just narrow header pins. Yikes. Let’s use VGA and plug in a USB keyboard—get ready to navigate with arrows and tabbing.
I’m following this guide on YouTube. I’ll pass on encrypting the disk since I would like to avoid entering a passphrase each time the mini PC reboots. A stripe disk is fine since there is only one disk. I have no idea what to expect yet, so I will pass on dropping to a shell for a more advanced configuration.
First pfSense Boot
I ejected the USB drive that contained the boot image (important) and rebooted the little box. It played a melody on the internal speaker—there’s a buzzer inside, and thankfully it isn’t very loud.
Do I need to have a LAN cable connected already, or can I just power it on? I’ll start pfSense and let it complain if it wants… and, according to the YouTube tutorial, I should guess which port is LAN 1. I’ll do that now.
I figured out that I should set LAN 1 to a static IP address outside my existing router’s DHCP range, so I chose 192.168.1.3. Now I can access the admin web portal (admin/pfsense). Hooray.
Yikes—the mini PC beeped at me and informed me that “admin” has logged in. That startled me a bit, but hey, that’s pretty neat.
Enable the AES-NI Cryptographic Instruction
I played around with the setup wizard, used the defaults, and reached the web configurator. The first thing that caught my eye was AES-NI CPU Crypto: Yes (inactive). I went out of my way to buy a mini PC with AES-NI—what gives?
Ah—AES-NI must be enabled under System › Advanced › Miscellaneous. Why doesn’t it auto-detect this and choose the best option? I’m glad I spotted that; otherwise, this mini PC might as well be a Celeron J1900 from yesteryear.
Enable RAM Disk
Having 32 GiB of RAM, let’s take advantage of that and use a generous amount for /var and /tmp, and since—hopefully—this 128 GiB SSD has wear-leveling, let’s take a RAM-disk backup every hour.
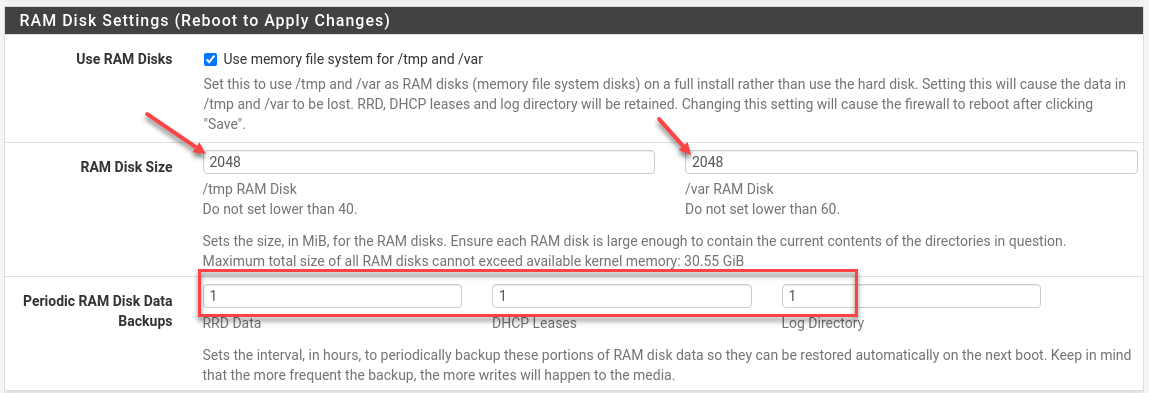
Reboot! AES-NI is now active.
Dashboard Widgets
This dashboard is pretty slick. I’m just discovering that there are widgets that can be added to the Dashboard, including S.M.A.R.T. to alert us if the SSD is going bad. Nice.

Hang on—when I added the Services Status widget, something called PC/SC Smart Card Daemon shows up. What is that? Research shows it’s a daemon for hardware smart keys that we can probably do without. It can be disabled in the /etc/rc.bootup file like so:
1 2 3 4 5 | /* pcscd daemon must be started before IPsec */ echo "SKIPPING PC/SC Smart Card Services..."; # echo "Starting PC/SC Smart Card Services..."; # mwexec_bg("/usr/local/sbin/pcscd"); # echo "done.\n"; |
Wait. After some time went by, I noticed the router slowed down—fatally.
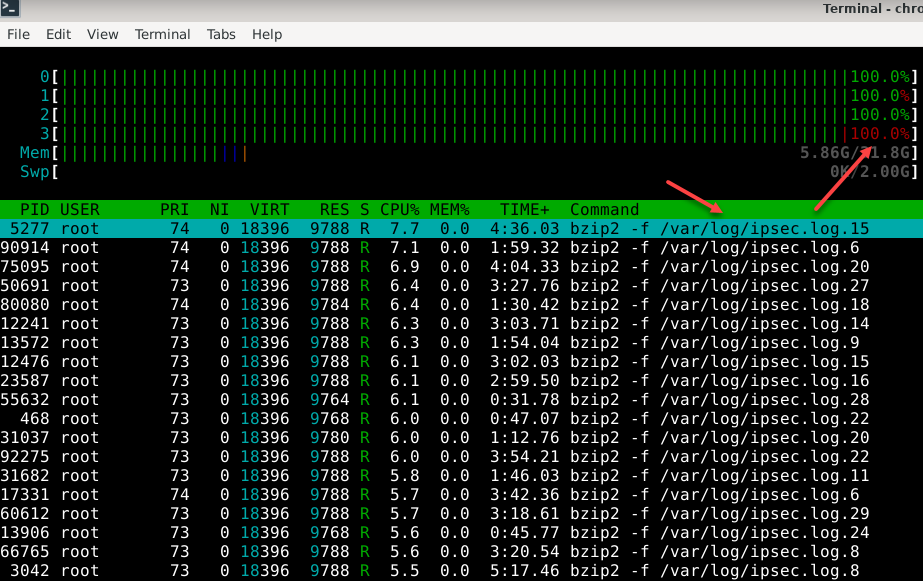
pcscd. If you start experimenting with an IPsec VPN tunnel and the daemon is disabled, your hard disk will fill up with logs and your CPU will run hot.Adblocking with pfBlockerNG
This unboxing and setup has been fun, but I’d like to block all the bad traffic on my network. I’ve been using a workhorse of a DNS-level adblocker called Pi-Hole on a—yes—Pi, but it would be nice if I could reclaim that wee bit of hardware for something else and use a comparable add-on module in pfSense. Let’s explore that now.
pfBlockerNG is a very powerful package for pfSense® that provides advertisement and malicious-content blocking along with geo-blocking capabilities.
Question: Do I install the plain pfBlockerNG package or the pfBlockerNG-devel package that looks like a developer version? I’m a software developer, so this is for me, but am I a pfSense developer? No. Maybe it will show me advanced logs or let me mess about with Lua? Let’s Google this.
From here, random people say to install the development version. Another blogger advocates using the dev version as well. Meh, I guess we can install jq, rsync, and Python 3.8. It doesn’t feel like a development version since it has exciting dependencies.
That was painless and added only about 20 MiB. It seems many dependencies are already part of pfSense. The knight at the end of Raiders would say I have chosen wisely (though, why did Indy age like a normal person up to Indy 4 if he drank the immortality water that the thousand-year-old knight also drank?).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | New packages to be INSTALLED: gmp: 6.2.1 [pfSense] grepcidr: 2.0 [pfSense] iprange: 1.0.4 [pfSense] jq: 1.6 [pfSense] libmaxminddb: 1.6.0 [pfSense] lighttpd: 1.4.59 [pfSense] lua52: 5.2.4 [pfSense] nettle: 3.7.2_2 [pfSense] pfSense-pkg-pfBlockerNG-devel: 3.1.0 [pfSense] py38-maxminddb: 2.0.3 [pfSense] py38-sqlite3: 3.8.10_7 [pfSense] rsync: 3.2.3_1 [pfSense] whois: 5.5.7 [pfSense] xxhash: 0.8.0 [pfSense] zstd: 1.5.0 [pfSense] |
Wizard time.
There are a lot of options in step three. This is not like Pi-hole at all. I’m going to come back to this and set up my network instead so I can retire my Nighthawk R700—or give it new life as a Wi-Fi AP.
pfb_dnsbl service won’t start or the status tab shows [ Missing CRON task ], try deleting the empty file /var/run/booting (ref).Isolate LANs for Security
An opportunity presents itself: I can create real networks on each of the three router Gigabit ports (not VLANs). Should I do so? Yes—yes, I should. I’d like a dedicated hardware network for all my phoning-home spy devices (Alexas and Apple TV) so they don’t flood my main network with metrics and “sure I’m muted and not listening to you” audio payloads.
I can see it now: a Wi-Fi AP on a hardware LAN that is isolated from everything else, dedicated to these gadgets, and routed through the adblocker and able to trap hard-coded DNS queries to 1.1.1.1, 9.9.9.9, and others (I’ll have to explore this) so YouTube on my TV doesn’t sneakily bypass Pi-Hole any DNS-level blocker. It’s such a utopian outcome I may not be able to sleep.
I’ve decided that my bottom-shelf TP-Link router—so old that “AC1200” might as well be “A.D. 1200”—will become the Wi-Fi AP for those IoT spy devices.
In sum, there will be a dedicated hardware LAN:
- with a wireless AP (AC1200) for Amazon/Apple gadgets and the TV,
- with a wired switch for all the beefy computers and clusters in my lab,
- with another wireless AP (R7000) just for iPhones and watches.
As an aside, since doing an Offensive Security hacking course, I rare-earth-magnet-strongly suggest isolating Wi-Fi devices from any critical LAN segments connected to machines used for daily banking, stock trading, or crypto wallets (aside: don’t trade crypto).
Class B IPv4 172.31.1.0/24 Network for Untrusted Devices
The Class B IPv4 range 172.16/16 is a valid block of private IP addresses. I’m not comfortable with Alexa and Apple TV being on the same network class as my main LAN segment, so I will banish them to the Class B private network at the hardware level, and my more-trusted LANs will stay on the traditional Class C network (192.168/16). This naturally mitigates any misconfigured iptables rules because there are no routes between the two networks.
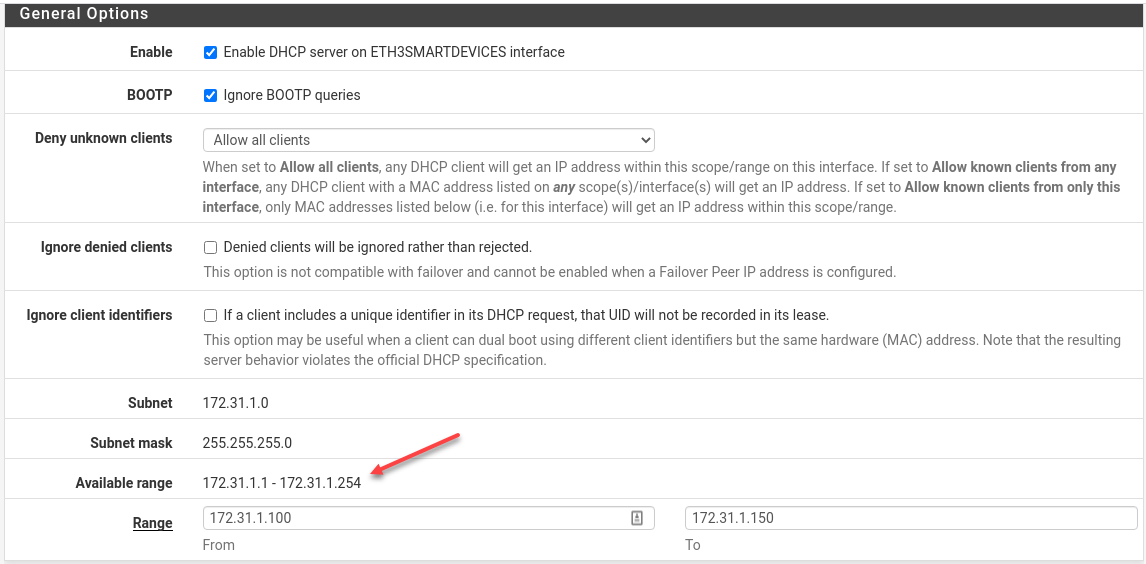
Be sure to enable the DHCP resolver on the physical NIC that will connect smart devices (which mainly just tell me the weather and creepily listen to me sleep).
From this point, DHCP works on this new network, but by default it assigns IP addresses and performs no routing. All traffic is blocked.
Add Firewall Rules
We need to add rules manually so traffic on the physical NICs goes somewhere.
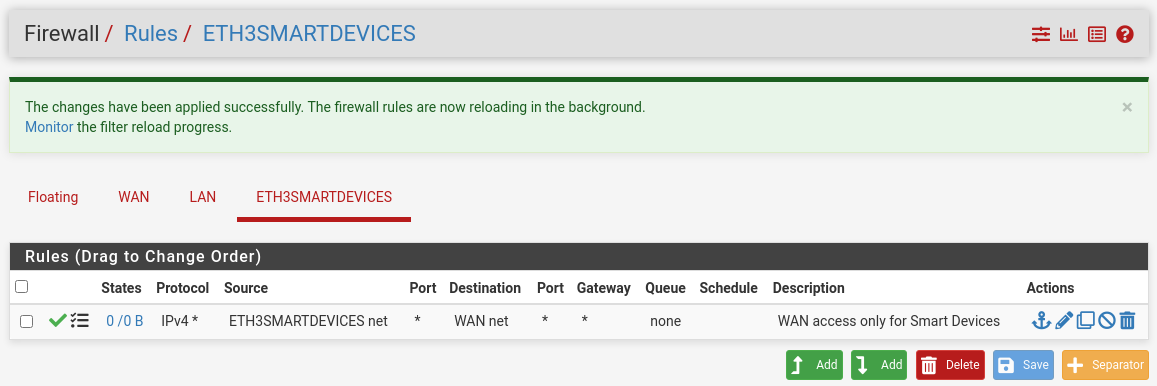
There’s a logging message; let me reproduce it:
Hint: the firewall has limited local log space. Don’t turn on logging for everything.
I read that as: “Congratulations on not cheaping out on your SSD. Now go forth and log everything, my son.”
I’m not a new-age, fancy-jazz, smart-plug–everything guy who forgot how to turn on a light without his phone, so I do not need “smart devices” on the same network as my phone (why create dozens of wireless attack vectors into your home?). I’m classically trained to biomechanically actuate an electromechanical current interrupter on the wall—and light, let there be.
Set Up the Untrusted Wi-Fi AP
How do I reach the admin UI of the AC1200 Wi-Fi AP now? I factory-reset it and plugged the WAN NIC into the ETH3 NIC on the pfSense router, but both devices just blink at me.
I suppose I can Wi-Fi into the factory-reset AC1200. Yikes—2016 was a bad year for responsive web UIs. This is horrible; I’ll pull out a netbook for this. One sec.
It seems the Archer C5 has no AP mode. This is my problem, not yours, but I’m still going to vent.
Oh, and the “refresh” icon at the top of the DHCP Leases page in pfSense is not “refresh”; it’s “reload service.” Whoops.
Well, I bricked the AC1200 router. I will have to run an Ethernet cable manually… but wait, my thin notebook PC has no Ethernet port and needs a USB-NIC adapter. Happy Friday (sarcasm).
There were shenanigans, but I set the LAN IP of the AC1200 to 172.31.1.100, the ETH3 NIC IP of the pfSense router to 172.31.1.1/24, and configured pfSense’s DHCP service on ETH3 to assign addresses 172.31.1.101–150. What failed was setting the AC1200 to 172.31.1.2; it was unreachable (reason unknown). Oh yes—I had to turn off firewall-y things and NAT Boost, basically dropping this TP-Link router’s power to that of a potato battery. The settings above let me access the AC1200 remotely now.
The other video ended, so I started following this YouTube tutorial (set playback speed to 1.5x).
One more thing: I installed the nmap package for pfSense, scanned the AC1200 router, and found some sneaky ports open.
1 2 3 4 5 6 7 8 9 | Running: /usr/local/bin/nmap -sT -P0 -e igb1 '172.31.1.100' Starting Nmap 7.91 ( https://nmap.org ) at 2021-11-15 17:40 PST Nmap scan report for 172.31.1.100 Host is up (0.0017s latency). Not shown: 969 closed ports, 28 filtered ports PORT STATE SERVICE 22/tcp open ssh 80/tcp open http 20005/tcp open btx |
Port 20005/tcp is a print-server port that I’ve now closed. However, the Archer C5 AC1200 is vulnerable to all kinds of Kali mischief, so it was wise to put it on its own network. I’m not sure how to close port 22 and the sshd service on the AC1200 because the stock firmware is ancient and crippled, so I’ll just block port 22 for the whole LAN segment.
I’ve also disallowed private networks from ingressing on the WAN (see the next section for setting up a DMZ).
Unable to Reach 172.31.1.x from 192.168.10.x
Ping and Traceroute are aiding my efforts to reach the AC1200 Wi-Fi AP from my Trusted LAN. I went ahead and added the subnet to the Symantec firewall rules just in case (Symantec has its place now and then—and yes, I have spare PC CPU horsepower).
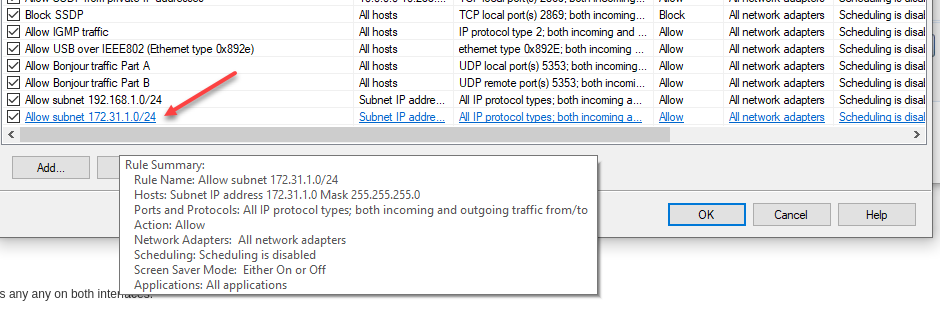
Now, ICMP packets are no longer blocked between networks, but I still can’t reach the AP’s web UI—even though I see the pings in the traffic logs.
I’ve even added an “any to any” firewall rule on the Untrusted network. No change.
nmap as I did, software firewalls may detect the port scan and suspend your network connection for an hour by default.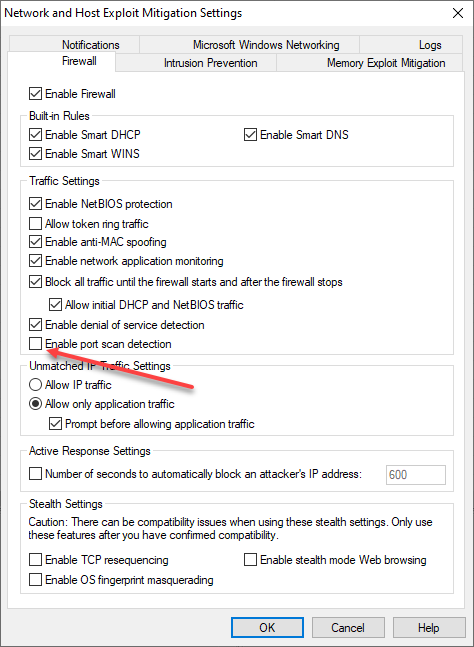 [/note]
[/note]
Let’s try a stealth scan instead: sudo nmap -sS -v 172.31.1.*.
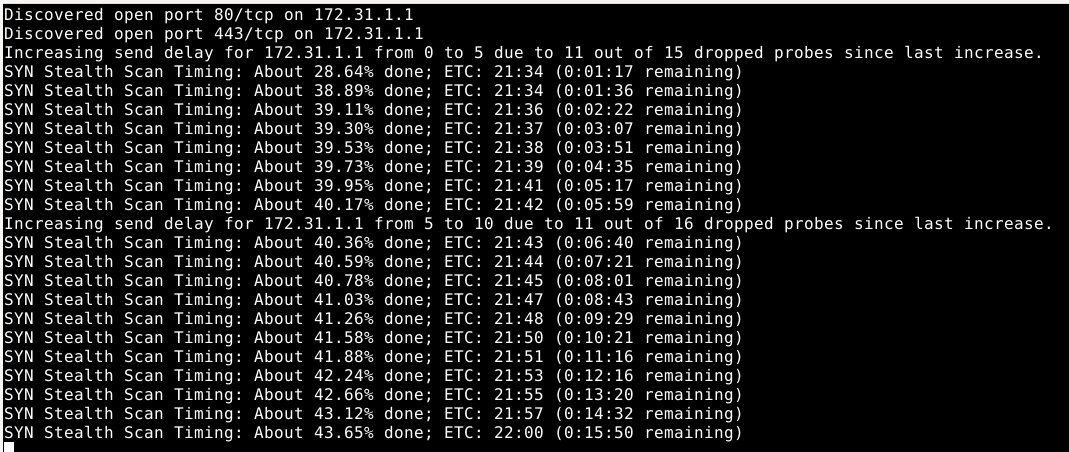
Nope, pfSense doesn’t like that at all. And the whole network stops working. Nice security! Also, dang.
The good news is that I’ve isolated the packet malaise to the TP-Link AC1200 box itself. I suspect I need to add net.ipv4.ip_forward=1 to forward packets with no addresses in them, but I’d need root access to the AC1200. Let’s burn it to the ground and rebuild from its sprinkler-soaked ashes.
Replace Stock Firmware on the AC1200 Wi-Fi Access Point
Of course, I cannot actually stop Untrusted LAN devices from reaching the AC1200, as they all exist downstream from the pfSense box.
DD-WRT open-source router firmware, meet my ancient Archer C5 and do your thing.
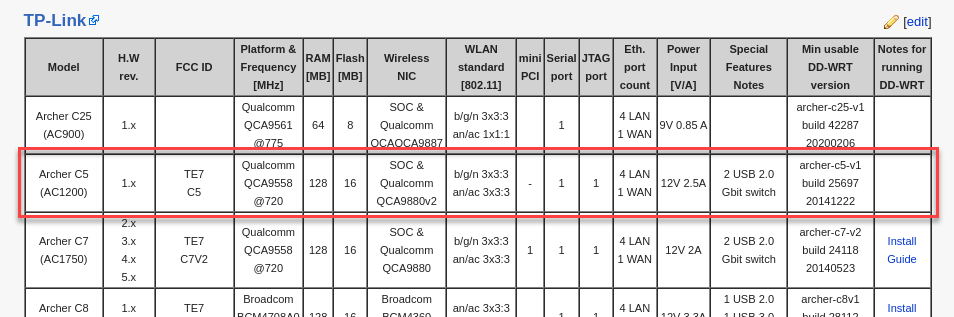
The Archer C5 doesn’t accept the DD-WRT firmware. Hmm… how about OpenWRT?
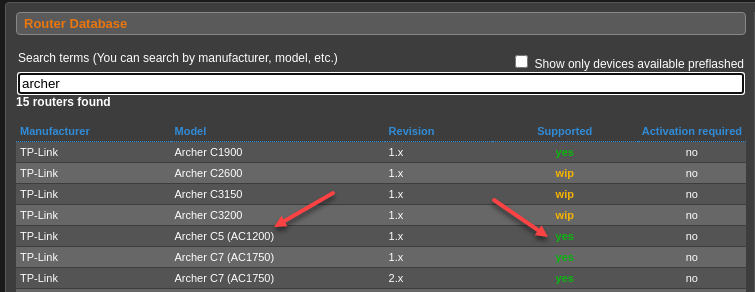
The Archer C5 doesn’t accept the OpenWRT firmware either. What the actual facepalm (WTAF)?
Wait. My hardware is revision 2 using Broadcom chipsets, which are notoriously difficult networking chips.
Alright—OpenWRT, DD-WRT, and Tomato all have no firmware for this AC1200 with unpopular Broadcom chipsets. Into the refuse bin it goes.
Archer C5 v2 Into the Refuse Bin, R7000 as the New Wi-Fi AP
I’ve dismantled the AC1200 so I don’t forget why I threw it out. It’s too bad because it’s so pretty on the inside, and they always say, “It’s what’s inside that counts… except if you are a router with Broadcom chips.”

The R7000 is factory-reset, and here is the first problem:
The R7000 is in AP mode, but I can still access the pfSense web management page from the Untrusted network. Let’s lock down the web UI in pfSense under Firewall Rules.
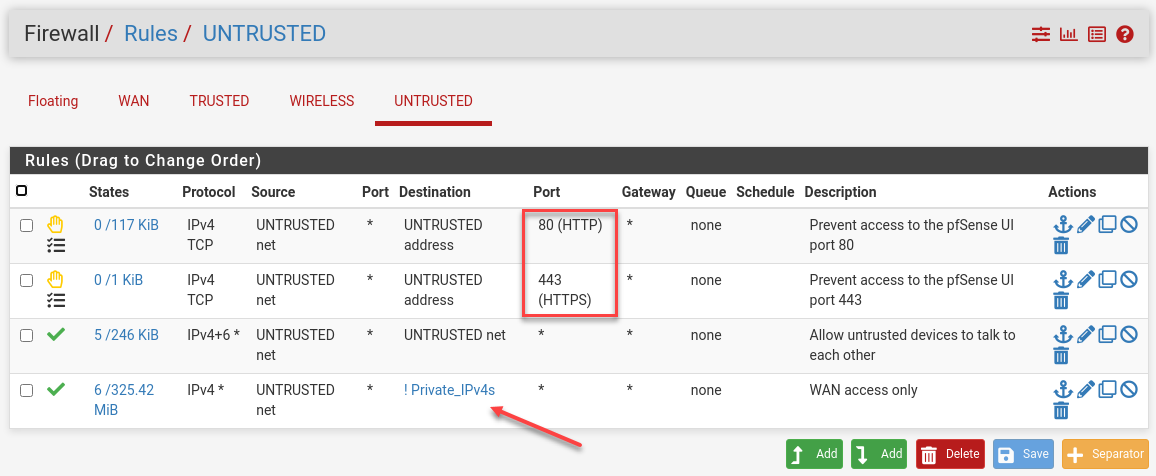
Set up the Trusted Wireless Network
The Untrusted network is now looking good. It’s time to make the other R7000 Nighthawk I have into a Wi-Fi AP as well, so my phone and watch have a safe place to connect—plus a laptop when I want to RDP into my wired machines from the kitchen. I was saving that for a honeypot AP, but I can come back to that later.
Let’s see if I can Wi-Fi into the Wireless LAN’s R7000…
Since only my trusted devices should be on the Wireless LAN, I’ll turn off 2.4 GHz Wi-Fi because anything recent and wireless should support 5 GHz. That means those pesky AliExpress Pineapple Wi-Fi password stealers on the cheap side only use 2.4 GHz, so a neighbor will have to put in some effort to snoop on my network. Plus, 5 GHz gets blocked more easily by walls and concrete, so I prefer it for averting medium-range snooping. But I am so going to set up a honeypot and brake-check my faith in humanity.
It’s normally straightforward to put a Wi-Fi router into AP mode by disabling WAN and DHCP.
Network Devices Interconnectivity Check
Do all my dozens of computers, laptops, Pis, clusters, NAS drives, and the like still connect as before? Most important is my web-scraping bot in a hardened, RAIDed, dedicated machine with its own UPS. But alas, I cannot SSH into it even though the SSH handshake packets reach the hefty box.
Could this be our old frenemy IPv4 forwarding being disabled? Possibly. I’m able to SSH into the machine from my iPhone (seriously) when on the same network.
Nope. Adding net.ipv4.ip_forward = 1 in the right place with a restart did not yield joy.
According to dmesg -w (to tail dmesg logs), UFW (Uncomplicated Firewall) is not blocking ICMP requests or TCP requests on port 22. When I do something nutty like try to SSH on, say, port 23, I do see UFW block logs in dmesg. Confirmed: packets can reach that machine.
Running tcpdump src 192.168.10.100—the IP from the Trusted network on the target machine—shows it is responding to pings. I’m even getting replies to SSH handshake requests. So now we know that return packets are being dropped. Interesting! Aside: tcpdump is awesome.
Let’s follow the trail. Digging a little deeper, I see replies to ICMP and SSH handshakes being sent to some IP over HTTPS that I don’t recognize. Bizarre. When I run the usual ipinfo tools I see that replies are going over a VPN that I completely forgot about. Ha—replies to a different subnet are egressing over the VPN but cannot return properly. Neat.

Now that I remember what I did in 2019, I re-added NAT alias rules, and it’s showtime again.
Windows File Sharing Gotchas
Your path may be smoother, but I always seem to make the Trench Run—remote-piloting a handful of lead-filled X-Wings at light speed right through the Death Star’s reactor to make it go boom: the easy way.
I’ve added rules so static-DHCP Windows devices can talk to each other, but by default the Private Network profile in Windows Defender Firewall scopes rules to the local subnet. That isolates different subnets. We cannot simply relax the pfSense DHCP subnet mask to, say, 192.168.20.0/16; it conflicts with another subnet. Instead, just to get file sharing working, I relax the scope in Advanced Settings as shown below. Be sure to modify both Inbound and Outbound rules for SMB and ICMP.

Again, add whatever subnets you need instead of any.
Public Service Announcement: Edge Browser
Why does Microsoft Edge start automatically and keep running in the background, and why can’t I kill it with Ctrl + Alt + Del? If you’ve asked yourself this, you’re not alone. Edge launches at login and sticks around. Here’s the fix:
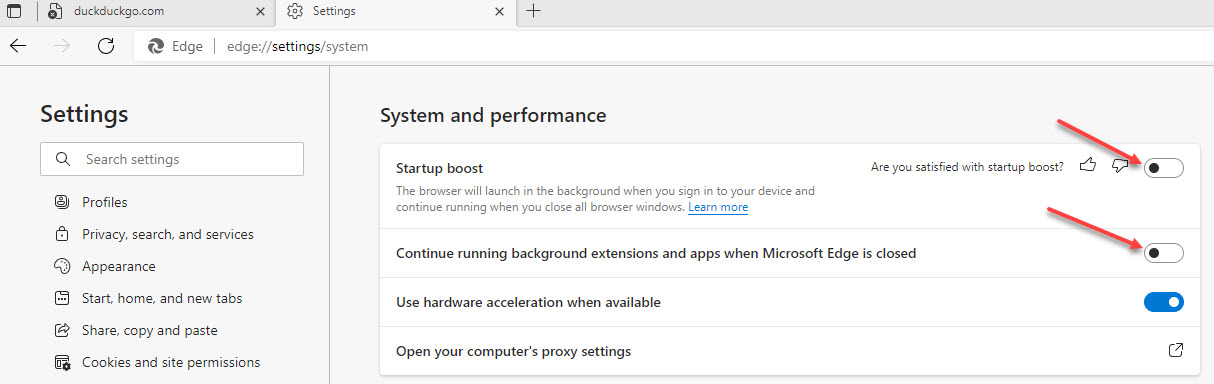
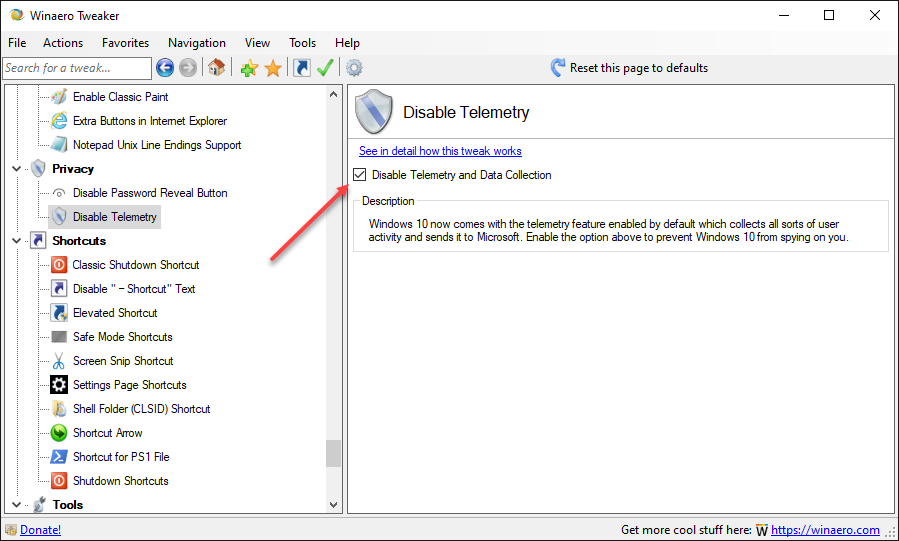
I suggest downloading Winaero Tweaker and applying its registry tweaks to tone down the Redmond Spy Machine.
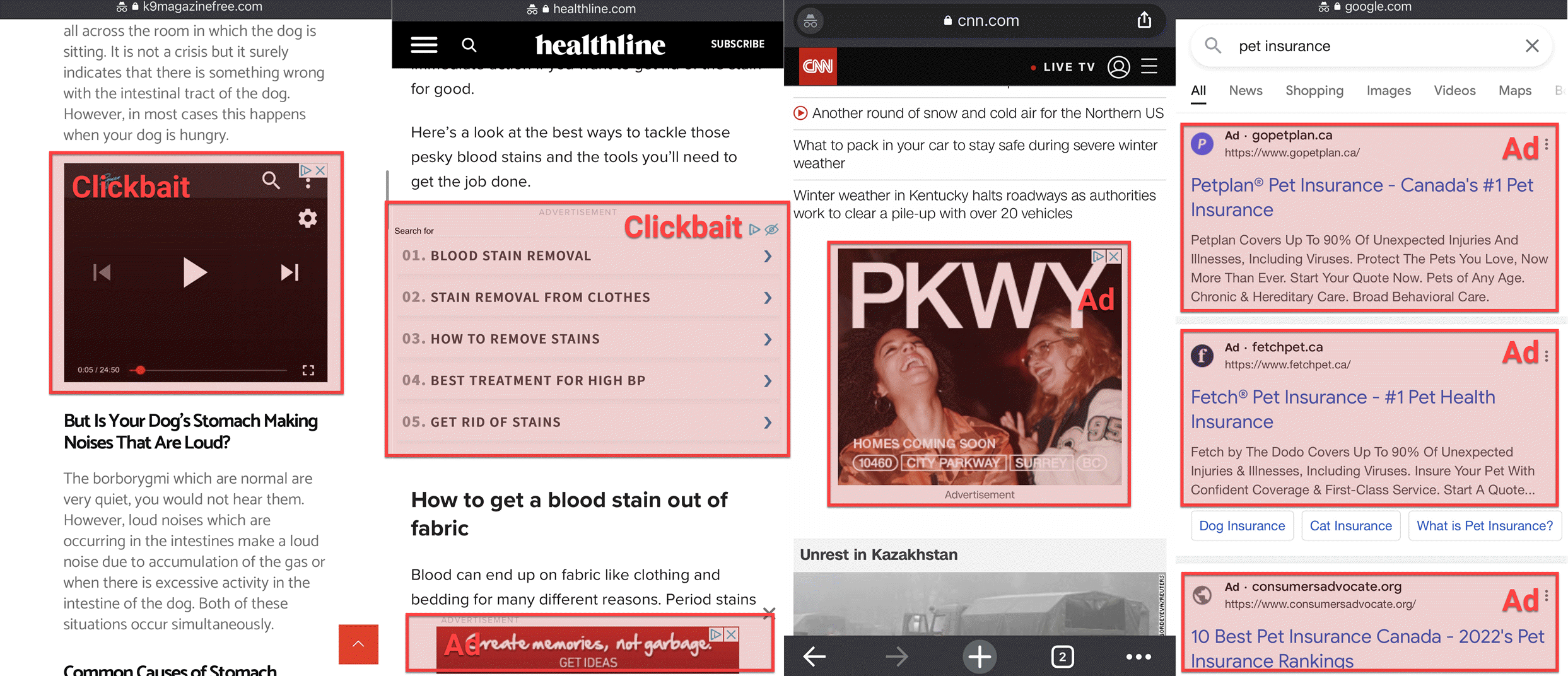
Block Clickbait, Endless Ads, and Dangerous Sites
Thanks to web-browser and DNS-level adblockers (e.g., Pi-hole), it’s commonplace to block bad sites, crypto-miners, fingerprinters, trackers, remarketers, banners, pop-ups, fake tech-support alerts, and all manner of unscrupulousness designed to take advantage of you. Let’s take pfBlockerNG on pfSense for a spin.
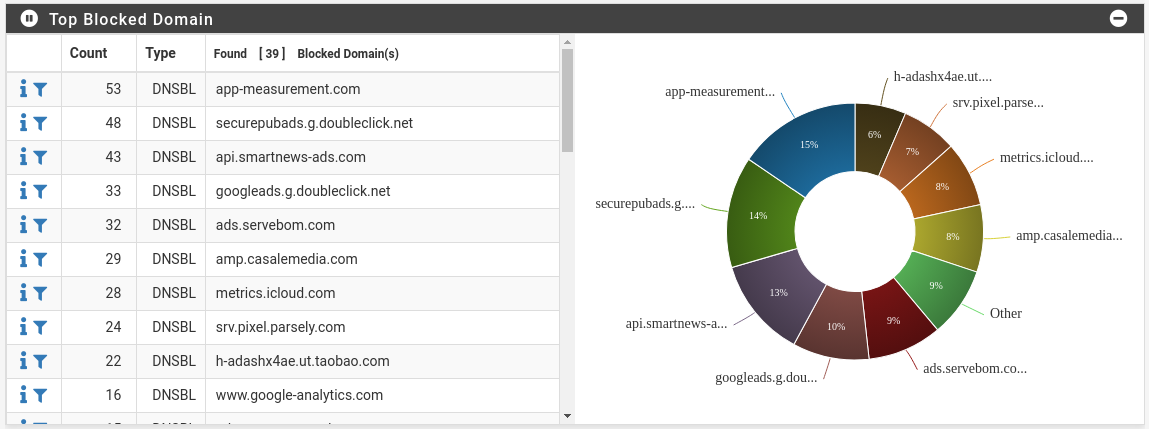
The pie chart looks great. I followed this pfBlockerNG tutorial.
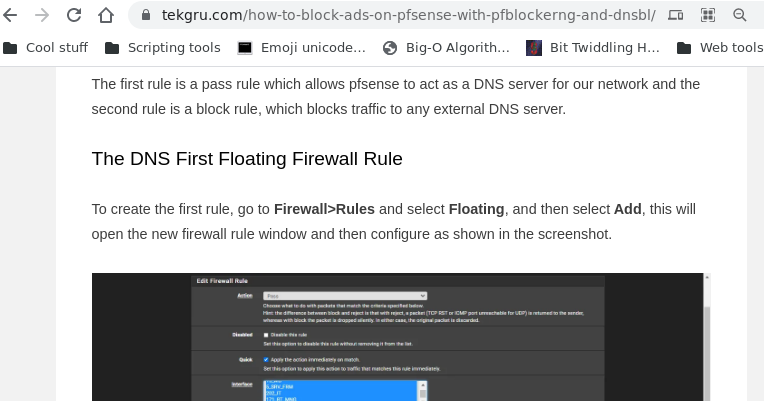
This is important: If you have multiple network interfaces (the mini PC has four), then you need to enable the Permit Firewall Rules option for multiple interfaces and select them.

Want discretion over blocklists? Let’s add a DNS blocklist related to gambling and reload pfBlockerNG to see whether a poker site is blocked on the Trusted LAN.
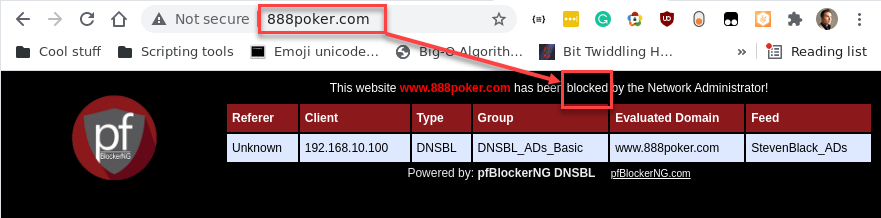
If you prefer the connection to close silently instead of rendering a PHP page, create a new PHP script with the following code and select it in the pfBlockerNG settings page:
1 2 3 4 | <?php # nano /usr/local/www/pfblockerng/www/killed.php ignore_user_abort(true); fastcgi_finish_request(); |
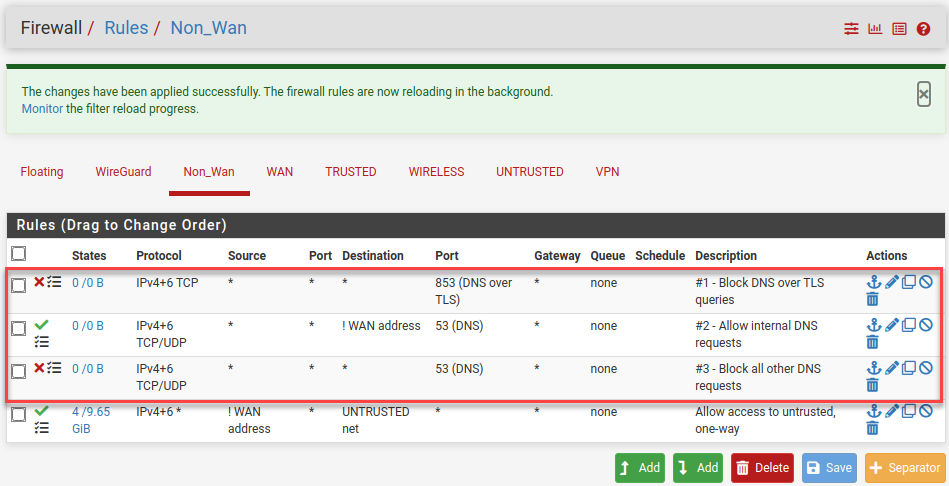
Intercept All DNS Requests, Even to Hard-coded DNS Servers
Let’s make sure all clients behind the pfSense router use the local Unbound DNS server so pfBlockerNG can act on them. We do not want apps and home assistants to bypass our DNS server, so we have to add some NAT rules.
First, we have to block DNS over TLS (for now) and allow only local DNS requests (note the rule order):
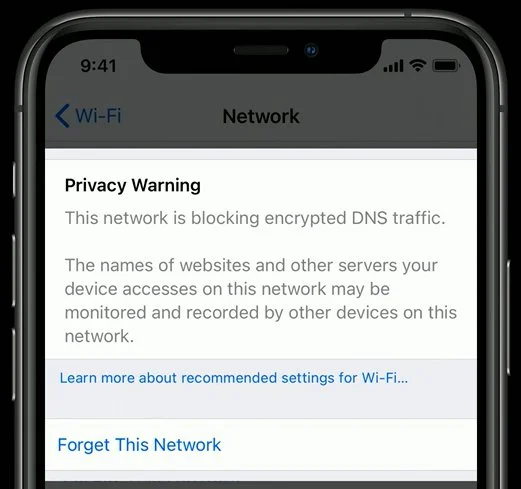
Here is a NAT rule for one interface. I started by making a rule for each interface except WAN (obviously) like this:
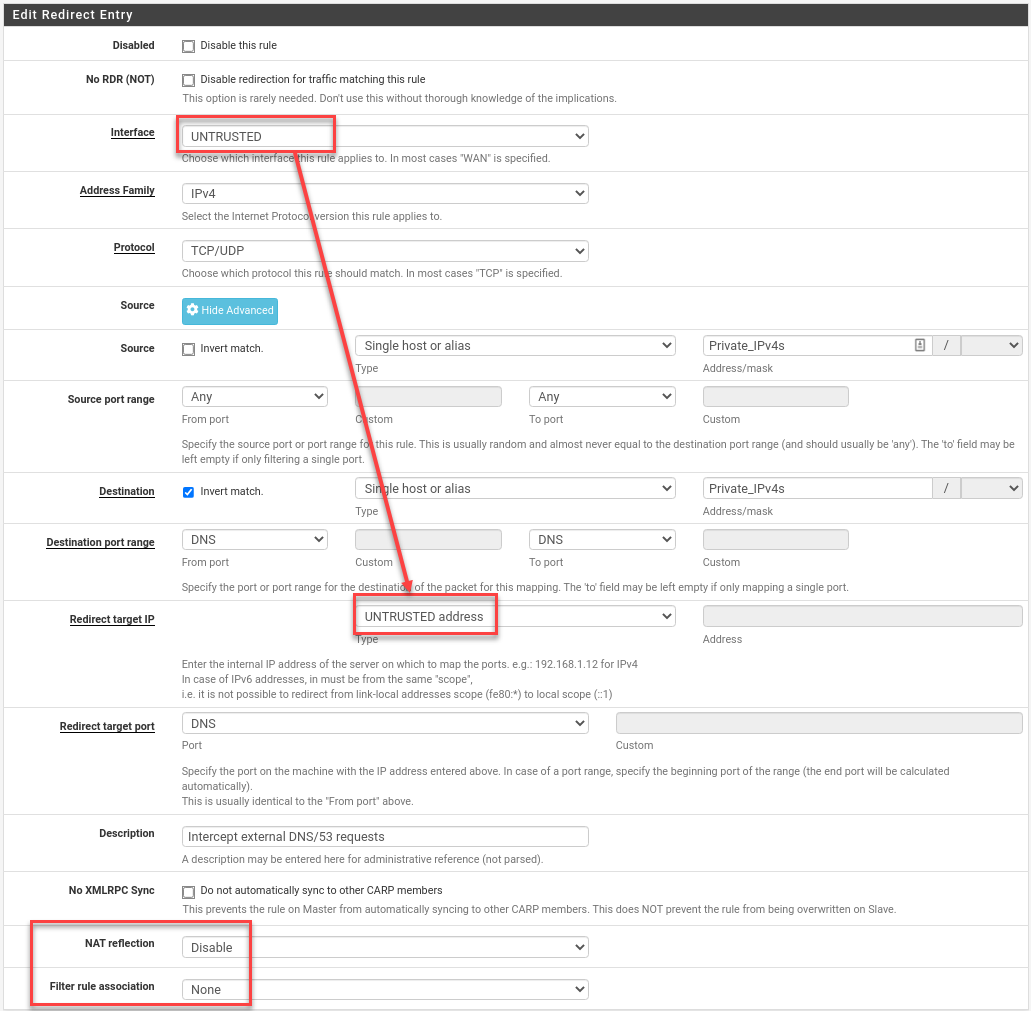
To make life simpler, I created a firewall alias of all non-WAN interfaces called Non_WAN. Covering IPv4 and IPv6, the redirect rules that send local DNS queries on port 53 to localhost look like this:

Let’s also log trapped DNS requests. Head to the Services › DNS Resolver page, click Display Custom Options, and add:
1 2 | server: log-queries: yes |
Well, hello there, Microsoft Windows. What are you up to trying to reach Google Tag Manager? Naughty OS. That request is now black-holed to a non-existent IP at 10.10.10.1.
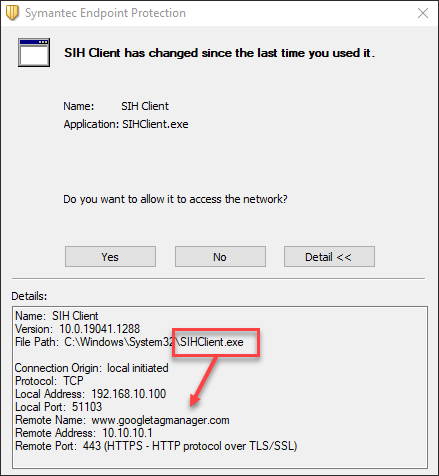
Let’s turn our attention to the TV and see how it fares under DNS interception.
How to Restrict Apple TV and iPhone YouTube Ads?
YouTube is tricky because ads are also videos that arrive from the same domain, so domain-name blockers like pfBlockerNG can’t filter them. The best pfBlockerNG or Pi-hole can do is block googleadservices.com—and only after you watch an ad video and click the ad.
Many people use a web browser such as Firefox or Chrome with uBlock Origin, which acts on JavaScript. It may be enough to watch YouTube in a browser and cast it to a so-called Smart TV. However, we can’t restrict ads in the iPhone YouTube app (without jailbreaking and compromising the device).
What are our options? How can we safely restrict YouTube ads on all network devices?
Trick the YouTube Ad Algorithm Instead
What do ads in other parts of the world look like? Are people living in Antarctica or low-Earth orbit getting lots of ads, too?

What if we leverage this pfSense router to route YouTube location-tracking traffic through a VPN that terminates in some remote part of the world with fewer YouTube viewers per capita? In other words, let’s make ourselves undesirable to advertisers and see whether we get fewer ads.

Research into YouTube Advertising Spend
Let’s do some YouTube demographics research to find a part of the world avoided by advertisers.
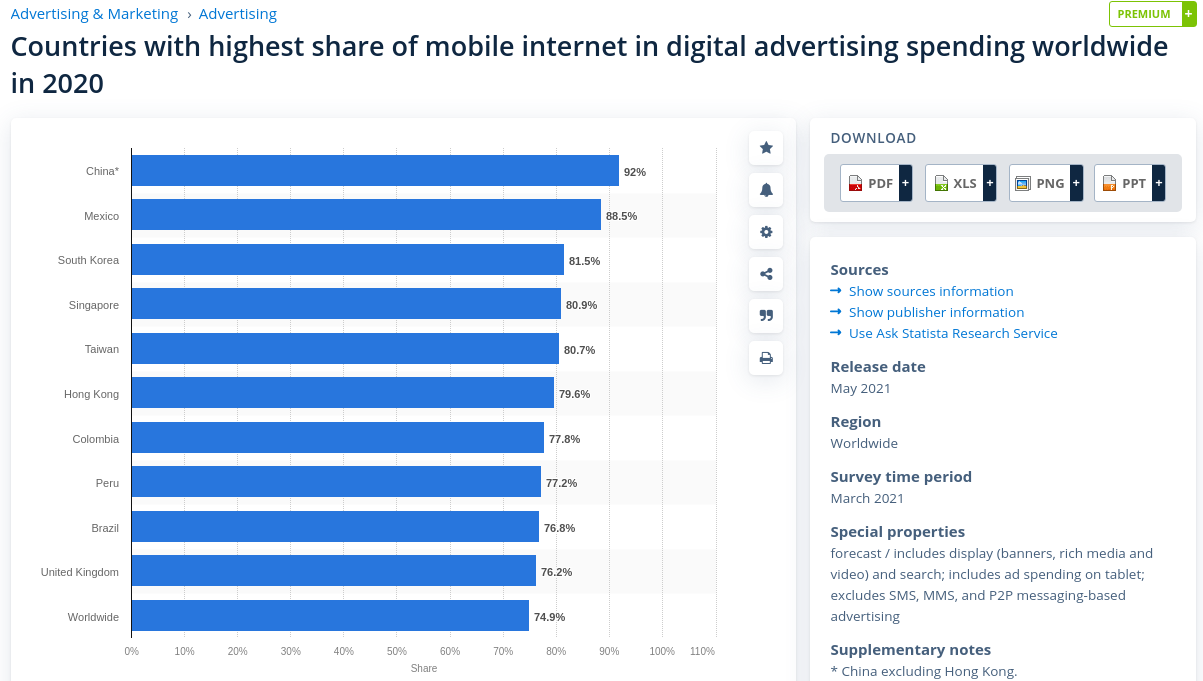
Let’s also check some YouTube statistics about viewers by country for insights. Thinking about following some Reddit advice and VPN’ing into India? Think again.
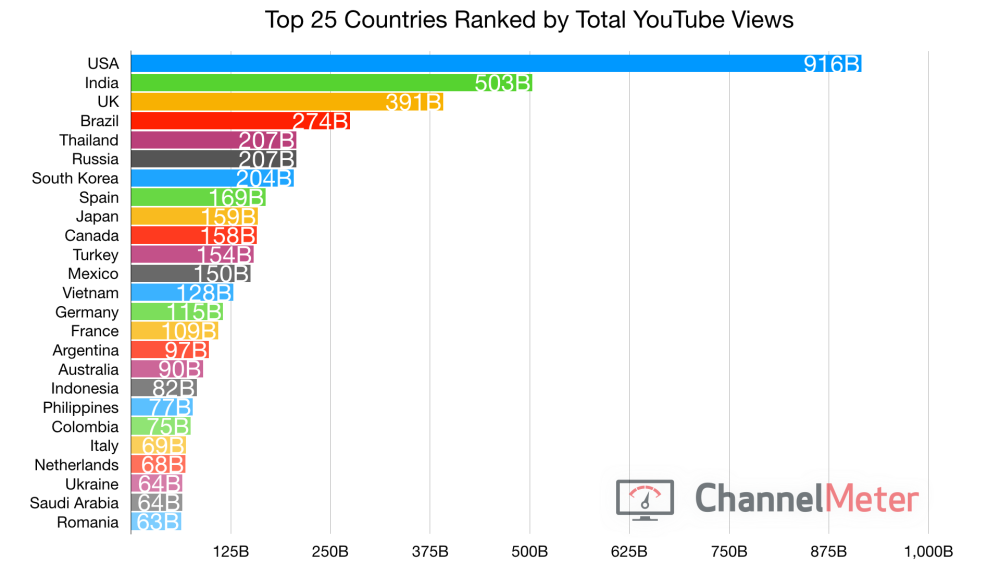
That was 2019. This is 2020:
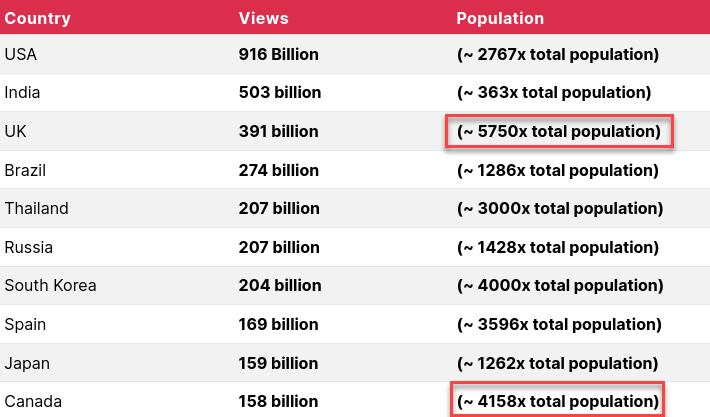
I’m not a digital advertiser, but I can see that people in the UK and Canada watch a large number of videos per sitting. If I were an advertiser, I’d pump those two countries with video ad after video ad because, statistically, those residents will take the eyeball kicking. All things being equal, I definitely need a VPN to terminate outside of Canada, the UK, and the United States (English-speaking countries) to enjoy YouTube more.
Does age play a factor? Who don’t advertisers want? I want to be that guy on paper.

How, then, to convince YouTube that I am a retired Sicilian living about a small chain of islands? I embellished that last part—seventy and in Italy is sufficient.
Let’s do this. In the YouTube account…
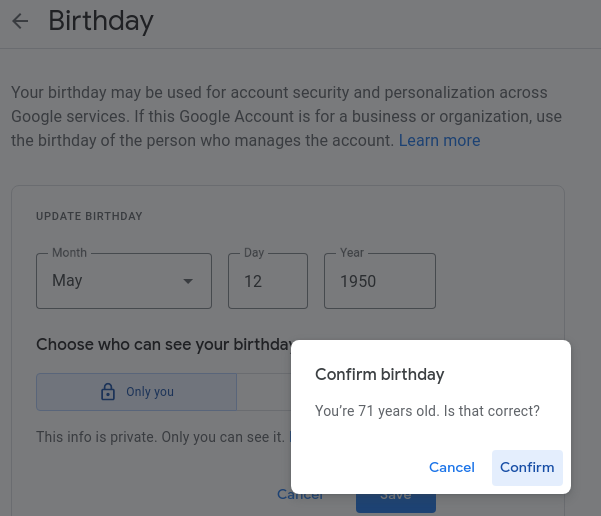
It is doubtful this is all it takes for our goal. Let’s find a VPN exit point in Italy.
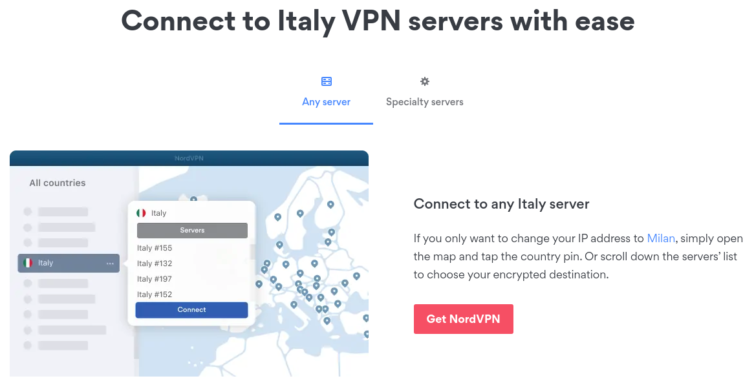
Nice. NordVPN, for example, has about 60 servers in Italy.
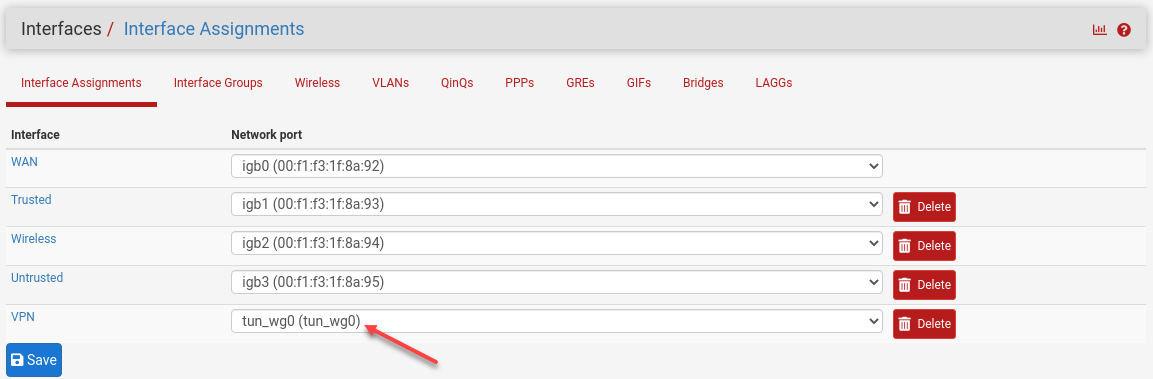
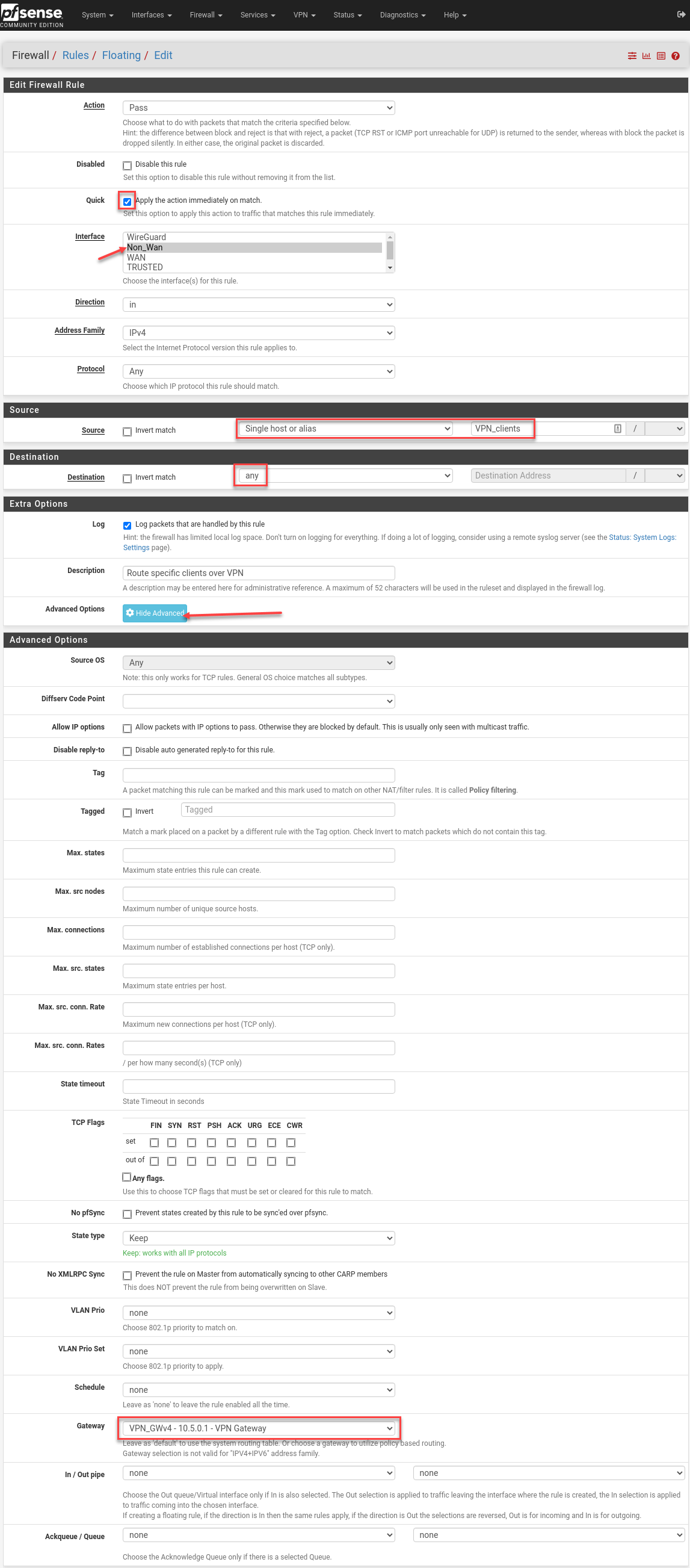
Selectively Route Apple TV Over the VPN
Let’s go through some tutorials to set up OpenVPN in pfSense. Just kidding! We’re going to use WireGuard—after all, we have the Intel AES-NI instruction set because we didn’t go cheap and buy a J1900 mini PC that sellers are trying to off-load.
I’ll now install the FreeBSD WireGuard package.
Next, add a tunnel and enable it. According to this thread and this thread on Reddit, we need to grab some WireGuard and NordLynx details—specifically the private key—from a sacrificial Linux VM and transpose those settings to the pfSense router. No problem.

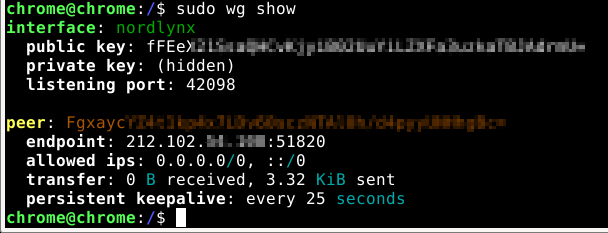
wg showRun sudo wg showconf nordlynx on the VM to see the private key needed for the pfSense tunnel configuration.
Here are various screenshots that show the steps in more detail.


1.0.0.0, then set the subnet mask to 0. Don’t choose 0.0.0.0; there’s a glitch or bug in the UI—or what-have-you. The result will still display as 0.0.0.0/0.
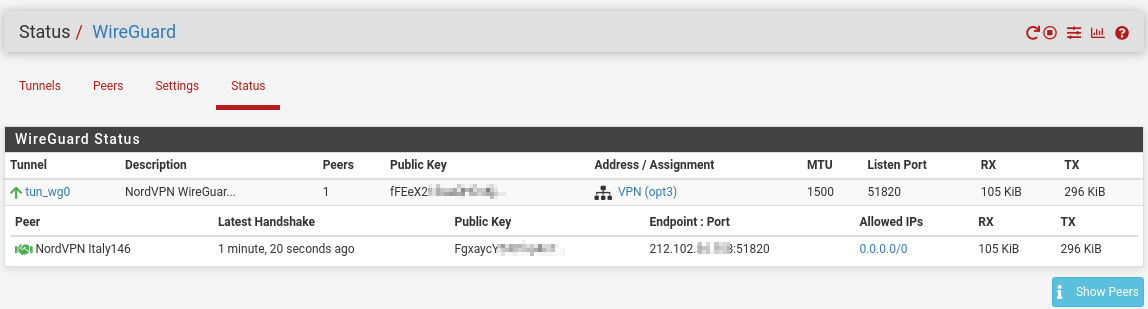
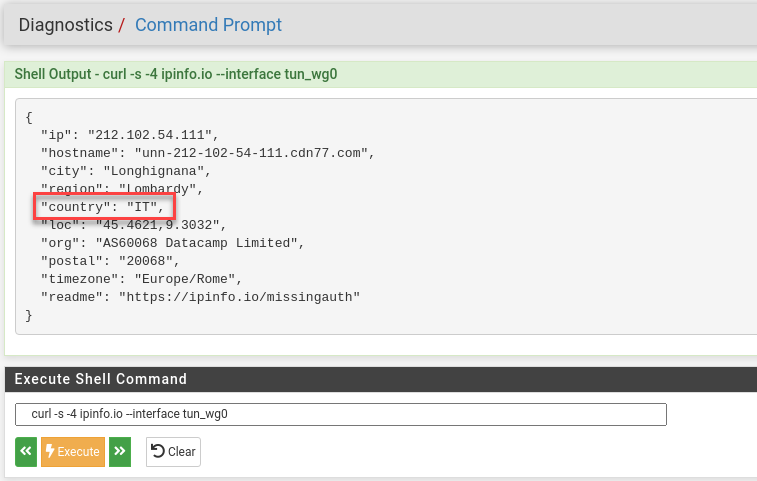
That should be enough to let Diagnostics curl to Italy.
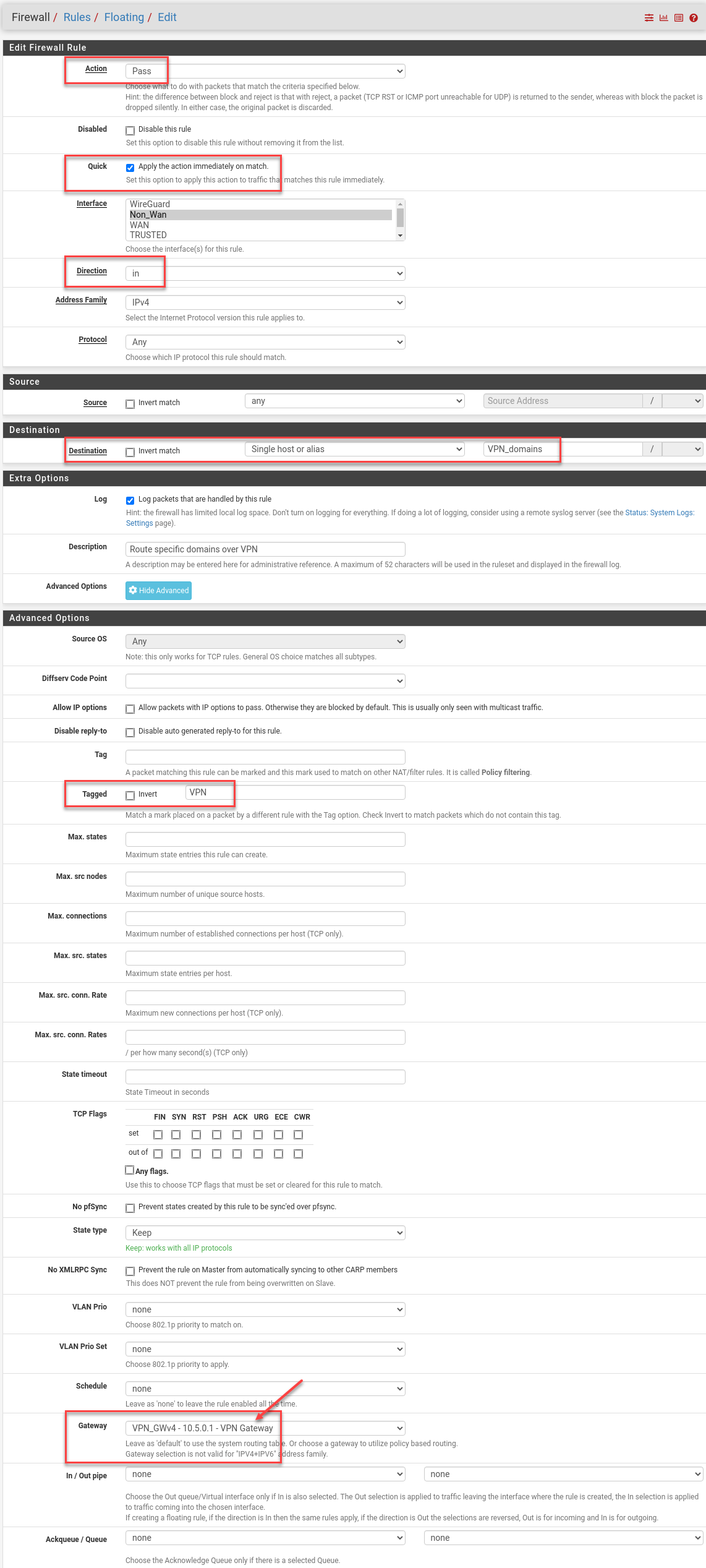
Now that the easy part is out of the way, let’s set some policy rules to send Apple TV traffic over the VPN to Italy as a baseline test.
From Netgate, on the order of Firewall/NAT processing:
Traffic from LAN to WAN is processed as described in the following detailed example.
– Port forwards or 1:1 NAT on the LAN interface (e.g., proxy or DNS redirects)
– Firewall rules for the LAN interface:
– Floating Inbound rules on LAN
– Rules for interface groups that including the LAN interface
– LAN-tab rules
– 1:1 NAT or Outbound NAT rules on WAN
– Floating rules that match outbound on WAN
I’ll make an alias, for now, to hold some clients that have static-DHCP entries and hostnames I assigned in pfSense.
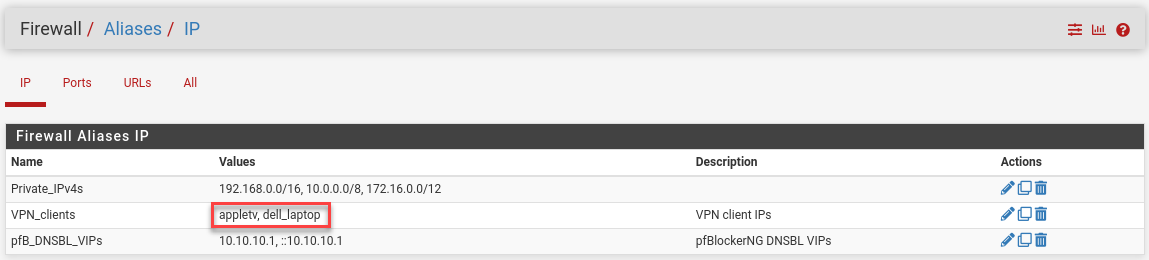
Floating rules in have high precedence, so I add new entries below the automatic pfBlockerNG rules and drop in a blue separator while I’m here.
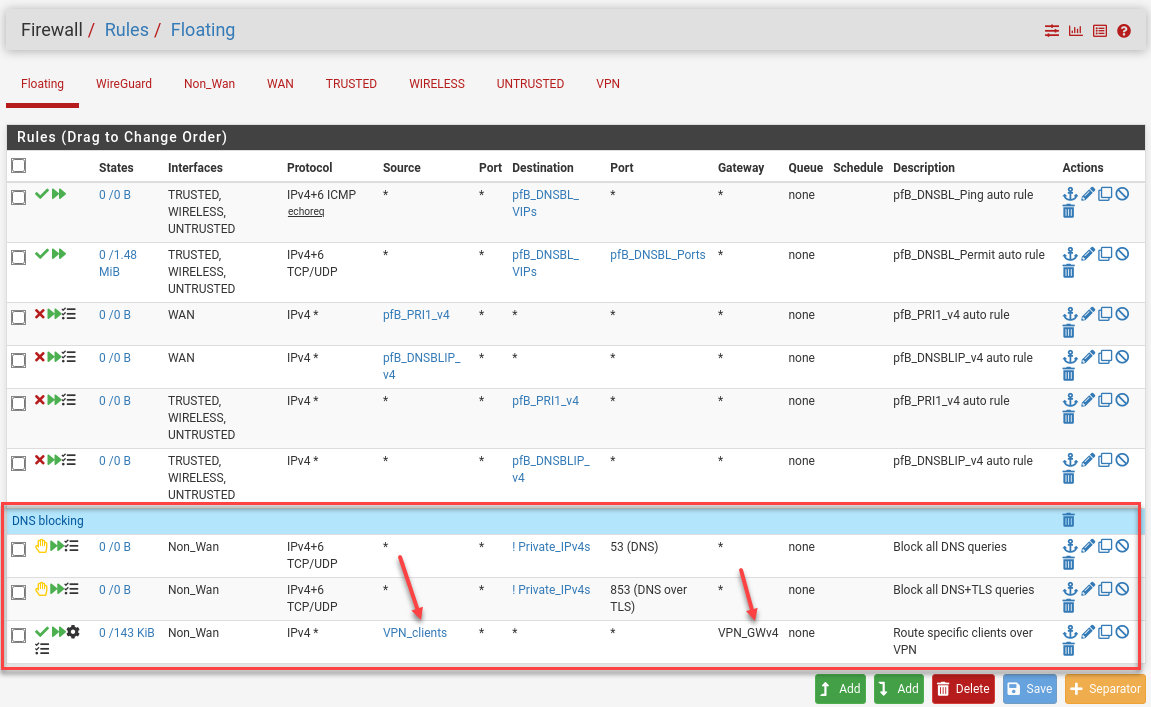
And here’s the full rule as a tall screenshot:
Apply. Wait. Time to test with a notebook on the Untrusted network.
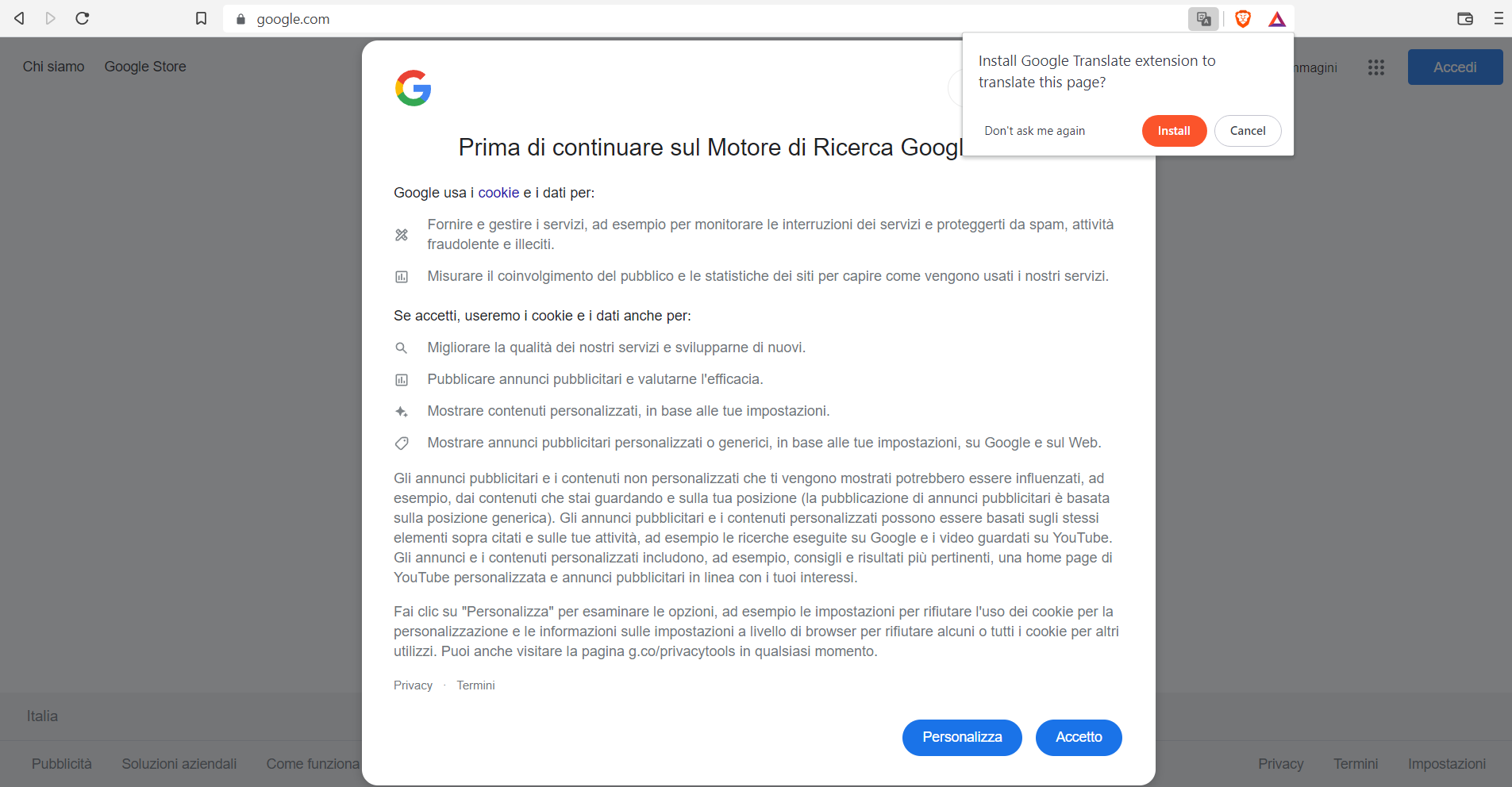
Google appears in Italian—very cool. Now for the Apple TV.
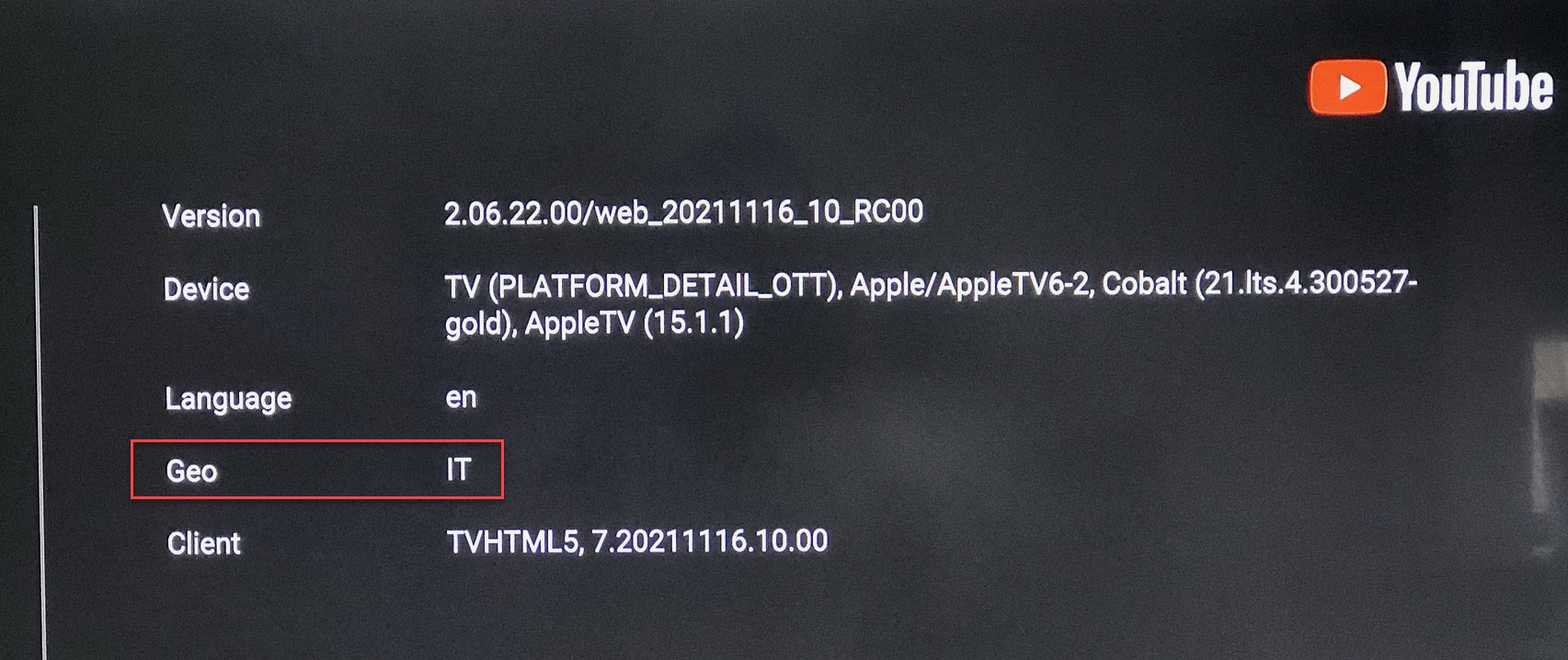
Winner winner, chicken dinner. All my YouTube is in Italian. I still get some ads—fewer than before—and because Italians speak slowly and with a kind of charming accent, I don’t mind the Nutella spots at all.
With this technique I no longer feel manipulated by English-language ads. I have personalized ads off, but given my new status as a retired gentleman I should turn that back on to scare away advertising euros. I wonder whether Netflix and Amazon Prime behave differently…

Dang. Netflix is having problems. Amazon Prime is even worse. It looks like some CSS or font files are blocked, and the thumbnails aren’t loading. Time for Phase Two: tunnel only YouTube traffic over the VPN.
Selectively Route Apple TV YouTube Traffic Over the VPN
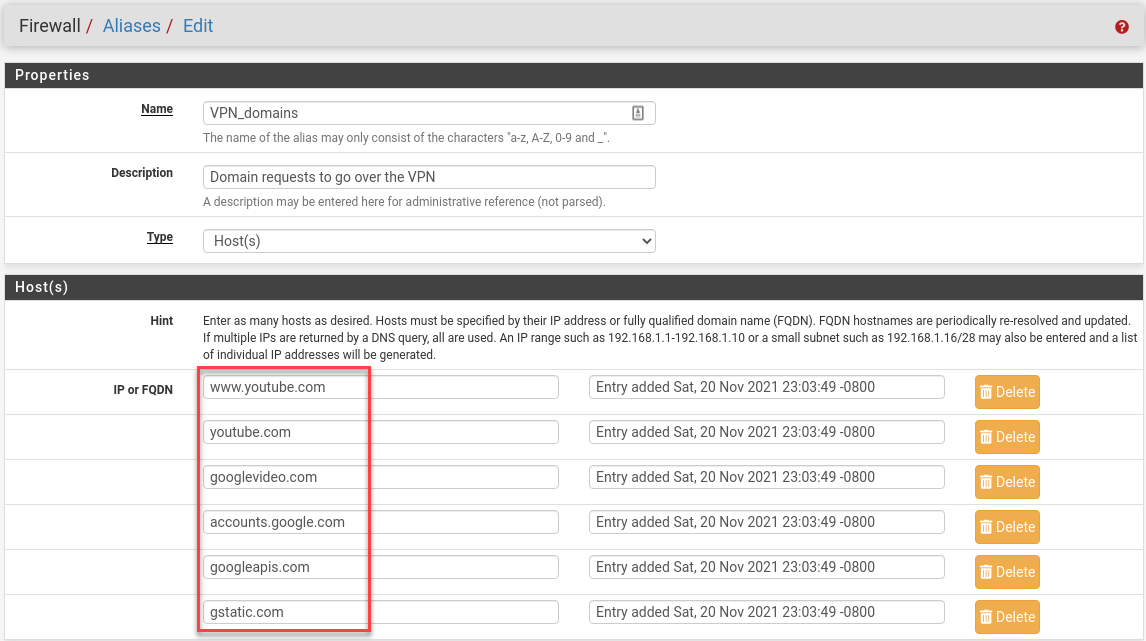
Let’s start by adding firewall-policy rules to send the most common YouTube domains over the VPN.
As I’m about to add the rules, my hands hover over the keyboard—I don’t yet know which domains to tunnel. They must be FQDNs (fully qualified domain names, no wildcards). Let’s open a Chromium-based browser and watch the traffic in DevTools.
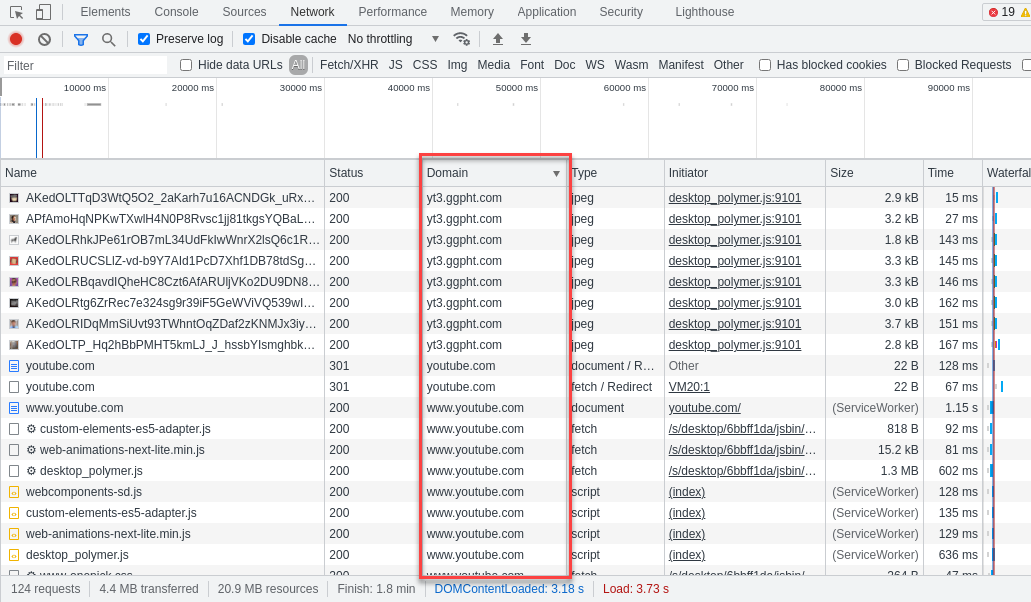
Here are some candidate FQDNs to add:
1 2 3 4 5 6 | www.youtube.com youtube.com googlevideo.com accounts.google.com googleapis.com gstatic.com |
But wait, I hear you ask—why accounts.google.com and gstatic.com? This is a precaution in case one of those domains is geo-checked. I wouldn’t put it past Google engineers to geo-tag the fonts domain (fonts.googleapis.com), but in the interest of performance, I’ll assume they don’t.
Here are my new rules; I chain two of them with a tag so I can limit YouTube tunneling to the same untrusted machines (including Apple TV).


And with that, YouTube thinks I’m in Milan, while Netflix and Prime Video still think I’m in Canada. The ads—oh, the ads—are now few and far between, and when they do appear, they’re a delight in that gentle, hypnotic Italian.
Time goes by…
Gotcha: DNS Race Condition
A day goes by, and I notice I get Nutella and Ferrero Rocher ads only mid-video, not at the start. Odd. Some digging turns up this:

This means that the hostnames are resolved to IP addresses once and those IPs are used in my VPN tunnelling policy rules.
A hostname entry in a host or network-type alias is periodically resolved and updated by the firewall every few minutes. The default interval is 300 seconds (5 minutes) and can be changed by adjusting Aliases Hostnames Resolve Interval under
System > Advanced, Firewall & NAT. — pfSense docs
Ah-ha—this looks like a DNS race condition:
- The Alias Daemon resolves the FQDNs and updates their IPs.
- Hours later I power up the Apple TV.
- Because the DNS TTL is 1,440 seconds (24 minutes), the cached YouTube entries expired.
- Fresh DNS queries run. The new IPs are from a large pool, not guaranteed to match what the Alias Daemon resolved.
- Five minutes later, the Alias Daemon runs again and may resolve yet another set of IPs.
If the policy and the client disagree about which IPs belong to YouTube, traffic can miss the tunnel.
Mitigation: Force pfSense to ignore the target’s TTL and cache the Alias’ entries longer.
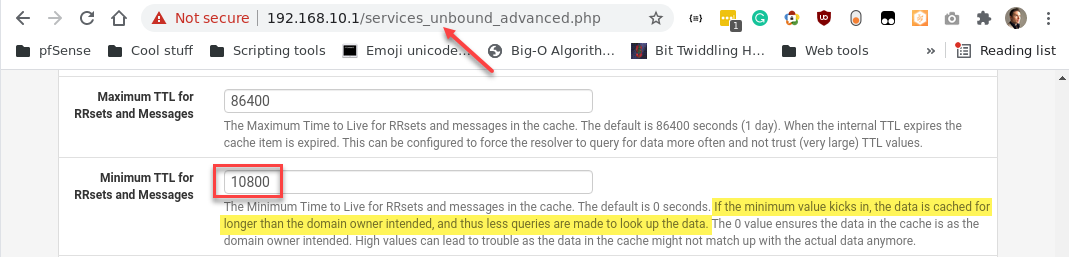
With that tweak, the Alias Daemon and the client stay in sync—no more DNS race condition.
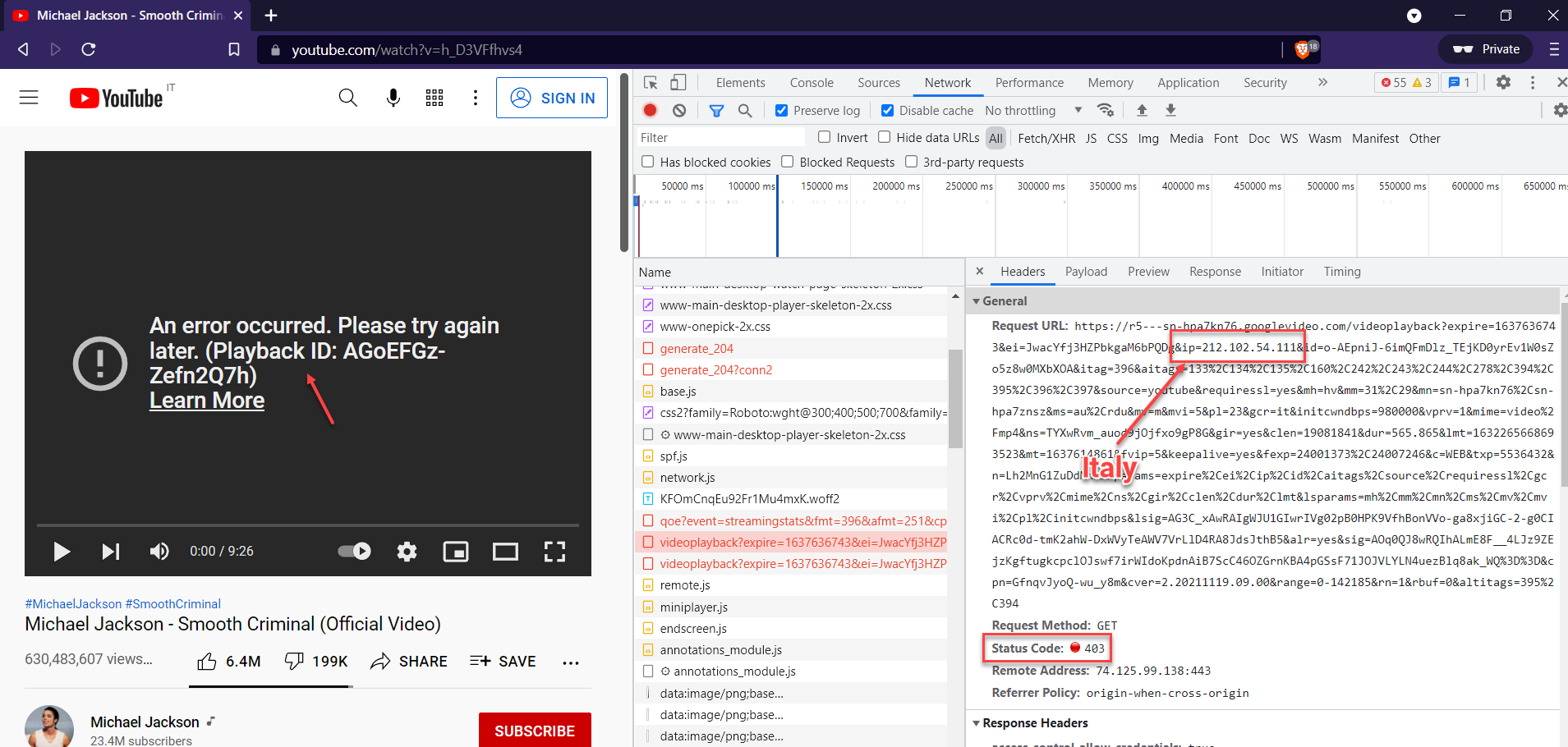
Gotcha: Authentication Trouble, 403 Forbidden Error
Sometimes videos refuse to play. For security, YouTube embeds your IP in each googlevideo.com request. I wrote about this in 2016 in Download YouTube 4K Videos with PHP. The new snag is that various JavaScript and “are you human?” assets tunnel over the VPN, but mangled domains like r5---sn-hpa7kn76.googlevideo.com do not, so they emerge from the wrong IP. Cue the 403 Forbidden error.
Let’s fail fast with a quick experiment: Let’s grab the IP of that second-level domain (SLD), add it manually to the list of VPN-tunneled items, apply, and refresh YouTube.
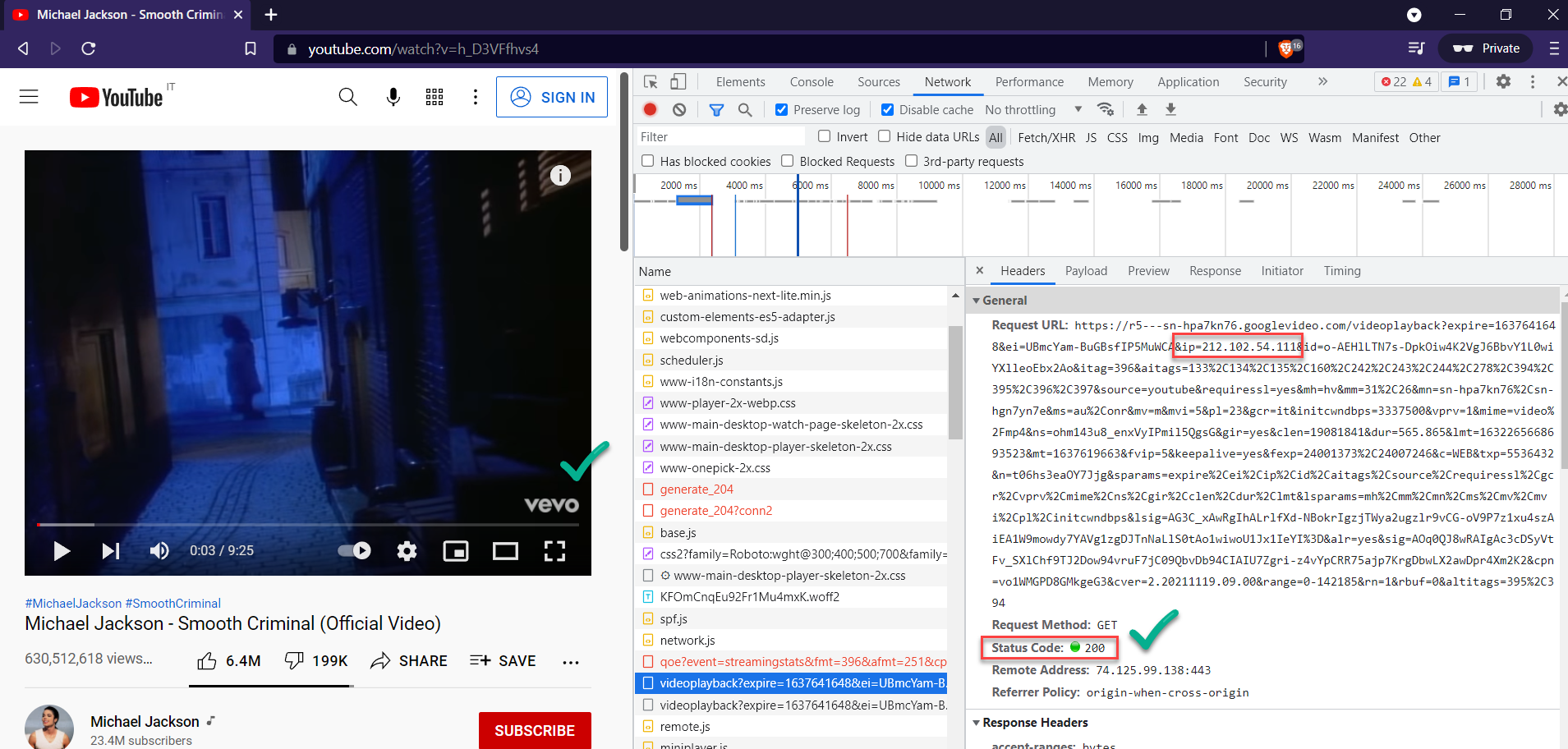
Excellent. Now we just need a way to tunnel the wildcard *.googlevideo.com. Unfortunately, NAT and firewall rules work with IPs, not wildcard hostnames. Can we predict or enumerate these domains?
A Wireshark capture of DNS requests shows the SLDs are hardly predictable:
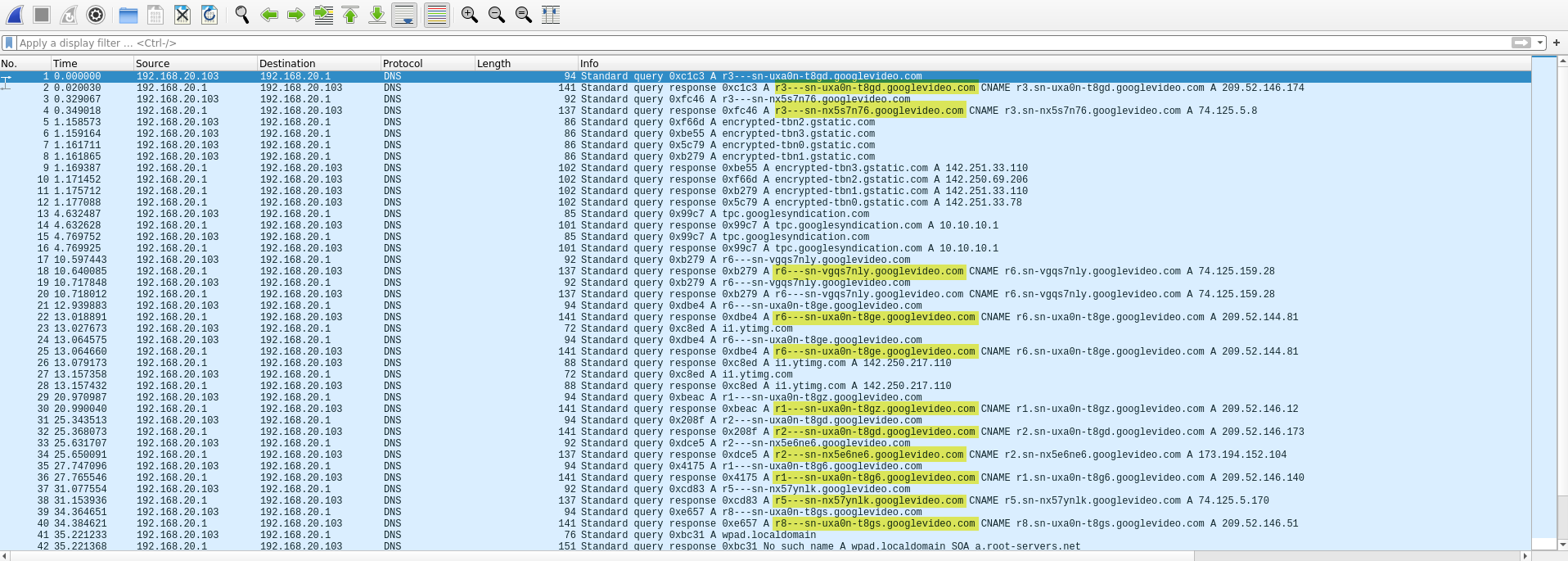
Let’s drop into a browser with adblocking disabled and inspect the HAR waterfall to find my interactions that triggered ads.
What exactly are requests likeGET https://r7---sn-uxa0n-t8ge.googlevideo.com/generate_204
doing? I’ll give this problem some thought offline.
Gotcha: YouTube Is Now Showing UK Ads, Not Italian Ads
Before I can even solve the previous gotcha, British ads start showing up as frequently as if we’d done nothing at all. Ads from the UK are even more incessant than those from Canada, trailing only the USA and India in my earlier stats. It would be a complete failure if we end up with UK ads.
Why does this happen suddenly? I opened a fresh browser in a VM and tunnelled all traffic through Italy. The only leak I found appears when I query ipinfo.io over the Italian tunnel and see a UK address listed in the ASN. Could this small leak be the culprit?
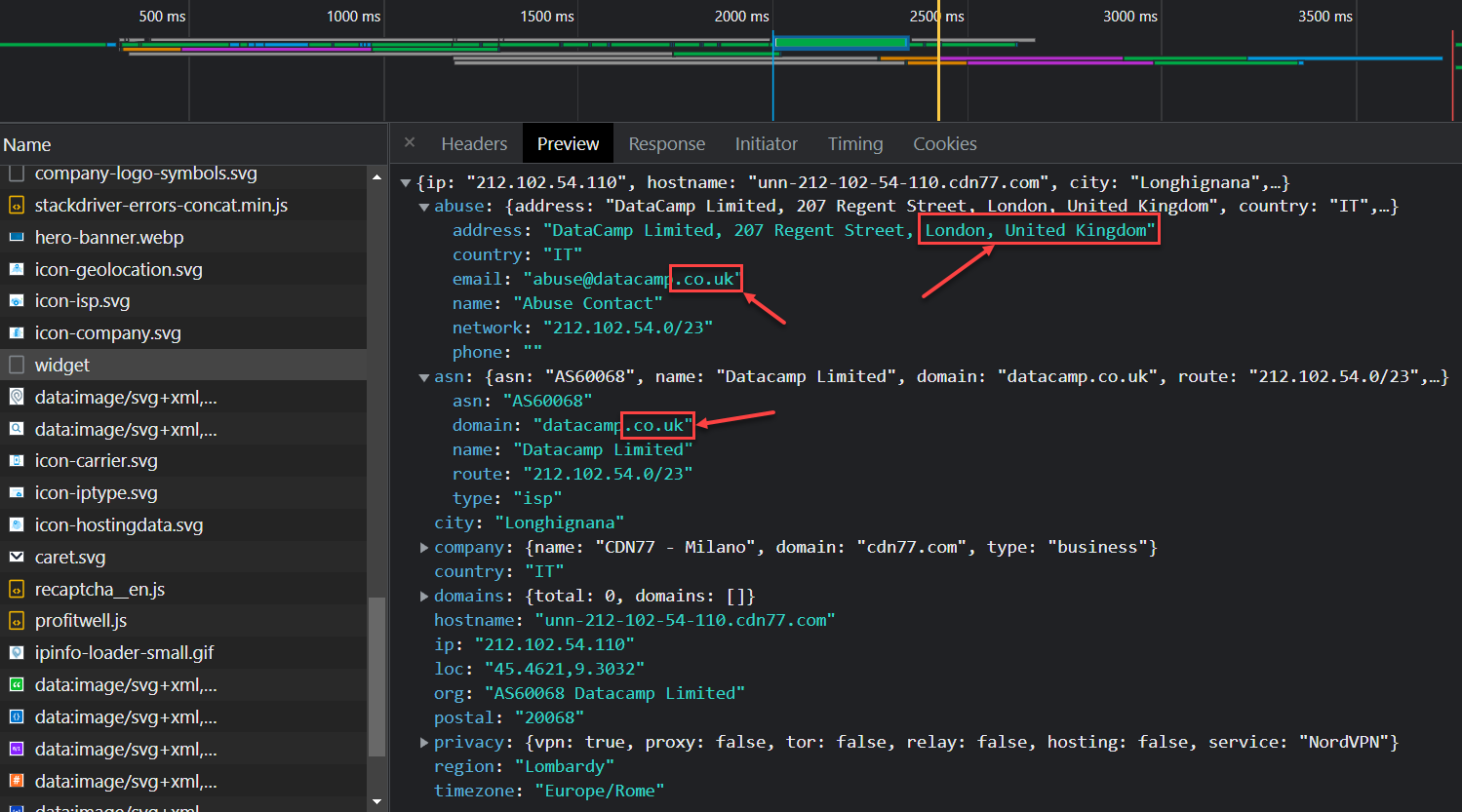
Even with the browser language set to en_US and location services off, this is the only leak I can spot. In addition to a VPN that exits in Italy, it also has to be one that doesn’t leak ASN (Autonomous System Number—used for automated routing) pointing to a different country. Dang, Google, you’re good. Time to bring my A-game.
Find a VPN Exit Node with No ASN Leak
By visiting https://nordvpn.com/servers/tools/, I can see the available VPN endpoint nodes in Italy. There are plenty of WireGuard endpoints, too. To move things forward, I add an OpenVPN tunnel in pfSense, connect to several Italian nodes, and inspect their ASNs. I want to eliminate ASN leakage as the remaining GeoIP clue. I used this guide.
Through trial and error, I found a node whose ASN is registered to an ISP in Italy.
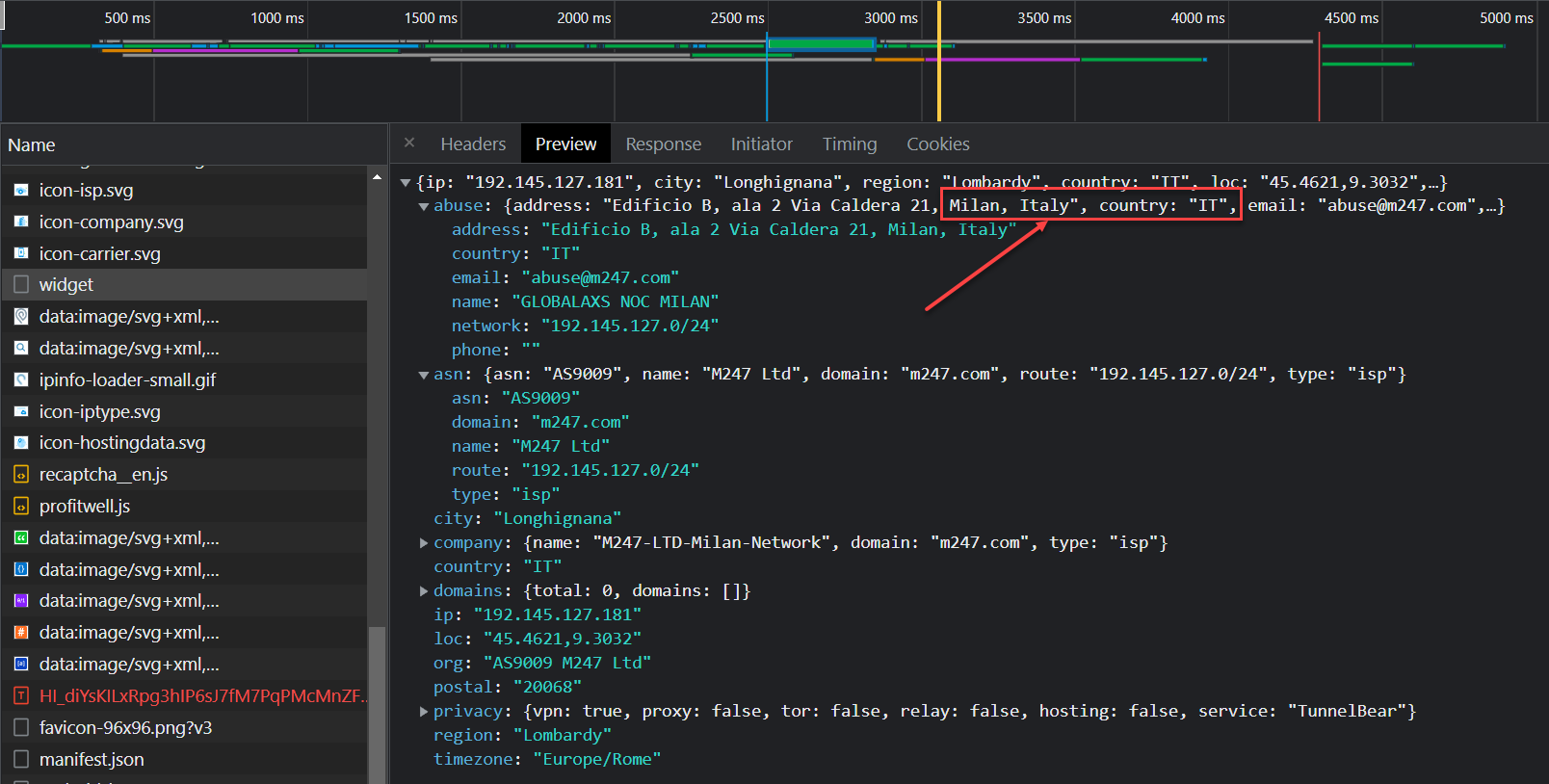
Beautiful. Bellissimo.
Hijack Google Video DNS Queries
To make any of this work, I need a technique to route the wildcard *.googlevideo.com domain through the VPN.
greps the DNS query log, keeps track of the *.googlevideo.com queries, and adds them to a unique list of aliases for Google Video domains; if backed by an LRU-eviction policy, this could keep working indefinitely. However, if each video uses a unique, mangled domain, then this does not work unless I hit refresh on every single video.On the other hand, if I “hold up” the DNS query for those *.googlevideo.com domains, add the IPs to some alias list, then allow the DNS response to finish the round-trip, we may be in business!
Where to even start? Here are some Python example scripts for inspiration. A quick mental reverse-engineering of a handful of scripts reveals that there are some event hooks available. Nice.
Among friends, let’s say that I can build up the pool of Google Video IPs in real time. How, then, do I add these IPs programmatically to the firewall alias list for YouTube without restarting the firewall? One person actually hacked the PHP scripts in pfSense—tempting, but I’ll do more research. Another person created a REST API for pfSense. Jackpot!
Research Python Methods to Hijack DNS Requests
Why this approach? It’s future-proof, modular, elegant, maintainable, automated, and it lends itself to a future decision tree that could eventually block YouTube ads outright.
First, I’ll enable SSHd in pfSense and take a peek around.
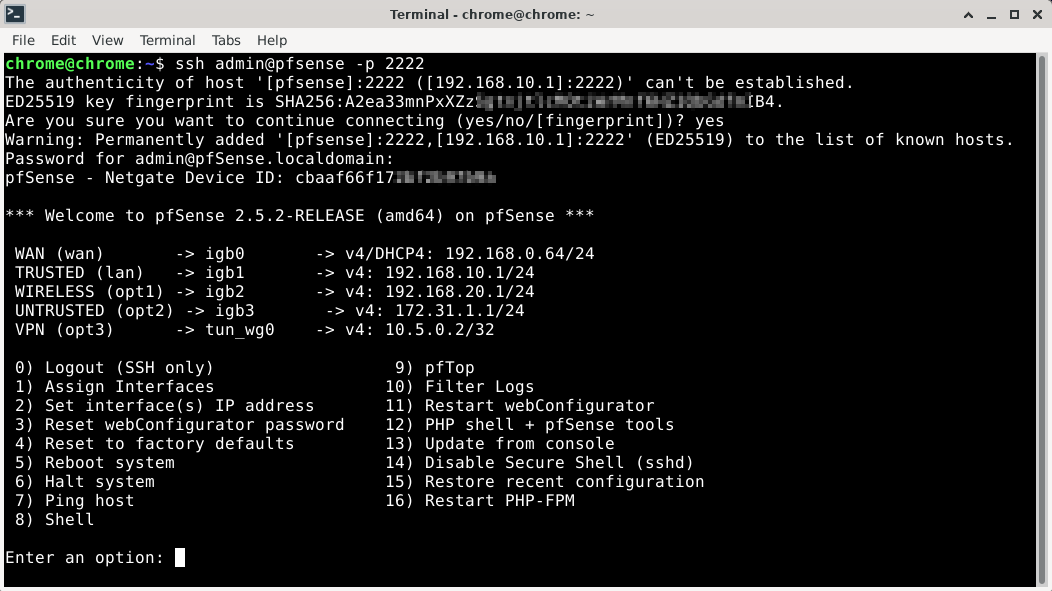
Rsync Disk Backup
Let’s take this opportunity to make a disk backup. du -h shows that only 800 MiB is in use on the SSD. Let’s rsync the whole box from our local machine; it should take about four minutes.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | # Rsync the pfSense router locally, then compress to an archive. # Tell the remote rsync to preserve ownership information. # Fix brace expansion and execute (easy to read with tr and sed). cat << EOF | tr -s ' ' | sed 's/, "/,"/g' | bash time \ rsync \ --archive \ --acls \ --xattrs \ --hard-links \ --fake-super \ --numeric-ids \ --checksum \ --info=progress2 \ --no-compress \ --whole-file \ --inplace \ --rsync-path="/usr/local/bin/rsync --fake-super --numeric-ids" \ --exclude={"/dev/*","/proc/*","/sys/*","/tmp/*","/run/*",\ "/var/*","/mnt/*","/media/*","/lost+found"} \ --rsh="ssh -p 2222" \ admin@pfsense:/ \ ~/.pfsense-backup && \ tar \ --gzip \ --create \ --file ~/pfsense-backup-`date +"%Y-%m-%d"`.tar.gz \ ~/.pfsense-backup EOF |
getfattr -d -m ^ -R -- ~/.pfsense-backupInstall pfSense REST API
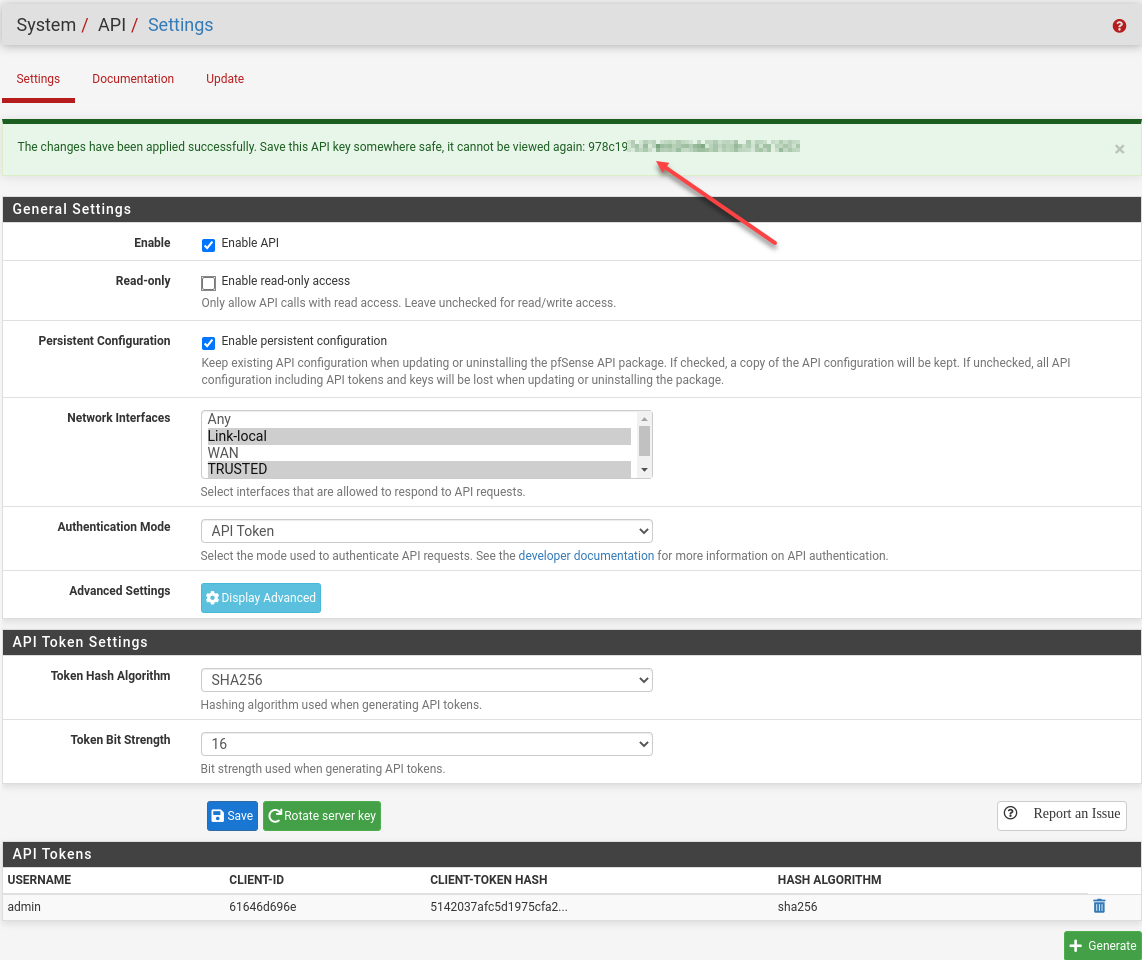
Now that we have a pfSense backup (I’m told just backing up config.xml works too), let’s install the REST API.
This part had me confused. You see, I was looking at the bottom of the screen wondering how the heck I could copy a truncated hash as a token. After a few tries, I noticed the green message at the top that I had been trained to ignore. It has the token.
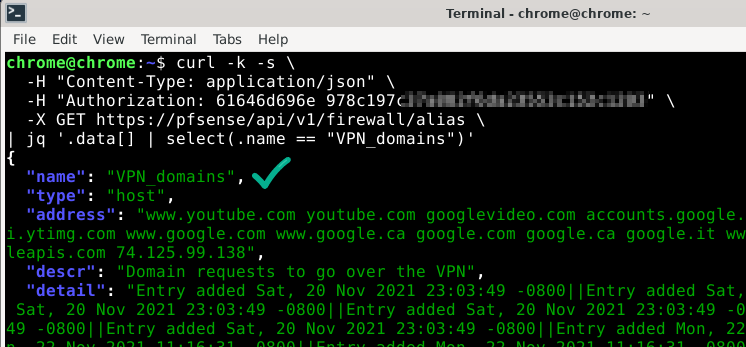
With the API credentials set up, let’s test the API:
1 2 3 4 5 | curl -k -s \ -H "Content-Type: application/json" \ -H "Authorization: 61646d696e 978c197c37a882f6da23553c152c1203" \ -X GET https://pfsense/api/v1/firewall/alias \ | jq '.data[] | select(.name == "VPN_domains")' |
Explore the Unbound Python Module
Running find / -name "py*" shows that the current Python version is 3.8.
As for the Unbound DNS Resolver, I had some luck tinkering in nano and writing simple Python 3.8 code to log DNS-query messages. We now have both parts needed to dynamically update the firewall aliases and tunnel all YouTube traffic once and for all.
If you are looking for Python module docs for Unbound, here they are:
Run these commands to quickly build the documentation:
1 2 3 4 5 | # Do this in a PyCharm venv terminal git clone --depth 1 -b master --single-branch https://github.com/NLnetLabs/unbound.git unbound pip3 install sphinx cd unbound sphinx-build -b html pythonmod/doc/ doc/html/pythonmod/ |
2to3. Also, the most important part of this whole exercise (getting the IPs from the DNS reply) is missing, so here is the hint: import ipaddress. Don’t forget to manually hack the byte strings to pull out the proper IP addresses in binary form first.Now we have Python docs and access to all the capabilities. Excellent.
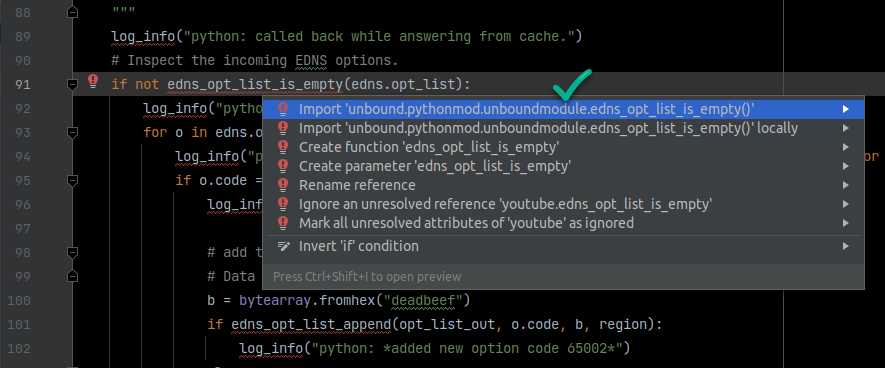
Next, I take a backup of the OS/VM and install libtool and swig, then run ./configure --with-pythonmodule, make, fix a few errors in the Unbound code, and make again. That produces the generated Python module (unboundmodule.py), which removes all those missing-method red lines in PyCharm.
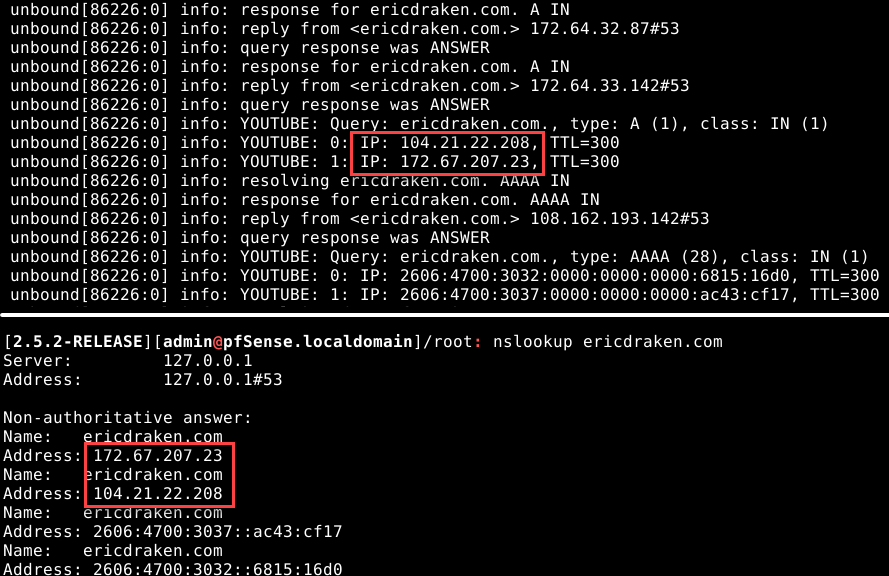
Smoke Test: A Python DNS-Hijacking Script
Here is a smoke test of the ability to hijack *.google.com DNS requests with reply IPs the script caught in just a few minutes (the timestamps simply maintain a crude LRU cache):
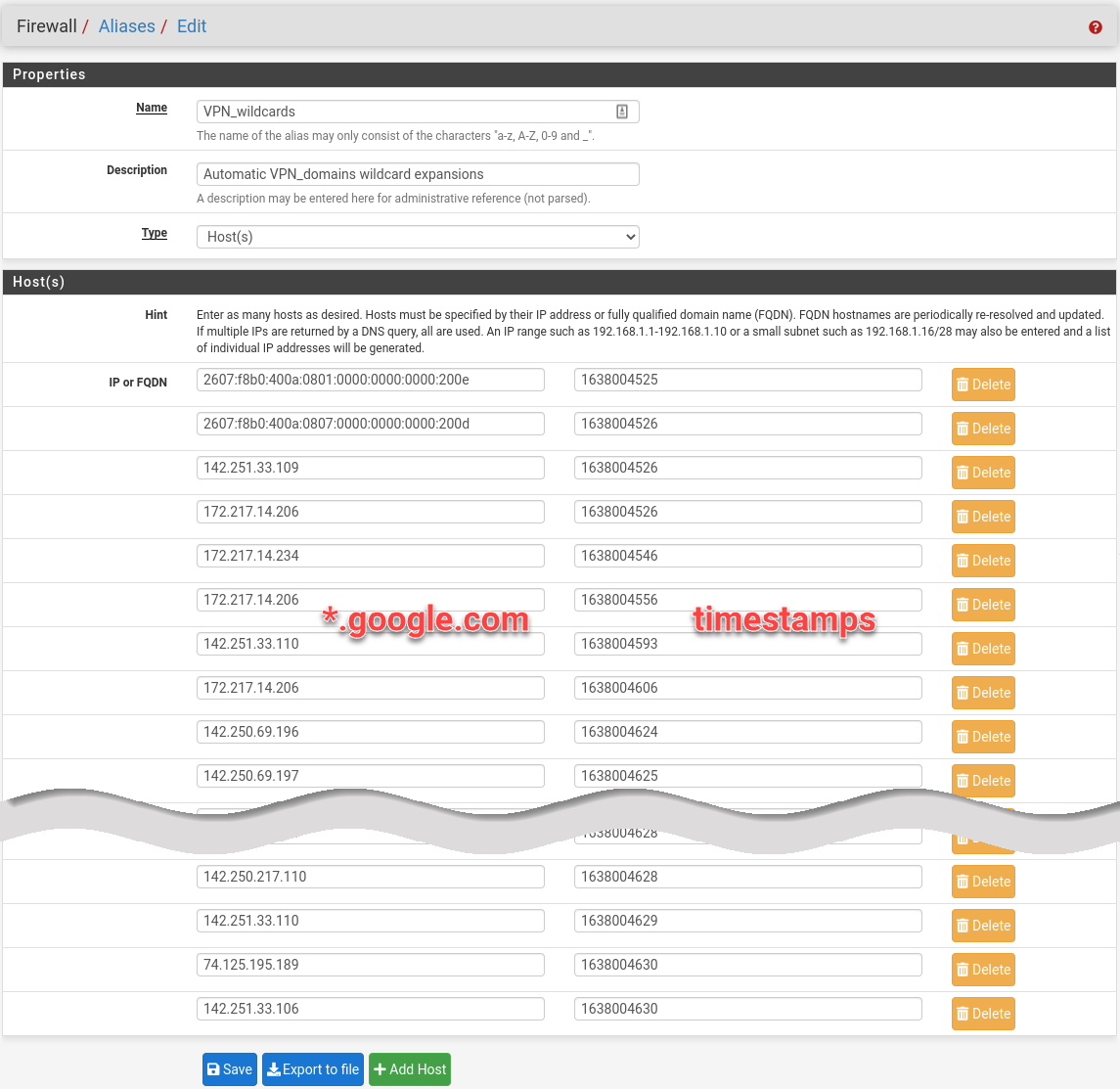
Duplicate IP addresses are possible, and that is fine. I let the smoke test run overnight. Here is the PoC (proof-of-concept) script I ran as the Unbound Python-module script.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 | # -*- coding: utf-8 -*- # Copyright (c) 2021. Eric Draken (ericdraken.com) import ipaddress import json import os import ssl import sys import time import urllib.request from typing import Final, Union FILENAME: Final = os.path.splitext(os.path.basename(__file__))[0].upper() ALIAS_VPN_WILDCARDS: Final = "VPN_wildcards" ALIAS_VPN_DOMAINS: Final = "VPN_domains" ALIAS_VPN_WILDCARDS_TTL: Final = 60 * 60 # 1 Hour ALIAS_VPN_WILDCARDS_CAPACITY: Final = 500 AUTH_CODE: Final = "61646d696e 978c197c37a882f6da23553c1xxxxxxx" TEST_MODE = True if TEST_MODE: API_ALIAS_URL: Final = "https://pfsense/api/v1/firewall/alias" API_ALIAS_ENTRY_URL: Final = "https://pfsense/api/v1/firewall/alias/entry" else: API_ALIAS_URL: Final = "https://127.0.0.1/api/v1/firewall/alias" API_ALIAS_ENTRY_URL: Final = "https://127.0.0.1/api/v1/firewall/alias/entry" # *********************************** __wildcard_patterns = set() if TEST_MODE: def log_info(msg=""): print(f"{FILENAME}: {msg}") def log_err(msg=""): print(f"{FILENAME}: {msg}") else: try: # noinspection PyUnresolvedReferences,PyUnboundLocalVariable log_info except NameError: # Added to suppress IDE errors about missing functions and constants from unbound.pythonmod.unboundmodule import ( log_info, register_inplace_cb_reply, register_inplace_cb_reply_cache, register_inplace_cb_reply_local, MODULE_EVENT_NEW, MODULE_EVENT_PASS, MODULE_WAIT_MODULE, MODULE_EVENT_MODDONE, MODULE_FINISHED, log_err, MODULE_ERROR, ) # Clarity of log messages __old_log_info = log_info __old_log_err = log_err def log_info(msg=""): __old_log_info(f"{FILENAME}: {msg}") def log_err(msg=""): __old_log_err(f"{FILENAME}: {msg}") def log_response(qstate): if not qstate: return r = None if qstate.return_msg and qstate.return_msg.rep: r = qstate.return_msg.rep q = None if qstate.return_msg and qstate.return_msg.qinfo: q = qstate.return_msg.qinfo if q: test = str(q.qname_str) if any(x in test for x in __wildcard_patterns): log_info("HIT Query: %s, type: %s (%d), class: %s (%d) " % (q.qname_str, q.qtype_str, q.qtype, q.qclass_str, q.qclass)) if r: # Do not crash the whole Unbound service try: for i in range(0, r.rrset_count): rr = r.rrsets[i] # ReplyInfo_RRSet rk = rr.rk if rk.rrset_class_str == "IN": d = rr.entry.data # RRSetData_RRData for j in range(0, d.count + d.rrsig_count): if rk.type_str == "A": ip = ipaddress.IPv4Address(d.rr_data[j][2:]).exploded elif rk.type_str == "AAAA": ip = ipaddress.IPv6Address(d.rr_data[j][2:]).exploded else: # Not an A or AAAA record continue log_info(f"{j}: IP: {ip!s}, TTL={d.rr_ttl[j]!s}") add_wildcard_ips(str(ip)) except Exception as e: exc_type, exc_obj, exc_tb = sys.exc_info() log_err(f"{exc_type}, {exc_tb.tb_lineno}, {e}") def inplace_reply_callback(qinfo, qstate, rep, rcode, edns, opt_list_out, region, **kwargs): log_response(qstate) return True def inplace_cache_callback(qinfo, qstate, rep, rcode, edns, opt_list_out, region, **kwargs): # log_response(qstate) return True def inplace_local_callback(qinfo, qstate, rep, rcode, edns, opt_list_out, region, **kwargs): # log_response(qstate) return True def init_standard(id_, env): log_info("Init start") # Register the inplace_reply_callback function as an inplace callback # function when answering a resolved query. if not register_inplace_cb_reply(inplace_reply_callback, env, id_): return False # Register the inplace_cache_callback function as an inplace callback # function when answering from cache. if not register_inplace_cb_reply_cache(inplace_cache_callback, env, id_): return False # Register the inplace_local_callback function as an inplace callback # function when answering from local data. if not register_inplace_cb_reply_local(inplace_local_callback, env, id_): return False # Prepare the aliases recreate_vpn_wildcards() global __wildcard_patterns __wildcard_patterns = get_wildcard_patterns() log_info("Init finished") return True def deinit(id_): return True def inform_super(id_, qstate, superqstate, qdata): return True def operate(id_, event, qstate, qdata): # Wait for the Python module if (event == MODULE_EVENT_NEW) or (event == MODULE_EVENT_PASS): qstate.ext_state[id_] = MODULE_WAIT_MODULE return True # Release when the Python module is finished elif event == MODULE_EVENT_MODDONE: qstate.ext_state[id_] = MODULE_FINISHED return True qstate.ext_state[id_] = MODULE_ERROR return True def request(url: str, method: str = "GET", body: object = None): # Must be HTTPS req = urllib.request.Request(url=url, method=method) req.add_header("Content-Type", "application/json") req.add_header("Accept", "application/json") req.add_header("Authorization", AUTH_CODE) ctx = ssl.create_default_context() ctx.check_hostname = False ctx.verify_mode = ssl.CERT_NONE data = None if body: data = json.dumps(body).encode() req.add_header("Content-Length", str(len(data))) try: res = urllib.request.urlopen(req, data, context=ctx, timeout=1) # Short timeout! json_ = json.load(res) if "data" not in json_: log_err(f"data attribute is missing: {json_}") return False # log_info(json_) return json_ except Exception as e: log_err(e) return False def recreate_vpn_wildcards(): # Check if the VPN_wildcard_ips alias exists aliases = request(API_ALIAS_URL, "GET") for alias in aliases["data"]: if "name" in alias and alias["name"] == ALIAS_VPN_WILDCARDS: log_info(f"Deleting existing {ALIAS_VPN_WILDCARDS}") # FIXME: If tied to a rule... it 400s request(API_ALIAS_URL, "DELETE", {"id": ALIAS_VPN_WILDCARDS, "apply": True}) break # Create log_info(f"Creating {ALIAS_VPN_WILDCARDS}") request( API_ALIAS_URL, "POST", { "name": ALIAS_VPN_WILDCARDS, "type": "host", "descr": f"Automatic {ALIAS_VPN_DOMAINS} wildcard expansions", "address": [], "detail": [], "apply": True, }, ) # Check aliases = request(API_ALIAS_URL, "GET") for alias in aliases["data"]: if "name" in alias and alias["name"] == ALIAS_VPN_WILDCARDS: log_info(f"Successfully created {ALIAS_VPN_WILDCARDS}") return log_info(f"Unable to create {ALIAS_VPN_WILDCARDS}") def evict_wildcard_ips(): cutoff = int(time.time()) - ALIAS_VPN_WILDCARDS_TTL res = request(API_ALIAS_URL, "GET", {"name": ALIAS_VPN_WILDCARDS}) data: dict = res["data"] if data: alias = data.popitem()[1] addresses = str(alias["address"]).split(" ") timestamps = str(alias["detail"]).split("||") assert len(addresses) == len(timestamps) evictable = [] for timestamp, address in zip(timestamps, addresses): if int(timestamp) < cutoff: evictable.append(address) if len(evictable): log_info(f"Evicting {evictable}") request(url=API_ALIAS_ENTRY_URL, method="DELETE", body={"name": ALIAS_VPN_WILDCARDS, "address": evictable, "apply": True}) def add_wildcard_ips(ips: Union[str, list]): if isinstance(ips, str): ips = [ips] ips_repr = ", ".join(ips) log_info(f"Adding [{ips_repr}]") res = request( API_ALIAS_ENTRY_URL, "POST", { "name": ALIAS_VPN_WILDCARDS, "type": "host", "descr": ips_repr, "address": ips, "detail": [str(int(time.time()))] * len(ips), # Must be a string }, ) details = res["data"]["detail"] # len("1638002792||") == 12 if len(details) >= (12 * ALIAS_VPN_WILDCARDS_CAPACITY) - 2: log_info("Capacity reached. Starting eviction...") evict_wildcard_ips() def get_wildcard_patterns(): patterns = set() res = request(API_ALIAS_URL, "GET", {"name": ALIAS_VPN_DOMAINS}) data: dict = res["data"] if data: alias = data.popitem()[1] details = str(alias["detail"]).split("||") for detail in details: if "*." in detail or ".*" in detail: patterns.add(detail.replace("*.", ".").replace(".*", ".")) # TODO: Make robust addresses = str(alias["address"]).split(" ") for address in addresses: patterns.add(address) log_info(f"Found wildcard patterns: {patterns}") return patterns if TEST_MODE: if __name__ == "__main__": log_info("Init start") recreate_vpn_wildcards() add_wildcard_ips("1.2.3.4") add_wildcard_ips(["1.2.3.4", "1.2.3.5"]) evict_wildcard_ips() get_wildcard_patterns() |
When I woke up, the Unbound DNS Resolver segfaulted. Here are the logs:
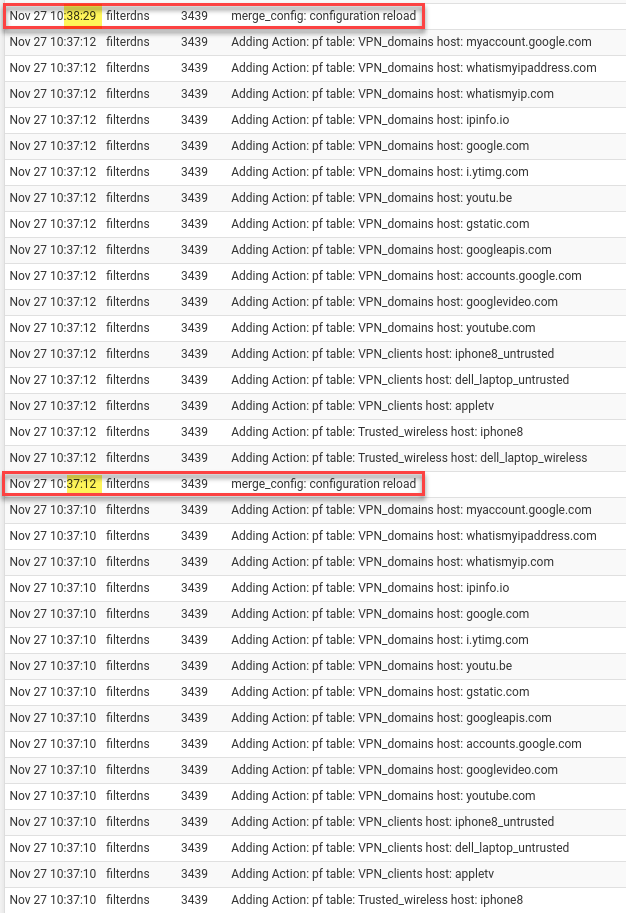
*.googlevideo.com and *.google.com puts pfSense into a crawl as all the rules need to be reloaded on each addition.Actually, it is not illegal to jailbreak most Apple TV boxes, so we could break in, add a root certificate valid for the pfSense box, MITM traffic from the Apple TV, and then Microsoft Bob is your uncle. That works because the pfSense box as the gateway can decrypt Apple TV traffic, inspect the request headers for the offending ad hostname, block the request, and re-encrypt other valid requests to Mountain View, California.
But, then my iPhone would still show ads because it is harder to jailbreak, plus banking apps may detect this and not work anymore. Jailbreaking is too extreme, anyway.
Super unfortunate was that taking a screenshot of a web page also made the same loud, un-muteable shutter sound. Imagine you are on a train and you screenshot a Google map, it makes that loud shutter noise, and then you get dirty looks from the train riders. Yeah, I had to jailbreak and zero out the camera-sound file.
Let’s see what it takes to spy on the HTTPS traffic from the Apple TV and iPhone to see if we can block ad URLs that way.
Install a Fake-but-Trusted CA Cert on Apple TV and iPhone?
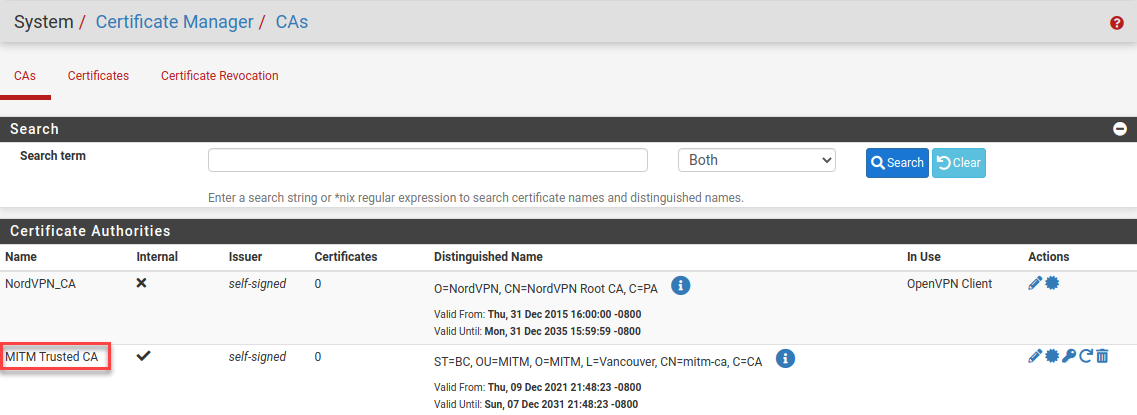
Not wanting to jailbreak and add self-signed certs to Apple TV and iPhone, I wonder: how hard would it be instead to add fake-but-trusted Certificate Authority (CA) certificates to each device?
The “A” in CA means there is no higher entity to vet such a certificate. The “A” is so powerful that, back in 2001, only a Windows patch could revoke some dangerous VeriSign certificates. As a thought experiment, new CAs must come into existence from time to time—Let’s Encrypt is relatively new, for example. There should, then, be an in-warranty way to get a fake, trusted CA cert into an Apple TV and iPhone. If that is possible, an entire world of MITM spycraft becomes available to decrypt TLS packets in the clear and use good ol’ URL blocking on requests like:
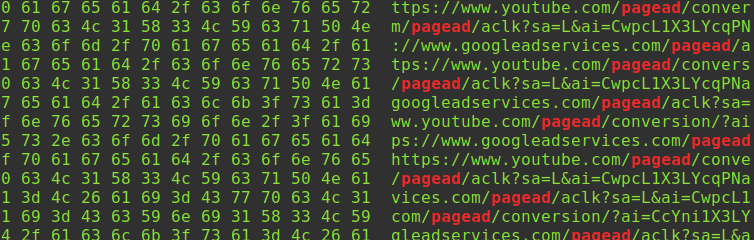
1 2 | https://www.youtube.com/pagead/viewthroughconversion/... https://www.youtube.com/pagead/conversion/... |
Let’s see how easy this would be.
In fact, there are many, many CAs. Here is a quick find / -name "*.pem" in pfSense:

Experiment with Squid and SquidGuard
I’m aware of mitmproxy, but it needs to be side-channel installed onto the pfSense router. Let’s see if the squid3 proxy that is available as a pfSense package can do what we need. First, I will take a bare-metal backup again so I can roll back in case mitmproxy is better.
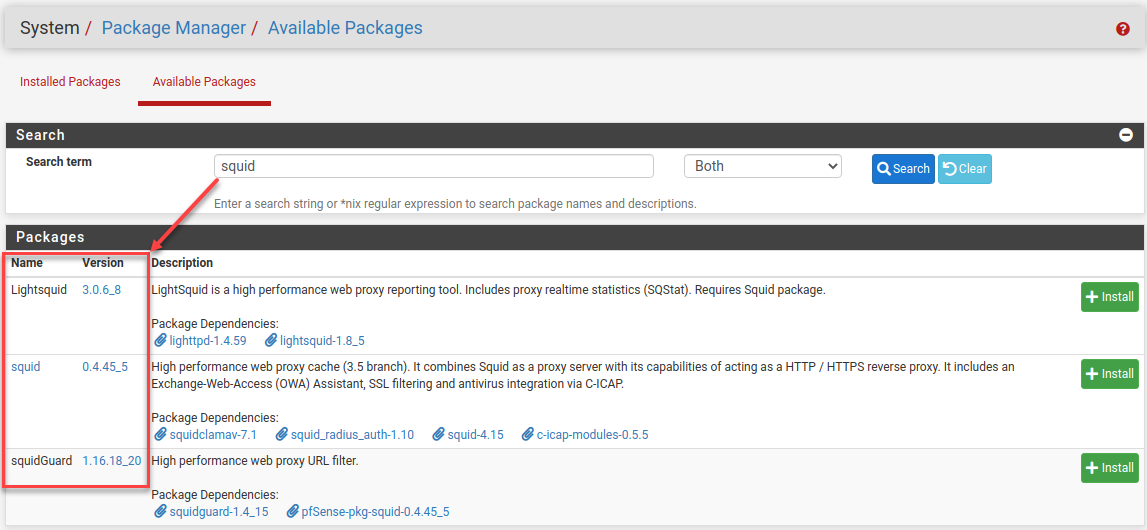
I’ve installed those packages, and naturally, there are more buttons and options than in a space shuttle. I’ll find a guide.
I’ve followed the steps in the guide. However, since I have a large SSD and generous RAM, I’ve made a dedicated folder /squid_cache (and chown squid:proxy) with 8 GiB of cache and a juicy allowance on the per-item cache size, which should also help with Docker and NPM speed-up. Two birds, one stone. With Transparent HTTPS support, this should be pretty rad.
vfs.read_max 128kern.ipc.nmbclusters 32768
Also, for local disk cache, aufs is asynchronous ufs (great for Docker too) and uses POSIX threads to avoid blocking the main Squid process on disk I/O.
We can actually generate a CA cert in pfSense itself.
Now, how to get it into the Apple TV and iPhone? It should be hosted somewhere, right? How about on the router?
Self-Host the MITM CA Certificate
Self-hosting with a single command is ridiculously easy. From the SSH shell in pfSense, I can create a web folder and server like so:
1 2 3 4 5 | mkdir /www chown -R squid:proxy /www chmod -R 644 /www echo "Hello" > /www/index.php php -S 0.0.0.0:8000 -t /www |
When I visit //pfsense:8000, I should get a blank page with “Hello.” From here, clients behind the pfSense router can temporarily access static documents.
To make life easier, here is a PHP script that forces the MITM certificate to download:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <?php $file = '/www/mitm.crt'; if (file_exists($file)) { header('Content-Description: File Transfer'); header('Content-Type: application/octet-stream'); header('Content-Disposition: attachment; filename="'.basename($file).'"'); header('Expires: 0'); header('Cache-Control: must-revalidate'); header('Pragma: public'); header('Content-Length: ' . filesize($file)); readfile($file); exit; } echo "Not found"; |
As another smoke test, I add the MITM CA to Chrome manually and enable SSL Filtering (TLS/SSL inspection). The defaults are fine in Squid. Here is the log file when I visit https://ericdraken.com:

Excellent.
However, on every other browser and machine there are HTTPS errors like so:

pfsense; pfsense.localdomain.Abandoning Squid: Too Slow, Too Heavy
After a day of painfully setting up Squid and SquidGuard, adding blacklists and manual regex patterns like .+?/pagead/.+, I’m having nothing but issues with Squid. Here are the top pain points:
- It’s slow. It’s really slow.
- The ACL (Access Control List) settings are cumbersome.
- There is an issue with
https://http/*(ref). - The SquidGuard URL filter takes eons to update a list.
- The Squid UI is unbelievably lacking.
Squid makes me sad. I don’t get sad often, but Squid makes me sad with its promise and ultimate letdown. I’ve obliterated Squid and restored the router from the rsync backup I made earlier. Below is a handy script that shows a diff of what Squid and related packages added.
Rsync Diff of Changes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # Show the changed files since the last rsync. # Fix brace expansion and execute (easy to read with tr and sed). cat << EOF | tr -s ' ' | sed 's/, "/,"/g' | bash time \ rsync \ --verbose \ --human-readable \ --links \ --recursive \ --checksum \ --update \ --delete \ --dry-run \ --exclude={"/dev/*","/proc/*","/sys/*","/tmp/*","/run/*",\ "/var/*","/mnt/*","/media/*","/lost+found"} \ --rsh="ssh -p 2222" \ ~/.pfsense-backup/ \ admin@pfsense:/ | grep -v '/$' # Hide folders EOF |
The output is something like this under the --dry-run option:
1 2 3 4 5 6 7 8 9 10 11 | deleting usr/local/etc/squidGuard/squidguard_conf.xml deleting usr/local/etc/squidGuard/squidGuard_blk_rebuild.conf deleting usr/local/etc/squidGuard/squidGuard__usrdbrebuild.conf deleting usr/local/etc/squidGuard/squidGuard.conf deleting usr/local/etc/squidGuard/blacklist.files deleting usr/local/etc/squid/squidGuard.conf deleting usr/local/etc/squid/squid.conf deleting usr/local/etc/squid/serverkey.pem deleting usr/local/etc/squid/exclude_domains.conf deleting usr/local/etc/lightsquid/lightsquid.cfg ... |
Install MITMProxy in a FreeBSD Jail
Even though written in Python, I’ll give mitmproxy a try next; at the very least it can be purpose-built to block YouTube ads with its rich API and Python-hook extensibility. It was a coin toss between mitmproxy and SSLSplit—a Metasploit hack tool—to achieve on-the-fly TLS interception, but the former can be scripted with Python and has a satisfying UI. Let’s go.
1 2 3 4 | set LATEST=7.0.4 mkdir /tmp/mitm-${LATEST} && cd /tmp/mitm-${LATEST} curl https://snapshots.mitmproxy.org/${LATEST}/mitmproxy-${LATEST}-linux.tar.gz --output mitmproxy-${LATEST}.tar.gz tar -xvzf mitmproxy-${LATEST}.tar.gz && rm mitmproxy-${LATEST}.tar.gz |
You’ll notice that there are only three binaries at about 24 MiB each. As I understand it, they include a self-contained Python 3 environment with frozen dependencies. I’d like to jail these binaries because—well, because. First, let’s see if there is a vulnerability report for mitmproxy at vuxml.freebsd.org. Nothing. How about at Exploit-DB? Nothing again. Good.
First, what version of FreeBSD is this pfSense install?
1 2 3 4 | freebsd-version -k # 12.2-Stable getconf LONG_BIT # 64 - This means we are using a 64-bit build |
Now, according to this guide, I’ll need to set up jails myself because they are disabled in a default pfSense installation. Not knowing FreeBSD at all before today, I had to hack around to find a URL to download the ezjail package manually. After another bare-metal backup, here are the steps I took:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | # Set versions set EZ_VER=3.4.2_1 set BSD_VER=12 # Install the ezjail package manually mkdir /tmp/ezjail && cd /tmp/ezjail curl https://pkg.freebsd.org/FreeBSD:${BSD_VER}:amd64/latest/All/ezjail-${EZ_VER}.pkg --output ezjail-${EZ_VER}.pkg pkg add ezjail-${EZ_VER}.pkg # Add a missing jail RC file # NOTE: Version 12 does not exist, so use 11 curl --output jail.tmp https://raw.githubusercontent.com/freebsd/freebsd/stable/11/etc/rc.d/jail # Check that we did not get a 404d file (cat jail.tmp | grep -q "FreeBSD" \ && mv jail.tmp /etc/rc.d/jail \ && chmod +x /etc/rc.d/jail \ && chmod u-w /etc/rc.d/jail \ && echo "Success") \ || echo "Download failed" # Enable jails by writing a file that may not exist echo 'ezjail_enable="YES"' | tee -a /etc/rc.conf.local # Init jails (takes about 30s) ezjail-admin install |
We need to do some hacking to get jail working on pfSense’s take on FreeBSD because jail is missing completely. What I’ve done is copy the jail binaries from a jail (via ezjail) back to the root system.
1 2 3 4 | cd /usr/sbin/ cp /usr/jails/basejail/usr/sbin/jail jail && chmod +x jail cp /usr/jails/basejail/usr/sbin/jail jls && chmod +x jls cp /usr/jails/basejail/usr/sbin/jail jexec && chmod +x jexec |
Let’s set up a jail for mitmproxy.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # Ignore the warnings that many ports are already bound to 127.0.1.1 ezjail-admin create mitmproxy 'lo0|127.0.1.1' # Disable procfs as we don't need processor info sed -I \ -e 's/procfs_enable=\"YES\"/procfs_enable=\"NO\"/g' \ /usr/local/etc/ezjail/mitmproxy # Start the jail ezjail-admin start mitmproxy # Show the jail ezjail-admin list # Log into the jail # We should get: `root@mitmproxy:~ # ` ezjail-admin console mitmproxy # exit # TIP: To delete a jail later: # ezjail-admin delete mitmproxy # chflags -R noschg /usr/jails/mitmproxy # rm -rf /usr/jails/mitmproxy |
This is very important: We must enable raw sockets in this jail to allow transparent proxy mode to work. If not, MITMProxy will report errors such as “Transparent mode failure: FileNotFoundError(2, ‘No such file or directory’)” or “Cannot open connection, no hostname given.” This is because raw sockets are inaccessible and server information is unavailable. We can easily edit the ezjail config file per jail like so:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | # Edit: /usr/local/etc/ezjail/mitmproxy # # To specify the start-up order of your ezjails, use these lines to # create a Jail dependency tree. See rcorder(8) for more details. # # PROVIDE: standard_ezjail # REQUIRE: # BEFORE: # # This is very important to work properly with pfSense export jail_mitmproxy_parameters="allow.raw_sockets=1" export jail_mitmproxy_hostname="mitmproxy" export jail_mitmproxy_ip="lo0|127.0.1.1" export jail_mitmproxy_rootdir="/usr/jails/mitmproxy" export jail_mitmproxy_exec_start="/bin/sh /etc/rc" export jail_mitmproxy_exec_stop="" export jail_mitmproxy_mount_enable="YES" export jail_mitmproxy_devfs_enable="YES" export jail_mitmproxy_devfs_ruleset="devfsrules_jail" export jail_mitmproxy_procfs_enable="NO" export jail_mitmproxy_fdescfs_enable="YES" # Restart the jail: # /usr/local/etc/rc.d/ezjail restart mitmproxy |
This is also very important: MITMProxy calls sudo -n /sbin/pfctl -s state, but there is no sudo in the jail. Run pkg install sudo inside the jail.
ping 1.1.1.1 inside the jail and you receive an error such as “ssend socket: Operation not permitted,” raw sockets are still blocked. If ping succeeds, raw-socket access is working as required.Now we can copy over the mitmproxy binaries and take them for a spin.
1 2 3 4 5 | # Copy the binaries into the new jail cp -r /tmp/mitm-${LATEST} /usr/jails/mitmproxy/root/ # Deal with some FreeBSD shenanigans about 'ELF binary type 0 not known' brandelf -t freebsd mitm* |
Things get tricky at this point. Running any of the binaries above results in:
1 2 3 | # root@mitmproxy:~/mitm-7.0.4 # ./mitmproxy # ELF interpreter /lib64/ld-linux-x86-64.so.2 not found, error 2 # Abort |
So, there is no /lib64 folder, nor any compatible dynamic linker that I can find. I tried this, however:
1 2 3 4 5 6 7 8 9 10 11 | root@mitmproxy:~ # ln -s /libexec/ld-elf.so.1 /lib64/ld-linux-x86-64.so.2 root@mitmproxy:~ # cd mitm-7.0.4/ root@mitmproxy:~/mitm-7.0.4 # ./mitmproxy ld-elf.so.1: Shared object "libdl.so.2" not found, required by "mitmproxy" root@mitmproxy:~/mitm-7.0.4 # ldd mitmproxy mitmproxy: libdl.so.2 => not found (0) libz.so.1 => not found (0) libpthread.so.0 => not found (0) libc.so.6 => not found (0) root@mitmproxy:~/mitm-7.0.4 # |
Apparently, there is a pkg install compat6x that can solve this for us (unavailable on pfSense), however, this is getting ridiculous! Let’s try a new tactic. Since we are in a jail, we are not bound to the crippled (read: secured) pfSense environment. Maybe we can install the mitmproxy package normally in a jail?
pkg install mitmproxy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | ... py38-urwid: 2.1.2 py38-werkzeug: 2.0.1 py38-wsproto: 1.0.0 py38-zstandard: 0.15.2 python38: 3.8.12 readline: 8.1.1 sqlite3: 3.35.5_3,1 zstd: 1.5.0 Number of packages to be installed: 50 The process will require 206 MiB more space. 33 MiB to be downloaded. Proceed with this action? [y/N]: |
And Bingo was his name-o. After this, simply running mitmproxy in the jailed console opens the MITMProxy UI. Nice. Note: this version may be one or two minor versions behind the master branch. Let’s clean up with rm -rf ~/mitm* /lib64 and do another bare-metal backup.
Exploring MITMProxy
This is getting exciting. First, in pfSense, add a virtual IP for 127.0.1.1 attached to localhost. Then, add a NAT rule to temporarily forward [Private IPs]:8080 to 127.0.1.1:8080 so the proxy is reachable from the LANs.
If I’m not already in the jail console, I run:
1 2 | ezjail-admin console mitmproxy mitmproxy --listen-port 8080 --set console_focus_follow=true |
Next, I add the proxy setting 192.168.20.1:8080 to my sacrificial notebook (auto-wiped daily). When the browser opens, I can already see colorful log entries in the MITMProxy UI.

The next step is to fetch the auto-generated CA PEM file used by MITMProxy (~/.mitmproxy/mitmproxy-ca-cert.pem). Since any CA cert here is snake oil, I’ll use the provided one. TLS traffic from my devices is safe as long as I use my own proxies.
Let’s put our earlier self-hosting approach into action. Because there is no PHP in the jail, we spin up a Python 3 web server instead:
1 2 3 4 5 6 | set PYTHON='/usr/local/bin/python3.8' mkdir ~/www # Both Python and mitmproxy run as root chmod 444 ~/.mitmproxy/mitmproxy-ca-cert.pem ln -s ~/.mitmproxy/mitmproxy-ca-cert.pem ~/www/cert.pem $PYTHON -m http.server --bind 127.0.1.1 --directory ~/www 8001 |
mitm.it; visiting that URL serves the file automatically.After installing the CA in the Trusted Root Store on my clean notebook (and rebooting), I see this:
Time to add the cert on my iPhone.
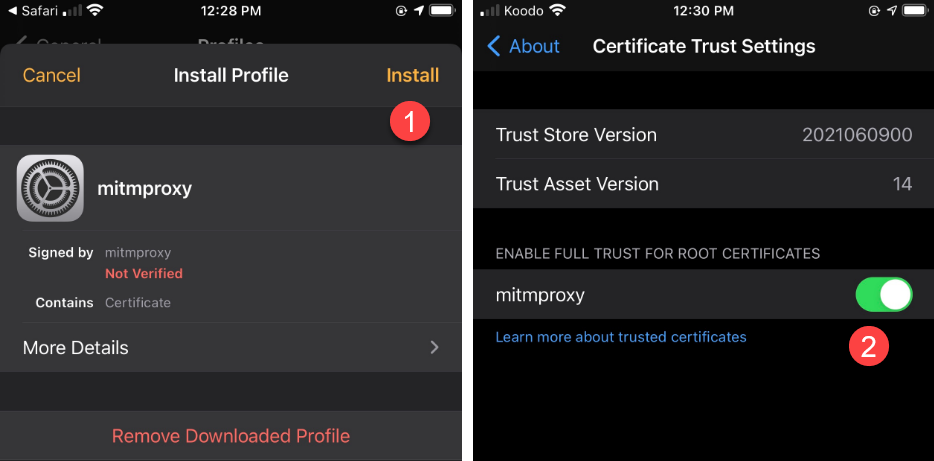
This is incredibly exciting. Can I LoJack the Apple TV box next?

Excellent.
But wait, the router is slowing down. mitmproxy is burning up the CPU… on idle.

Of course: Python is a single-threaded paradigm with the GIL (Global Interpreter Lock) ensuring threads do not actually run concurrently—unless they are blocking on I/O, which may be the case here(?). Except that most of the CPU work is to generate TLS certs on the fly for each request. Yikes. Running mitmdump forgoes the UI and extreme logging. The extreme logging of all the headers and full responses heavily slows down mitmproxy, but mitmdump by default logs entries like classic Apache logs—much kinder on the CPU.
--ignore-hosts option to let them bypass the proxy.For my fun, I’ll go with this CLI command:
1 2 3 4 5 6 7 8 9 10 | # Try to avoid compression to save CPU usage # Ignore some difficult sites mitmproxy \ --listen-port 8080 \ --listen-host 127.0.1.1 \ --anticomp \ --mode regular \ --ignore-hosts '^(?:.+\.)?apple\.com:443$' \ --ignore-hosts '^(?:.+\.)?icloud\.com:443$' \ --set console_focus_follow=true |
While on YouTube, we can see the page ads clear as day with their unencrypted headers; can a simple regex now block them? They are exposed, and afraid, and their days have run out.
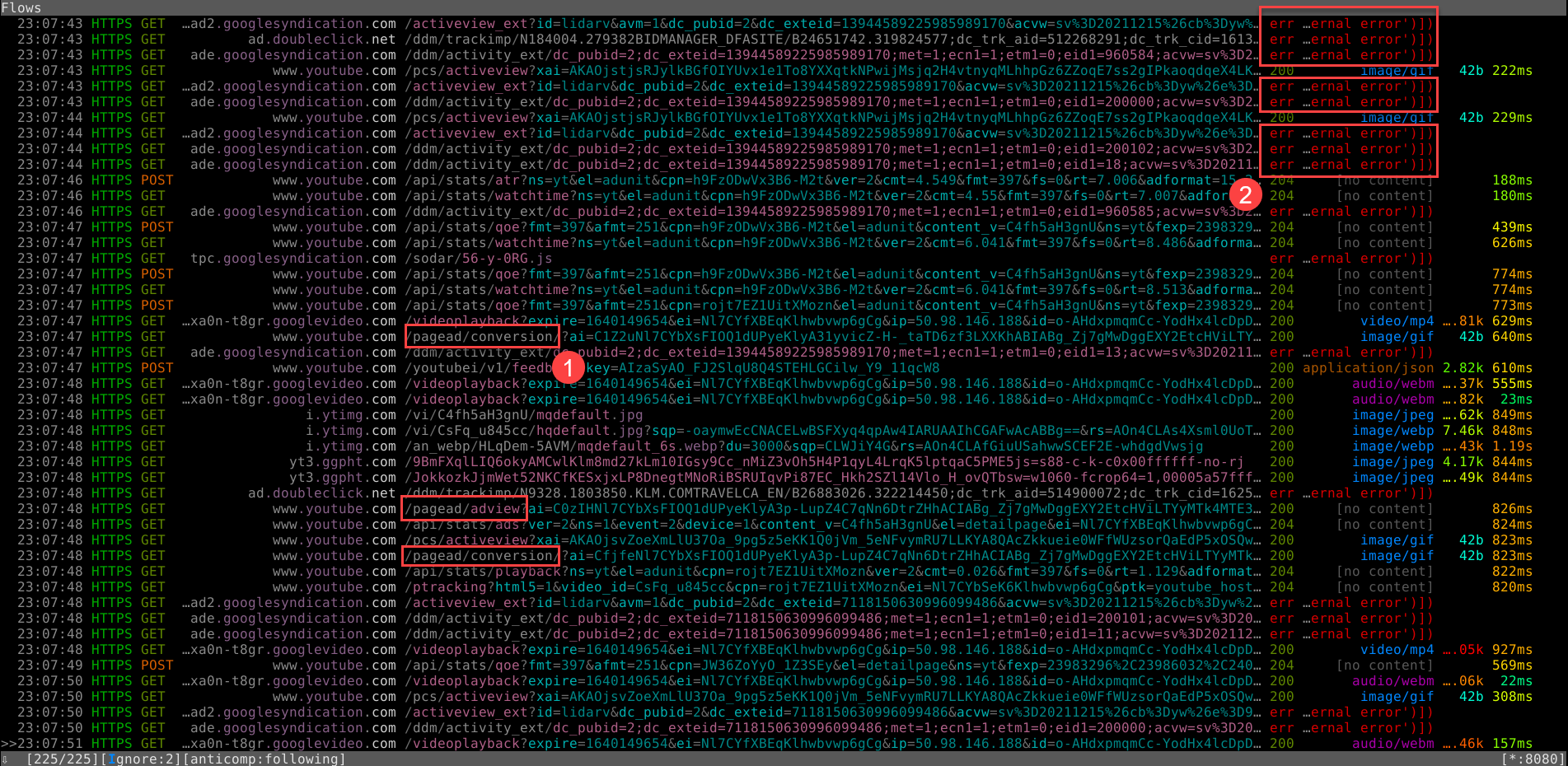
We can even see details about each request. For example, all the SAN info is laid out for this wide-reaching certificate. There are curiously a lot of *-cn.com domains covered by this cert.
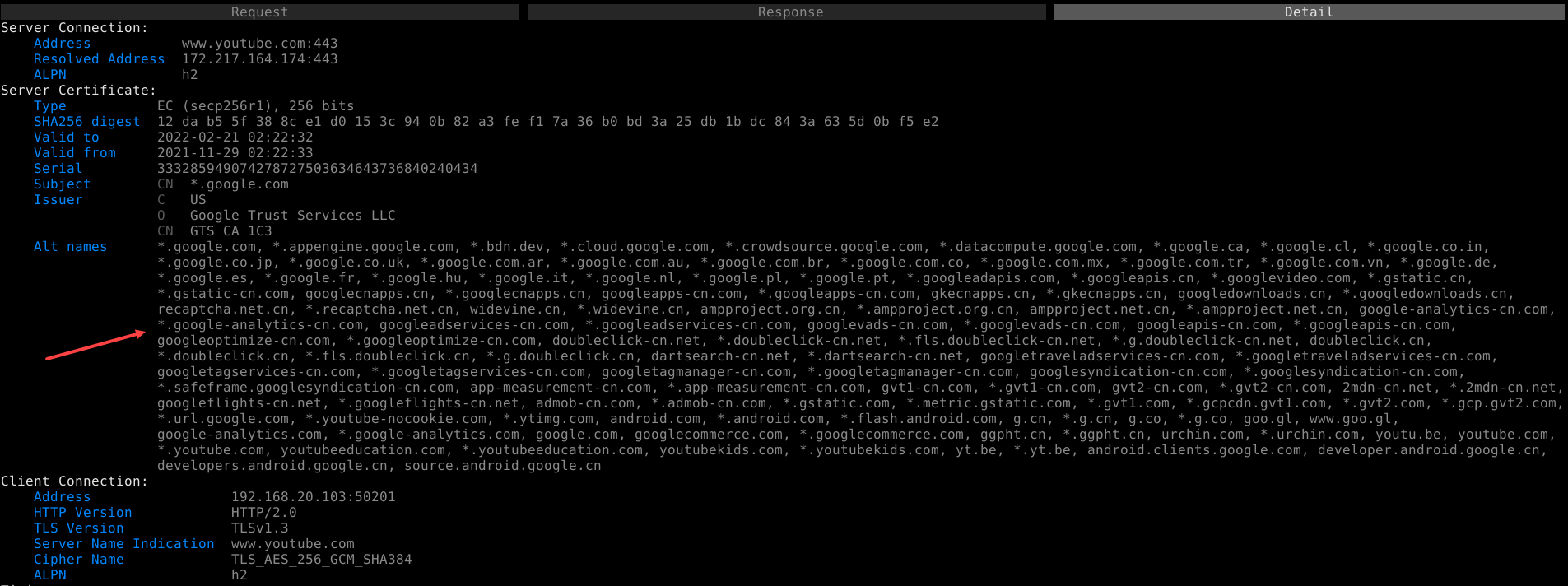
1 2 3 4 5 6 7 8 9 10 | # Try to avoid compression to save CPU usage # Use a script to block YouTube ads mitmdump \ --listen-port 8080 \ --listen-host 127.0.1.1 \ --anticomp \ --mode regular \ --ignore-hosts '^(.+\.)?apple\.com(:443)?$' \ --ignore-hosts '^(.+\.)?icloud\.com(:443)?$' \ --scripts "youtube.py" # <-- This is new |
Shortly, I’ll write a Python script to block YouTube /pagead/ URLs.
Patch MITMProxy Source Code for Server SNI Interrogation
This step may be optional for most, but as a reminder to myself: to make --allowed-hosts work better in Transparent Proxy Mode, the SNI of the server request needs to be checked against the list of regular expressions; otherwise, only the server’s IP is used for matching in many cases. Here is a quick patch I made that can be applied directly in the jail shell (or just type a few lines manually) for mitmproxy version 7.0.4:
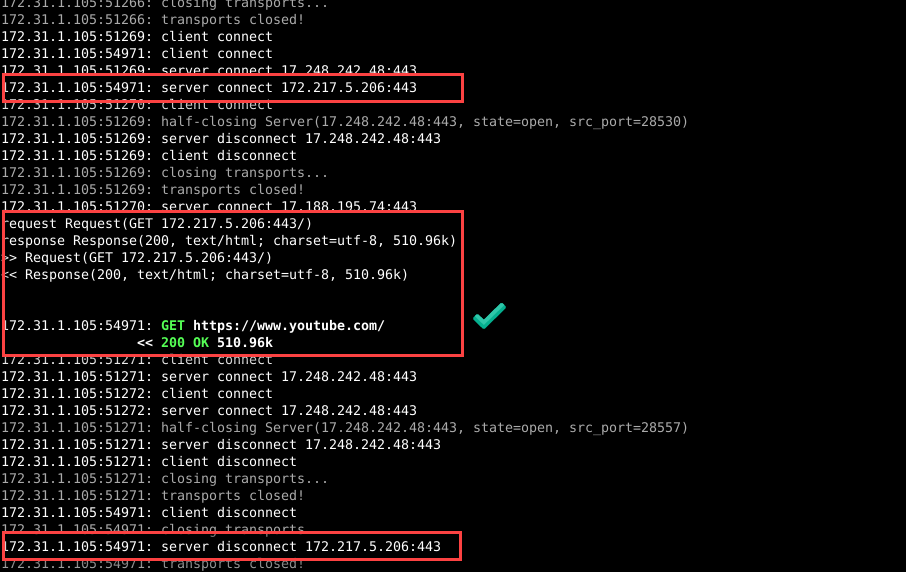
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | Index: venv/lib/python3.8/site-packages/mitmproxy/addons/next_layer.py IDEA additional info: Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP <+>UTF-8 =================================================================== diff --git a/usr/local/lib/python3.8/site-packages/mitmproxy/addons/next_layer.py b/usr/local/lib/python3.8/site-packages/mitmproxy/addons/next_layer.py --- a/usr/local/lib/python3.8/site-packages/mitmproxy/addons/next_layer.py (date 1641187083049) +++ b/usr/local/lib/python3.8/site-packages/mitmproxy/addons/next_layer.py (date 1641187083049) @@ -59,7 +59,7 @@ re.compile(x, re.IGNORECASE) for x in ctx.options.allow_hosts ] - def ignore_connection(self, server_address: Optional[connection.Address], data_client: bytes) -> Optional[bool]: + def ignore_connection(self, server: Optional[connection.Server], data_client: bytes) -> Optional[bool]: """ Returns: True, if the connection should be ignored. @@ -70,8 +70,11 @@ return False hostnames: List[str] = [] - if server_address is not None: - hostnames.append(server_address[0]) + if server is not None: + if server.address is not None: + hostnames.append(server.address[0]) + if server.sni is not None: + hostnames.append(server.sni) if is_tls_record_magic(data_client): try: ch = parse_client_hello(data_client) @@ -122,7 +125,7 @@ return stack_match(context, layers) # 1. check for --ignore/--allow - ignore = self.ignore_connection(context.server.address, data_client) + ignore = self.ignore_connection(context.server, data_client) if ignore is True: return layers.TCPLayer(context, ignore=True) if ignore is None: |
With the above patch, I can now reliably intercept a few hosts and let all others pass through.
Smoke Test: Intercept YouTube Ads with MITMProxy
After reading the docs and navigating the mitmproxy source code in the PyCharm IDE, I’ve written a little script to block ads and tracking URLs coming from YouTube on my clean notebook. I won’t reproduce the code just yet because it didn’t succeed in blocking ads as hoped, so instead, I’ll spend time investigating why.
Here are the smoke-test filters I used: for a given top-level domain, URLs containing any of the following substrings are blocked:
1 2 3 4 5 6 | blocked_partials: dict = { "youtube.com": ["/pagead/", "/log_event?", "/stats/ads", "/stats/qoe?", "/ptracking?", "/generate_204", "el=adunit", "adformat=", "/activeview?"], "google.com": ["/pagead/"], "google.ca": ["/pagead/"], "ggpht.com": ["."], } |
My initial results look good. Everything I want blocked is faithfully blocked. Note: the (failed) entries come from my script, and the 502 failures come from pfBlockerNG black-holing the request.
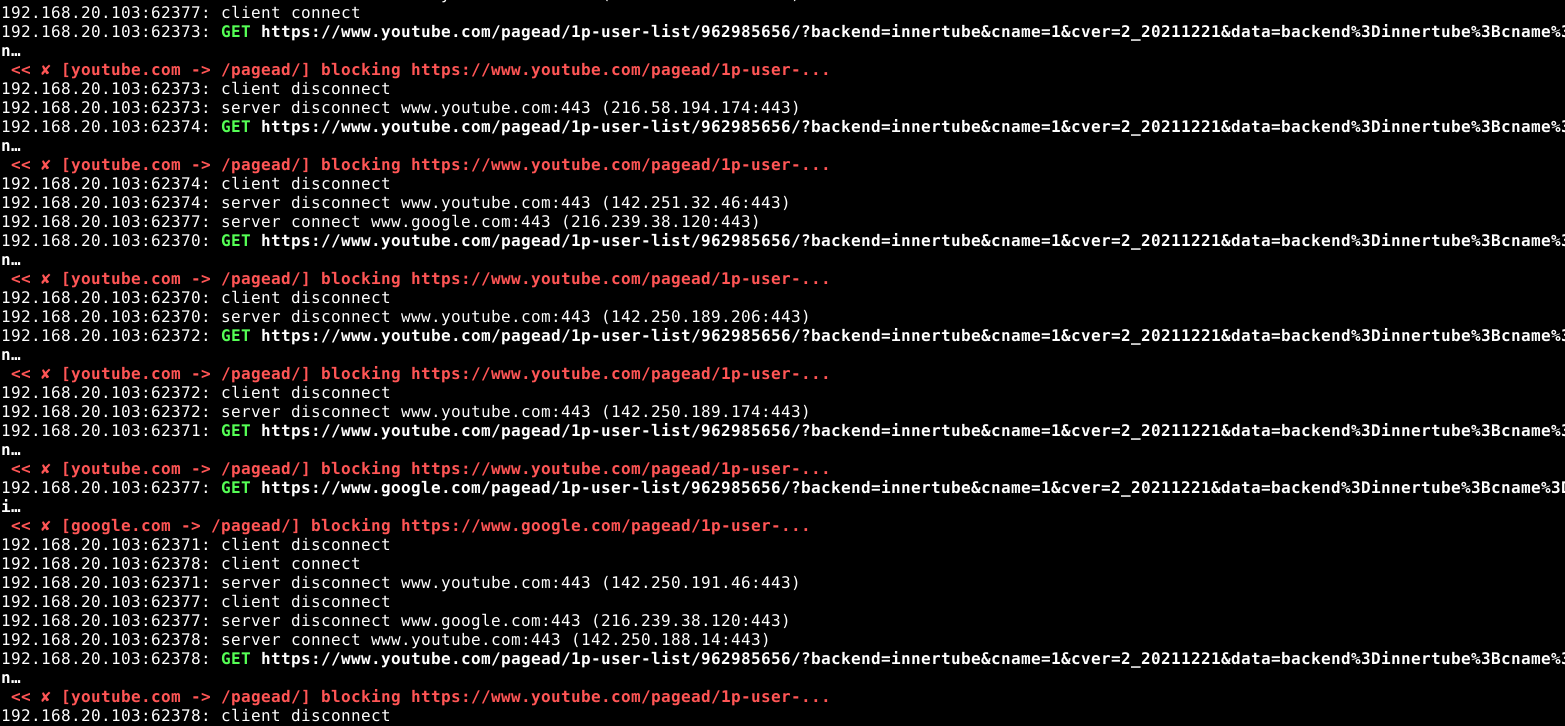
Even in the DevTools Network panel, the requests are truly blocked.
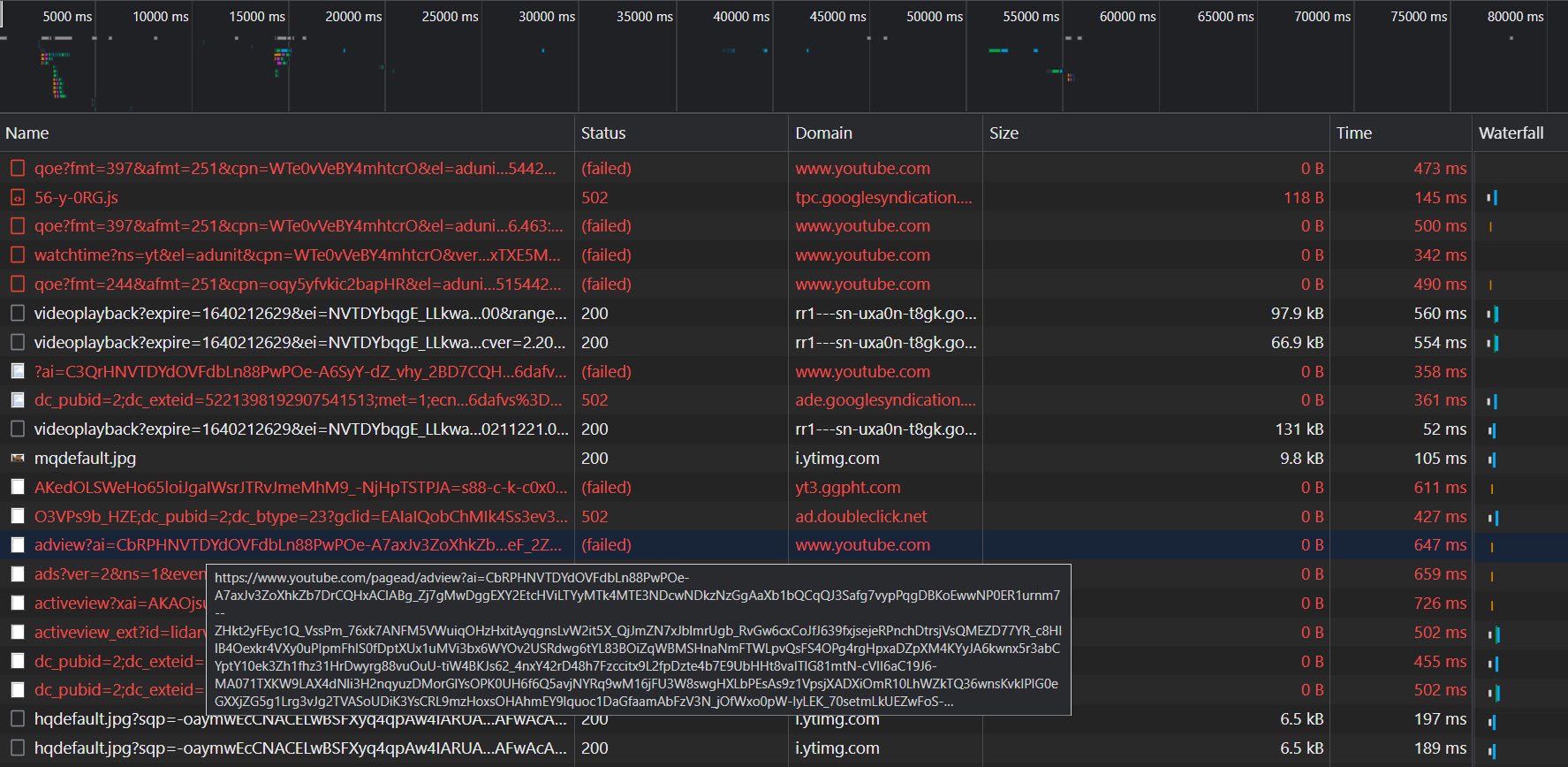
Then why am I still seeing ads? I’ve disabled HTTP/2 so that subsequent requests on the same channel don’t slide by. Sometimes the ads skip on their own or fail to play, but they still appear. Interesting. Could YouTube be using WebSockets? I need inspiration, so I’ll look at uBlock Origin’s regex filters for ideas.
mitmproxy. This error happens to black-holed domains when the upstream TLS cert cannot be sniffed. The cleanest strategy is to use transparent MITM mode.Examine uBlock Origin Regex Patterns for Inspiration
Here are some of the regex patterns/strings that uBlock Origin uses on YouTube.
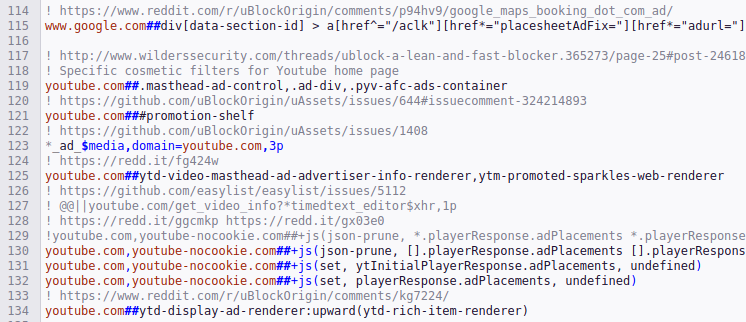
At first blush, it seems that a community of like-minded individuals is playing whack-a-mole with YouTube’s HTML and JavaScript. This has got me thinking: How does a video know to play an ad with JavaScript?
How does YouTube know if the ad converts? They must target ads for individuals, so a given video must receive some unique information about an ad—such as the click link and alt text. WebSockets would be a pain to maintain, especially with all the mobile clients. They must be using stateless JSON to relay that pertinent information in an innocuous URL request that has no telltale signs of ad-ness. Let’s hunt for this info in the JSON replies captured by mitmproxy.
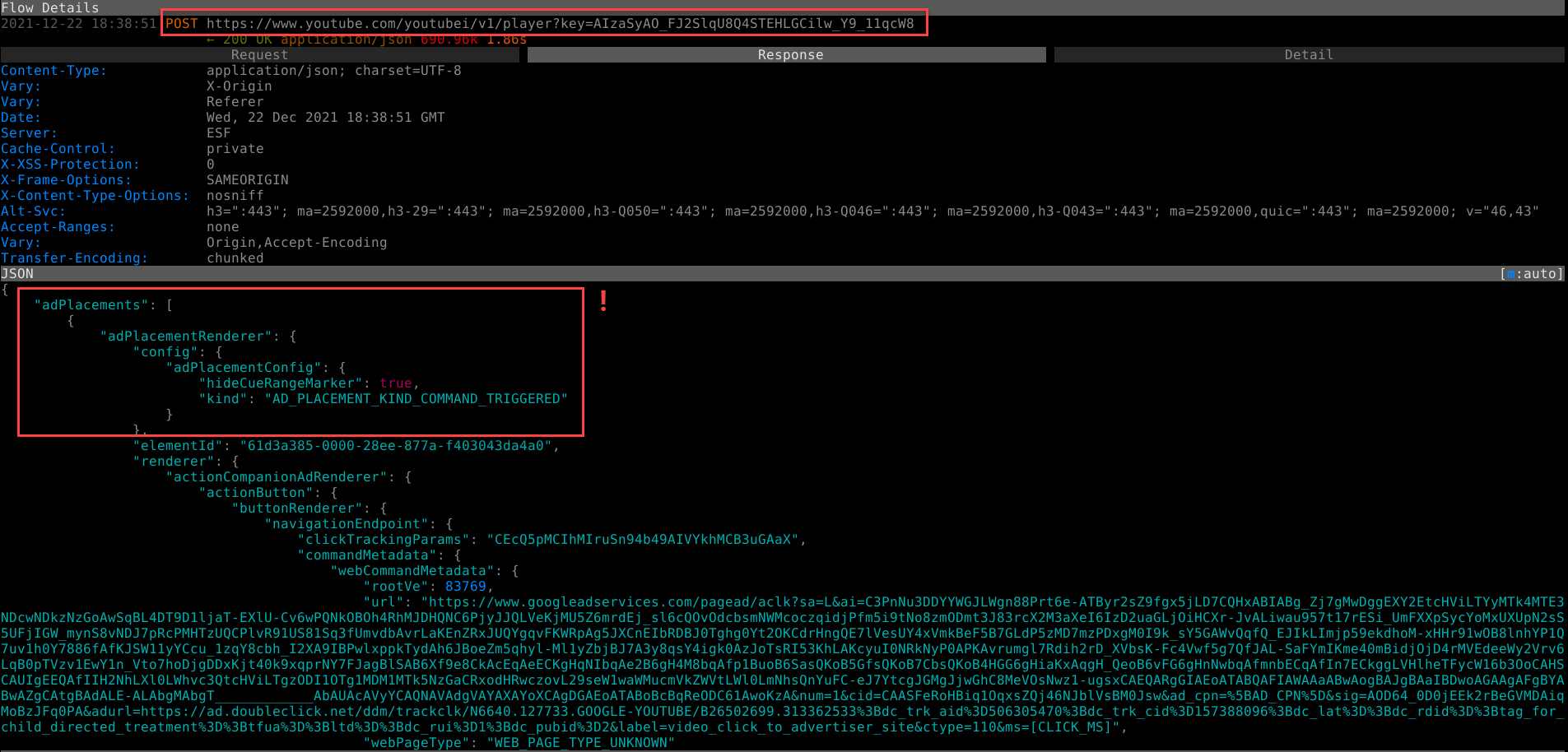
Snap, Crackle, and Pop. We have a new plan: surgically alter the JSON response body to eliminate—or Byzantine-up—the ad information.
Surgically Alter the JSON Response to Remove Ads
After a bit more playful exploration, a trove of blocklorne URLs is right there in the JSON payload. In fact, most of what I am trying to block shows up right here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | ... "playerAds": [ { "playerLegacyDesktopWatchAdsRenderer": { "playerAdParams": { "showContentThumbnail": true, "enabledEngageTypes": "3,6,4,5,17,1" }, "gutParams": { "tag": "\\4061\\ytpwmpu" }, "showCompanion": true, "showInstream": true, "useGut": true } } ], "playbackTracking": { "videostatsPlaybackUrl": { "baseUrl": "https://s.youtube.com/api/stats/playback?cl=417308503&docid=IgF3..." }, "videostatsDelayplayUrl": { "baseUrl": "https://s.youtube.com/api/stats/delayplay?cl=417308503&docid=IgF..." }, "videostatsWatchtimeUrl": { "baseUrl": "https://s.youtube.com/api/stats/watchtime?cl=417308503&docid=IgF..." }, "ptrackingUrl": { "baseUrl": "https://www.youtube.com/ptracking?ei=KnzDYZv1B86ikwa0no7AAg&oid=MjD-gn49GocgAFypi8EDnQ&plid=AAXTwR1aNKG2iTgr&pltype=content&ptchn=HnyfMqiRRG1u-2MsSQLbXA&ptk=youtube_single&video_id=IgF3OX8nT0w" }, "qoeUrl": { "baseUrl": "https://s.youtube.com/api/stats/qoe?cl=417308503&docid=IgF3OX8nT..." }, "atrUrl": { "baseUrl": "https://s.youtube.com/api/stats/atr?docid=IgF3OX8nT0w&ei=KnzDYZv1B86ikwa0no7AAg&feature=g-high-trv&len=1213&ns=yt&plid=AAXTwR1aNKG2iTgr&ver=2", "elapsedMediaTimeSeconds": 5 }, "videostatsScheduledFlushWalltimeSeconds": [ 10, 20, 30 ], "videostatsDefaultFlushIntervalSeconds": 40, "youtubeRemarketingUrl": { "baseUrl": "https://www.youtube.com/pagead/viewthroughconversion/962985656/?backend=innertube&cname=1&cver=2_20211221&data=backend%3Dinnertube%3Bcname%3D1%3Bcver%3D2_20211221%3Bptype%3Df_view%3Btype%3Dview%3Butuid%3DHnyfMqiRRG1u-2MsSQLbXA%3Butvid%3DIgF3OX8nT0w&foc_id=HnyfMqiRRG1u-2MsSQLbXA&label=followon_view&ptype=f_view&random=37068419&utuid=HnyfMqiRRG1u-2MsSQLbXA", "elapsedMediaTimeSeconds": 0 }, "googleRemarketingUrl": { "baseUrl": "https://www.google.com/pagead/1p-user-list/962985656/?backend=innertube&cname=1&cver=2_20211221&data=backend%3Dinnertube%3Bcname%3D1%3Bcver%3D2_20211221%3Bptype%3Df_view%3Btype%3Dview%3Butuid%3DHnyfMqiRRG1u-2MsSQLbXA%3Butvid%3DIgF3OX8nT0w&is_vtc=0&ptype=f_view&random=838827488&utuid=HnyfMqiRRG1u-2MsSQLbXA", "elapsedMediaTimeSeconds": 0 } }, |
However, YouTube has bobby-trapped their UI and there is more than one way their obfuscated JavaScript code can pull down the ad details.
Let’s blow it all away right now.
After plenty of fun dissecting the YouTube UI and HTTP workflow—cookies, naughty service workers, and all—I am now able to strip away every pre-roll, post-roll, and mid-video ad. Here is a mitmdump screenshot showing select REST queries intercepted, decrypted, modified, then returned with updated headers (content length, etc.):

With this new capability, we could even inject JavaScript into the main YouTube page to subvert their code in an ECMAScript arms race—perhaps leveraging filters from uBlock Origin. For today, though, we can hang our hats on this accomplishment.
The iOS YouTube App Uses Protobuf, Not JSON
I can see very similar data in the Protocol Buffer (Protobuf) version of the same API calls as the web version in the YouTube iOS app. That complicates things somewhat: I cannot lean on JSONPath to hunt down advertisement sections, because with Protobuf the keys are just numbers that can even change.
I see strings like “Telus,” “Samsung TV,” “Boxing Week,” and “Buy now.” Remember when YouTube was a fun place? A fable about a golden goose comes to mind, Alphabet.
What is a Protocol Buffer? Here is an infographic from Data Science Blog.

As a consequence of seeing unencrypted traffic from my iPhone, I’m taken aback by the sheer amount of tracking information laid bare; it’s like I have electrodes on my head and chest while I’m running on a treadmill, and a line of scientists in white lab coats with clipboards is recording everything about my internals. In other words: yikes!
https://play.googleapis.com/log/batch shows up a lot in my logs.The next question is: Does the iOS app protocol behave like the web app?
Timing Analysis to Detect Ad Videos?
The iOS network traffic is not like the web traffic; Google has teams and teams of engineers dedicated to making sure blocking their ads isn’t computationally feasible. Daunted but undeterred, I was staring at network requests letting my mind zone out when I noticed a pattern I had not seen before.
For the web version of YouTube, I can eyeball which URLs are ads and which are the videos I want to watch. Take a look:
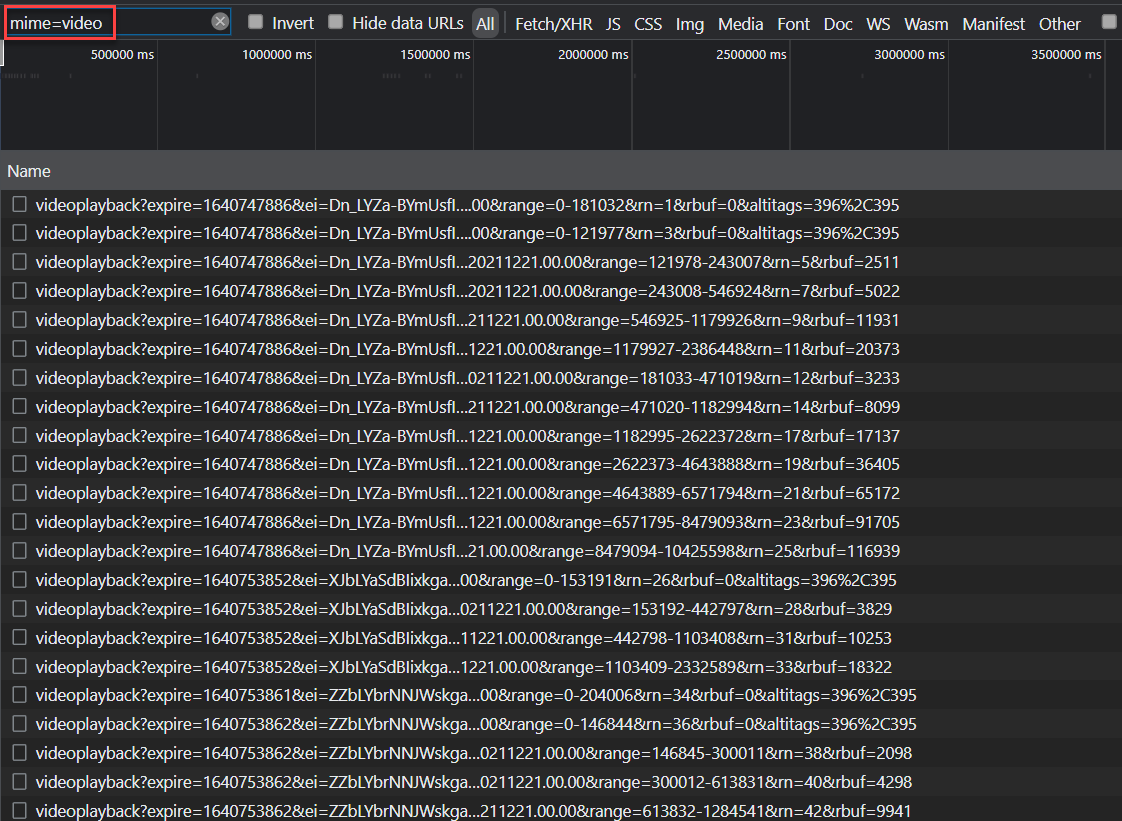
How am I able to eyeball which video URLs are ads in this chaos?
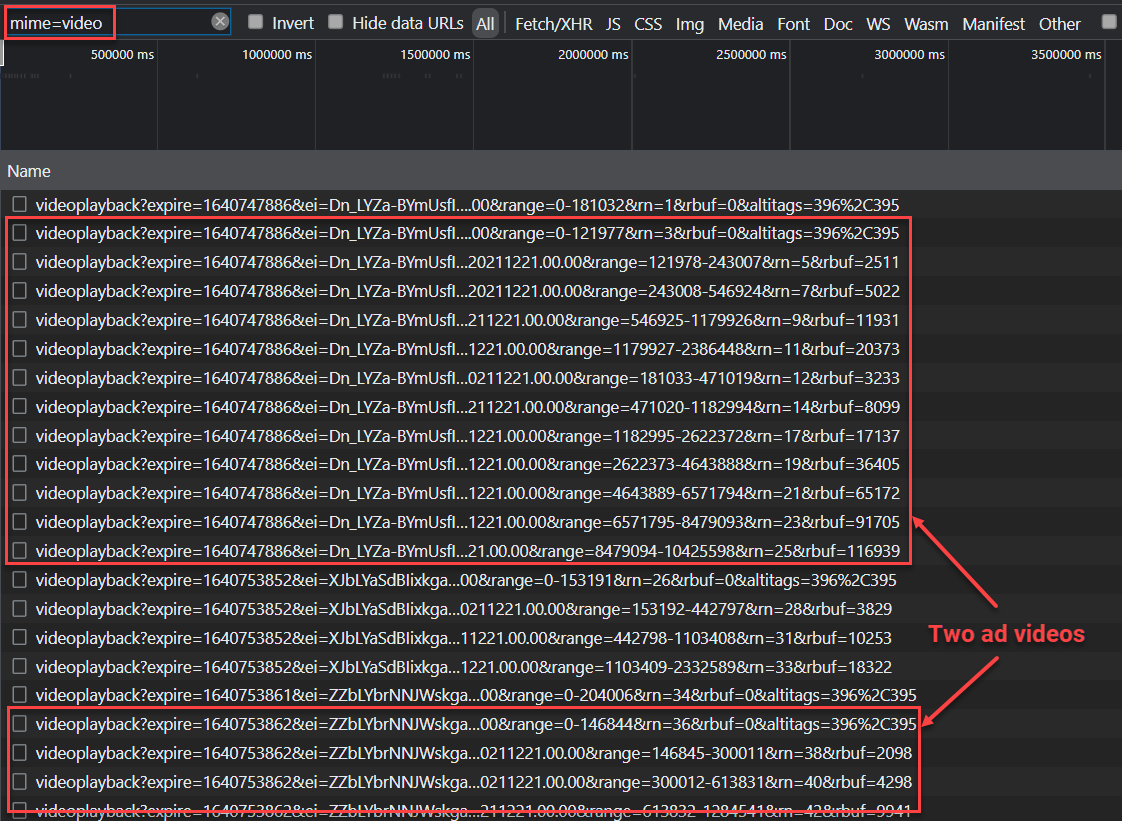
Take a look at the query parameter range. For the web version, a chunk of the video I want is fetched from byte 0, then immediately another video is fetched with a range starting again at byte 0. Both happen nearly simultaneously—faster than a human can click a new video. It turns out this, together with examining the clen parameter for the full video length (short videos are likely ads), can reasonably let us detect and doctor ad videos.
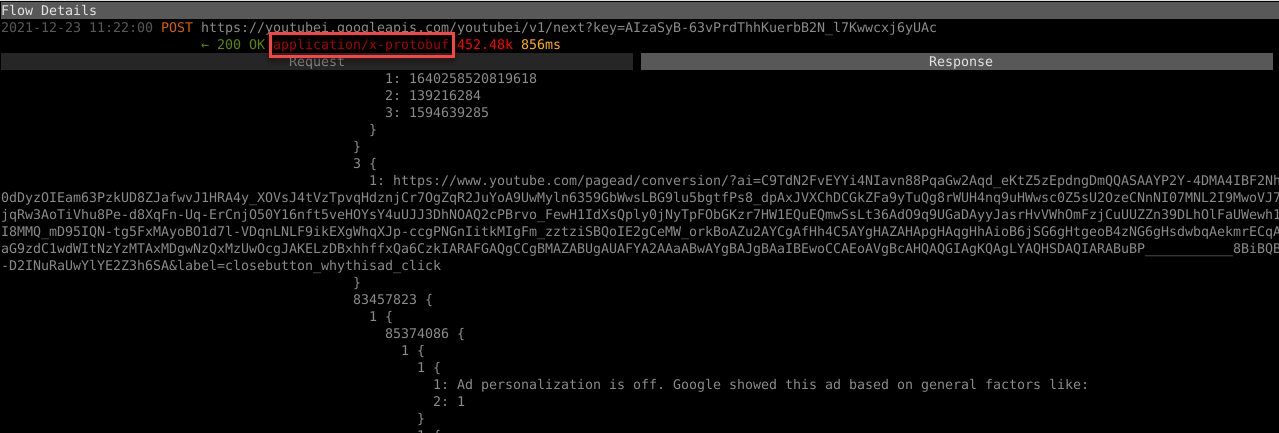
However, the iOS YouTube protocol does not use the range query parameter or even the Range header; video chunks use a counter like &nr=2 and &nr=3, etc. We must reverse-engineer the Protobuf responses.
Decode the YouTube Protobuf Responses
Here are some decoded Protobuf log files I created, then opened in the PyCharm IDE.
After logging decoded Protobuf messages to disk for offline analysis, I notice something that piques my interest.
1 2 3 4 5 6 7 8 | 2 { 1: has_unlimited_entitlement 2: False } 2 { 1: has_premium_lite_entitlement 2: False } |
I wonder what would happen if I were to, say, toggle those? This is tantalizing—but it feels like cheating, and hence no fun. Back to heuristics.

Let’s start by blocking the ads as intended.
Ad URL Polymorphism
The Protobuf responses are a hot mess of bytes, but there are human-readable URLs that I can grep.
You’d think a simple LRU cache that blocks recently encountered ad URLs could be the way to go, but, alas, the ad URLs do not quite match the URLs sent over the wire. Also, who is to say that YouTube won’t randomize the position of query-string parameters one day? We need an O(1) lookup of flagged ad URLs that are polymorphic (and group homomorphic) to live ad URLs.
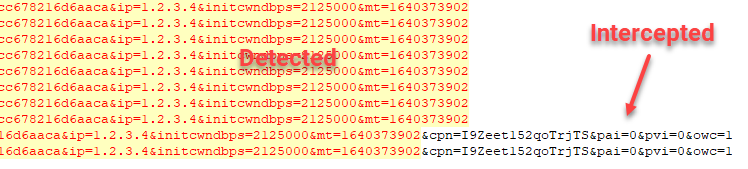
It might be tempting to split a query string into a sorted dictionary and reassemble it, but I have no way of knowing where the query-string boundary is. Plus, a live ad URL could add a key and disrupt the sorting.
Additionally, I’ve encountered URLs like this that purposely obfuscate the query params:
https://r4—sn-vgqsrns6.googlevideo.com/videoplayback
/expire/1640607416
/ei/WFrJYdWnFfyTsfIP4s2BsAk
/ip/121.35.98.26
/id/o-AE7swWOPOwXu3GyRght
/source/youtube
/requiressl/yes
/mh/wU/
/mm/31,26/…
Notice how /ip/121.35.98.26/ is just &ip=121.35.98.26?
I propose heuristically scanning for query and path parameters of ad URLs with high entropy and using those as keys (fingerprints). For example, in
https://rr6—sn-uxa0n-t8gz.googlevideo.com/initplayback?source=youtube
&orc=1&oeis=1&c=IOS&oss=1&oda=1&oad=5500&ovd=5500&oaad=11000&oavd=11000
&ocs=700&oputc=1&oses=1&ofpcc=1&osbr=1&osnz=1&msp=1&odeak=1&odepv=1
&osfc=1&id=58cc678216d6aaca&ip=121.35.98.26&initcwndbps=2125000
&mt=1640373902
One could note the following candidates in descending order of length:
- rr6—sn-uxa0n-t8gz
- 58cc678216d6aaca
- 121.35.98.26
- 1640373902
- 2125000
Any or all of them could be lookup keys, each pointing to the same dictionary of deconstructed query parameters. A lookup of a live URL would involve the same process—find the highest-entropy parameters and check the URL dictionary for a match. The cache data structure could even be multi-level, with the root keys being just the length of the high-entropy strings.
Smoke Test: Intercept and Decode Protobuf in Python
Decoding ~500 KiB of Protobuf in pure Python—especially the step that expands it to over 1 MiB of human-readable text so I can parse the ad URLs—takes longer than the connection timeout most of the time. I’ll run some benchmarks using pure Python versus the native C++ library.
Pure Python Benchmarks
1 2 3 4 5 6 7 8 9 10 11 12 13 | from timeit import repeat from mitmproxy.contentviews.protobuf import format_pbuf with open("proto.raw", "rb") as f: data: bytes = f.read() print(repeat(lambda: format_pbuf(data), number=5)) # On an i7-6700 CPU @ 3.40 GHz desktop # [2.10792827908881, 2.0718665630556643, 2.0739889848046005, 2.065321908099577, 2.070936748990789] # On the pfSense router # [24.182968072011136, 22.833560551982373, 23.53838806191925, 22.842924927012064, 22.81738876597956] |
Pure C++ Benchmarks
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # On an i7-6700 CPU @ 3.40 GHz desktop TIMEFORMAT=%R for i in {1..5}; do time protoc --decode_raw < proto.raw > /dev/null; done # 0.018 # 0.017 # 0.022 # 0.018 # 0.018 # On the pfSense router: printf 'foreach f ( 1 2 3 4 5 )\n time protoc --decode_raw < proto.raw > /dev/null \n end \n' | tcsh # 0.030u 0.114s 0:00.14 100.0% 30+153k 2+0io 0pf+0w # 0.024u 0.104s 0:00.12 100.0% 8+132k 2+0io 0pf+0w # 0.022u 0.106s 0:00.12 100.0% 34+156k 2+0io 0pf+0w # 0.016u 0.114s 0:00.13 92.3% 8+143k 2+0io 0pf+0w # 0.023u 0.102s 0:00.12 100.0% 8+132k 2+0io 0pf+0w |
If you caught that, it takes about 23 s in Python and 100 ms in C++! In this never-ending story, I need a way to parse the raw Protobuf payloads in Python using the C++ library libprotobuf.so. In the interest of time, I’ll use subprocess.Popen and communicate with the C++ protoc binary directly (since raw decoding isn’t supported in Python anyway).
Fuzzing the YouTube Video Ad Responses
How about fuzzing the ad-video responses? Now that I can isolate ad videos, as a smoke test I send back 200 responses with empty bodies, and the iOS app goes bananas—it enters an infinite loop with no delay, just hammering YouTube’s servers while trying to fetch the next part of the video in panic mode. I feel bad for their servers, so I stop. Then I wonder: what would a happy-path response payload look like?

Try as I might, when I send back empty 200s, 404s, or 503s, truncate response bodies, or just null-out part of the ad video, the iOS app crawls and then crashes spectacularly—with the dying breath of a messed-up iOS UI. I now block an error-reporting endpoint at /error_204/ that indicates a “dev assertion failed,” so I don’t make some overworked QA engineer pull out their hair.
Let’s go back to what worked with JSON and obliterate the section of the Protobuf responses that contains the array of ad details.
Enter Burp Suite Tools for Penetration Testing
There is a library for Burp Suite called blackboxprotobuf (get the original Burp Suite version, not the PyPI fork, unless you like infinite-recursion bugs). It lets us decode raw Protobuf wire messages, inject something naughty, then re-encode them to see how a Protobuf endpoint behaves.
We are going to have so much fun together in this next section.
1 2 3 4 5 6 7 8 9 | # Install blackboxprotobuf from source mkdir blackboxprotobuf_src && cd blackboxprotobuf_src git clone https://github.com/nccgroup/blackboxprotobuf.git . pip3 install poetry cd lib poetry install # pwd -> blackboxprotobuf_src/lib/ cp -r blackboxprotobuf your/project/folder # We only need this folder tree for the Py3 API |
You may encounter a small world of pain, because some forks of blackboxprotobuf cause a stack overflow from deep recursion. You can spot this by adding sys.setrecursionlimit(200).
Compiling the original library source for Burp Suite and using the C++ bindings lets us transcode roughly 500 KiB of raw Protobuf in just a few seconds.
protobuf, add1 2 | import os os.environ["PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION"] = "cpp" |
to use the C++ libprotobuf.so implementation whenever possible.
It is now possible to generate a best-guess .proto schema with a single function:
1 2 3 4 5 6 7 8 9 | import os os.environ["PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION"] = "cpp" from mitmdump.blackboxprotobuf.lib import protobuf_to_json data: bytes = ... message, typedef = protobuf_to_json(data) # print(message) print(typedef) |
The schema isn’t perfect—it’s huge, deeply nested, and slow to pretty-print—but it’s good enough to pull out the ad details, as in this Protobuf-to-JSON sample:
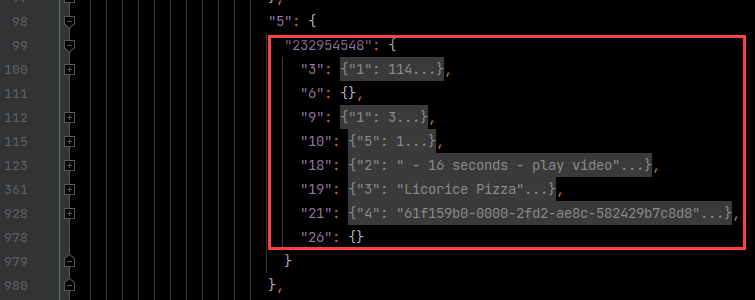
The Python schema dump starts like this—and continues for about 250,000 more characters:
1 2 3 4 5 6 7 8 | OrderedDict([ ('1', OrderedDict([ ('type', 'message'), ('message_typedef', OrderedDict([ ('6', OrderedDict([ ('type', 'message'), ('message_typedef', OrderedDict([ ('1', OrderedDict([ ... |
Reverse-engineering the full YouTube Protobuf schema sounds good on paper, but the target is spectacularly complex—and always moving.
Exfil the Proto Schemas from the App, Cleanly?
As fun as it is to reverse Protobuf and generate a best-guess schema, wouldn’t it be more ninja-like to exfil the actual, working .proto or schema files from the smartphone app? Let’s pull out the Protobuf schemas from the Android version of the YouTube app and see whether the schemas are the same—or at least compatible.
This is what I tried at first, but it went nowhere with the Protobuf Toolkit (PBTK). I reproduce it here so I remember what I tried:
1 2 3 4 5 6 | sudo apt update sudo apt install libqt5x11extras5 python3-pyqt5.qtwebengine python3-pyqt5 pip3 install pyqt5 pyqtwebengine requests websocket-client mkdir pbtk && cd pbtk git clone https://github.com/marin-m/pbtk . ./gui.py |
After installing the Qt dependencies (pronounced “cute”), I was treated to a GUI.
Next, I grabbed the most recent release of a 100-MiB Android APK file from apkpure.com.
Excited in vain, the most PBTK could extract was a 59-byte proto file. Another tool called Apktool looked promising, but the best it can do is disassemble bytecode—not decompile it. That may be good enough for pentesters, though.
What ended up working for APK decompilation is a combination of a dedicated person’s dex2jar tool and a Java Decompiler. A helpful guide can be found here.
1 2 3 4 5 6 | # Follow the install steps at https://stackoverflow.com/a/4177581/1938889 cd dex2jar chmod -R +x *.sh sh d2j-dex2jar.sh -f -o ../output.jar ../YouTube_v16.49.37_apkpure.com.apk cd ../jd-gui java -jar jd-gui-1.6.6.jar |
You can see that Google went out of its way to complicate reverse-engineering.

Google thoughtfully left a few hints.
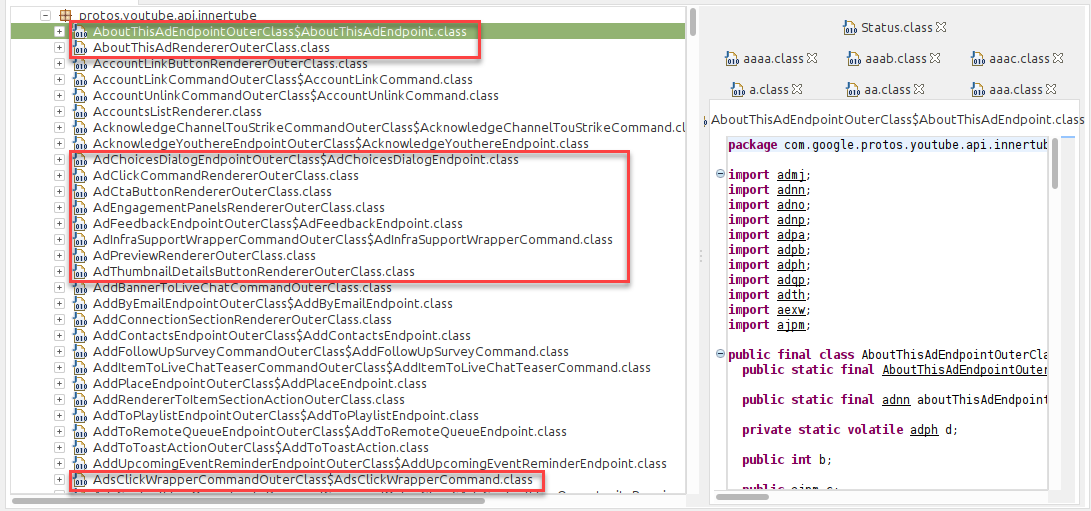
Upon deeper inspection, the Protobuf classes are right here, in Java, decorated with getters and setters. Since we are using Python and cannot get the true schema files, I will pause this approach for now.
Hardcore Deep-Dive into Protobuf and Wire Format
After gazing into a sea of decrypted network traffic again, then triggering errors and assertion fails on my iPhone with Protobuf fuzzing, and taking a peek at the error logs being phoned home, I notice that ads register for “slots” in a given video. They can register for pre-roll, mid-roll, end-roll, full-page, and ad pods (back-to-back ads). Blocking an ad URL causes an error along the lines of “some ad that doesn’t exist booked a slot,” and UI panic sets in.
I’m going to Sun Tzu the Protobuf Wire Format and come back in a bit…
I’m back. The Wire Format is surprisingly elegant, except for ZigZag encoding. Through trial and error, editing out chunks of Protobuf with a hex editor is just a no-go.
While computationally expensive, decoding, editing, and re-encoding without the original schema leads to a modified encoding. This is likely because we cannot detect whether ZigZag encoding is being used, or if a number is an int32, int64, sint32/64, varint, etc., plus the order of object fields is normally nondeterministic. Here is some Protobuf trivia on the matter:

Exploit a Protobuf Feature to Easily Remove All Ads by Changing One Byte
Feature or flaw? Well, “flaw” is a bit harsh. It is a design feature, actually, to make Protobuf robust. Let’s say among friends that the implementation of ads is flawed in YouTube’s Protobuf implementation. Yes, I like that better—Protobuf is quite elegant.
Casually poring over the C++ source code, an interesting comment in the Protobuf code catches my eye:
UnknownFieldSetis used to keep track of fields that were seen when parsing a protocol message but whose field numbers or types are unrecognized. This most frequently occurs when new fields are added to a message type and then messages containing those fields are read by old software that was compiled before the new types were added. (ref)
Yes, what to do with unknown fields? What to do indeed. And how easy would it be to change a 49399797 field key to, say, 49399796, making an entire sub-structure of advertisement and tracking information suddenly unavailable? Tantalizing.
If we can calculate the field tags in bytes with a little bit-twiddling, then we can use a simple regex to AMF1 the ad section in O(n) time.
As a motivating example, I’d like to find the field key 49399797, which is not as simple as searching for 2F1C7F5. Here is an implementation of a tag-scanning algorithm so you can see the bit-twiddling:
1 2 3 4 5 6 7 8 9 10 11 12 13 | def DecodeVarint(buffer, pos): mask = (1 << 64) - 1 result = 0 shift = 0 while 1: b = buffer[pos] result |= ((b & 0x7f) << shift) pos += 1 if not (b & 0x80): result &= mask result = int(result) return (result, pos) shift += 7 |
We know the wire type is 2 (length-delimited nested string/message), and one target field key is 49399797. When bit-twiddled, we get the target tag
AA FF B8 BC 01
where the final 01 happens to mean 2 (the wire type) in hex. In binary, this is:
10101010 11111111 10111000 10111100 00000001
Let’s lose the MSB from each byte as per the var-length wire format:
.0101010 .1111111 .0111000 .0111100 .0000001
Then we shift and add only the first four bytes since the LSB is first:
1 2 3 4 | 42 + (127 * 2^7) + (56 * 2^14) + (188 * 2^21) = 42 + (127 * 128) + (56 * 16384) + (188 * 2097152) = 42 + 16256 + 917504 + 394264576 = 395198378 |
Finally, we shift out the number of wire type bits (3) to get back the field key:
395198378 >> 3 = 49399797
And that, folks, is a taste of how Wire Format works.
Fantastic. Now, all we have to do is scan the Protobuf bytes for classic ad URL signatures like /pagead/ to bound our field search, then move backward from there until we find the target(s) field tags and thus field keys we would like to denature (e.g. 49399797 –> 49399796).
1 2 3 4 5 6 | >> Request(POST youtubei.googleapis.com:443/youtubei/v1/browse?key=...) << Response(200, application/x-protobuf, 1.87m) Intercepting https://youtubei.googleapis.com/youtubei/v1/browse?key=... (Protobuf) Found key 49399797 at position 4465 Found key 50195462 at position 4477 |
Notice how the Protobuf response payload is 1.87 MiB?
It would be computationally expensive to decode, alter, and re-encode without the original .proto files, but a quick linear byte scan takes almost no effort!
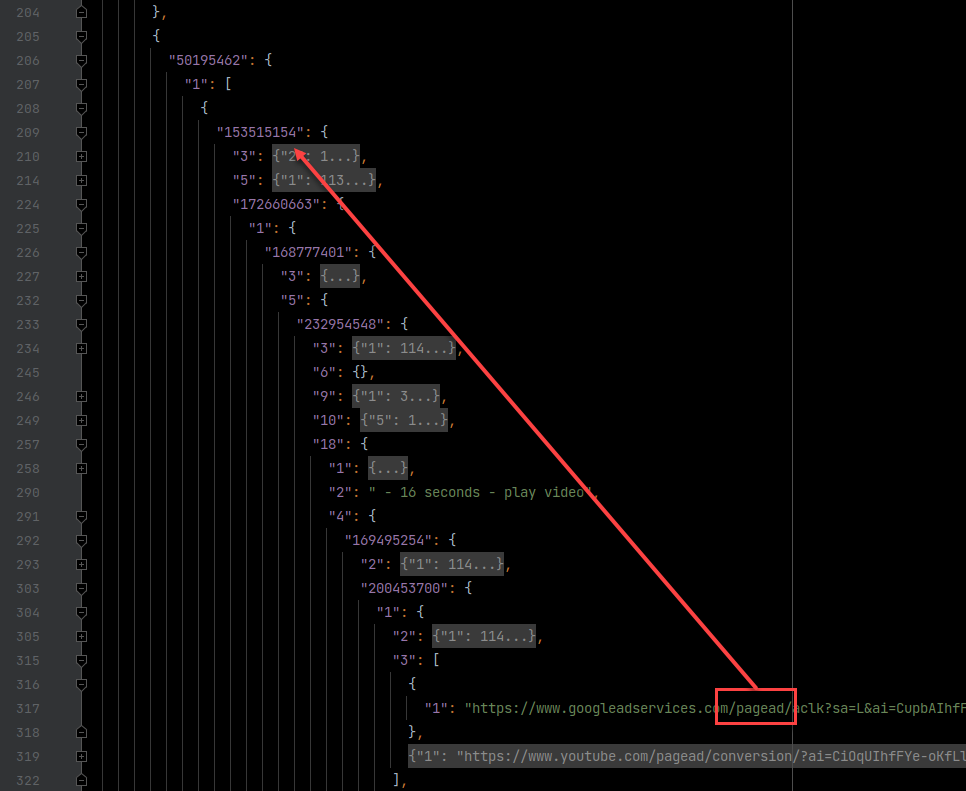
A quick note: more than one matching field tag appears, but not all represent ads. That’s why I backtrack from the /pagead/ markers.

Smoke Test: Remove Ads from Protobuf in O(n)-Time
It works! In one pass, with no additional memory, I scan a 1.8 MiB chunk of gibberish-looking Protobuf data. Only at the 30,593rd byte (of 1.8 MiB) is the target found, and backtracking ~600 bytes yields the field key to denature. Not only is this amazing, but I no longer need to block *.googleadservices.com or URLs that contain /pagead/; those requests are never made in the first place anymore.
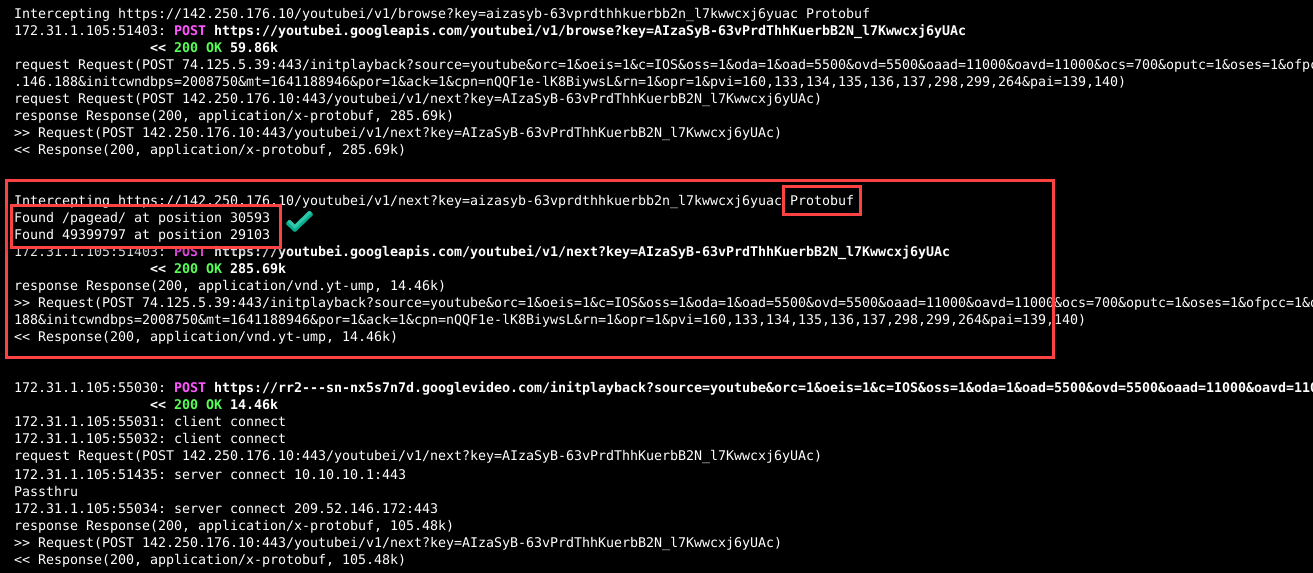
Analysis of This Successful Adblocking Technique
Summary
By taking advantage of a feature in Protobuf that lets it stay backward-compatible with schema changes—and noting that Protobuf is extremely sensitive to single-byte edits because of its compact format—we can change one byte in a critical spot and tell Protobuf that a deeply nested section belongs to a future schema version, so it is ignored. We can edit out ads elegantly.
Timing Analysis
Google returns huge Protobuf responses (for example, 1.8 MiB) that even include the iOS-app layout, so only native code (C++ / Swift) is fast enough to parse everything before the connection times out. I’ve shown that Python is several orders of magnitude too slow at decoding these payloads, so connections time out if Python touches them. With web-based JSON, the whole payload has to be parsed, edited, and re-serialized; with this Protobuf technique, the job takes microseconds—one linear scan plus a quick back-track—so it works for real-time adblocking with no blocklist. So neat.
Knock-On Benefits
Every *.googleadservices.com and /pagead/* URL on Apple devices comes from the Protobuf payload itself. Once that payload no longer contains ad data, those requests vanish for free. The YouTube app feels snappier because it never tries to fetch the ad URLs, so I avoid the endless block-list whack-a-mole. Ads never register for video “slots,” and the content just plays.
Future-Proof
This is a heuristic technique that looks for two strings: /pagead/ and a calculated field tag nearby, so the approach is future-proof.
Even if Google changes the field tag (and breaks millions of apps and Apple TVs before they upgrade), it’s an academic exercise to enhance the script and discover the new tag(s) automatically.
Should Google Be Worried?
No, not at all.
This is a highly specialized technique to block Apple-device YouTube ads (or Instagram, WhatsApp, Facebook, etc. tracker traffic). The CPU requirement to decrypt and re-encrypt HTTPS traffic greatly exceeds what a Raspberry Pi can deliver. Even if some company repackaged my script into a NIC dongle, it likely wouldn’t be powerful enough. An NVIDIA Shield could handle it, but Android users can already patch binaries directly. My technique targets Apple-device owners who don’t want to compromise the OS, which further narrows the audience.
The MITMProxy YouTube Adblocking Script
Here is the MITMProxy add-on script that serves as a proof of concept to block YouTube ads on networked Apple devices. The script can be run as follows (note the prerequisites in the script and install them first). Name the file youtube.py, then run:
mitmdump --listen-port 8080 --listen-host 127.0.0.1 -s "youtube.py"
Here is the script, including a fairness function to allow ads 5% of the time:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 | # -*- coding: utf-8 -*- # Copyright (c) 2021. Eric Draken (ericdraken.com) # Block YouTube ads on Apple devices by exploiting a Protobuf feature # # FreeBSD Prerequisites: # pkg install protobuf # pkg install py38-pip # pip install jsonpath-ng # import hashlib import inspect import json import re import subprocess import sys import traceback from datetime import datetime from json import JSONDecodeError from typing import Final from google.protobuf.internal.encoder import TagBytes from google.protobuf.text_format import WIRETYPE_LENGTH_DELIMITED from jsonpath_ng import DatumInContext from jsonpath_ng import jsonpath, parse from jsonpath_ng.ext import parse from mitmproxy import ctx, http from mitmproxy.addons.next_layer import NextLayer from mitmproxy.flow import Error from mitmproxy.proxy import layer, layers TRUNCATE_LEN: Final[int] = 120 DEBUG_MODE: bool = False class Logger: """Helper to bypass the async logger loop to view logs in real-time""" def info(self, msg): print(msg) if DEBUG_MODE else ctx.log.info(msg) def warn(self, msg): print(msg) if DEBUG_MODE else ctx.log.warn(msg) def error(self, msg): print(msg) if DEBUG_MODE else ctx.log.error(msg) def alert(self, msg): print(msg) if DEBUG_MODE else ctx.log.alert(msg) logger = Logger() def trunc(msg) -> str: """Helper for viewing very long URLs""" msg = str(msg) if len(msg) > TRUNCATE_LEN: return f"{msg[:TRUNCATE_LEN-3]}..." else: return msg class KilledError(Error): """Better logging messages than just 'Connection killed.'""" def __init__(self, reason: str) -> None: self._msg = Error.KILLED_MESSAGE self.reason = reason super().__init__(self._msg) @property def msg(self): caller = inspect.stack()[1].function # These are the only two methods that compare the msg # with KILLED_MESSAGE to perform business logic if "killable" in caller or "check_killed" in caller: return self._msg else: return self.reason # Needed to satisfy a flow setter @msg.setter def msg(self, msg): self._msg = msg class JSONPathReplacement: """Helper class to organize JSON ad replacements""" def __init__(self, tag: str, target_path: str, replacement: any) -> None: self.tag: str = tag self.target_path = target_path self.target: jsonpath.Root = parse(target_path) self.replacement: any = replacement def update(self, obj: object): found = self.target.find(obj) if found: for index, item in enumerate(found): self.target.update(item, self.replacement) logger.warn(f"Replaced `{self.target_path}[{index}]` with `{self.replacement}`") if DEBUG_MODE: found_again = self.target.find(obj) replacement_json = json.dumps(self.replacement) for index, item_ in enumerate(found_again): item: DatumInContext = item_ if json.dumps(item.value) != replacement_json: logger.error(f"Replacement of `{self.target_path}` did not succeed. Found `{json.dumps(item.value)}`") else: logger.info(f"-Skipping `{self.target_path}`") class ProtobufDebugParser: """Use the C++ protoc binary to parse raw Protobuf data. This is for debugging.""" cmd = ["protoc", "--decode_raw"] url_re = re.compile(r"(https?://[^\s\\]+)", re.IGNORECASE) def format_response(self, data: bytes) -> list: protoc_proc = subprocess.Popen(self.cmd, shell=False, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) (stdout, stderr) = protoc_proc.communicate(data) if stderr: raise Exception(stderr) return stdout.splitlines(keepends=False) def parse_response(self, data: bytes) -> list: protoc_proc = subprocess.Popen(self.cmd, shell=False, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) grep_process = subprocess.Popen(["grep", "https://"], shell=False, stdin=protoc_proc.stdout, stdout=subprocess.PIPE) (_, stderr) = protoc_proc.communicate(data) (stdout, _) = grep_process.communicate() if stderr: raise Exception(stderr) urls = stdout.splitlines(keepends=False) matches = [] for url in urls: match = self.url_re.search(url.decode()) if match: matches.append(match.group(0)) return matches class YouTubeAdBlocker: """Intercept certain YouTube domains and modify the JSON or Protobuf to remove ads from YouTube""" # Set this to the blackhole IP used by pfBlockerNG, or even a partial blackhole IP blackhole_ip_prefix: Final[str] = "10.10.10." # Intercept only these wildcard domains and no others intercept_hosts = r"\.youtube\.com|google\.(com|ca)|googleapis\.com|googleadservices\.com|googlevideo\.com" intercept_hosts_re = re.compile(intercept_hosts, re.IGNORECASE) ad_url_search_string = b"/pagead/" ad_url_search_limit = 80_000 target_field_tag = 50195462 # This is just one of several field tags protobuf_parser = ProtobufDebugParser() # Block requests from wildcard domains with any of the follow URL strings blocked_partials: dict = { "youtube.com": [ "pagead/", "log_event?", "stats/ads", "stats/qoe?", "ptracking?", "generate_204", "error_204", "adformat=", "activeview?", "_ad_", "ai?", "sw.js", # Just say no to service workers ], "google.com": ["pagead/"], "google.ca": ["pagead/"], "googleapis.com": ["pagead/"], } # Strip sections of JSON that contain ad information (for web YouTube) json_replacements = [ JSONPathReplacement("yt_ad", "$.responseContext.serviceTrackingParams[*].params[?(@.key == 'yt_ad')].value", "0"), JSONPathReplacement("adPlacements", "$..adPlacements", []), JSONPathReplacement("adPlacementRenderer", "$..adPlacementRenderer", {}), JSONPathReplacement("adPlacementConfig", "$..adPlacementConfig", {}), JSONPathReplacement("adVideoId", "$..adVideoId", ""), JSONPathReplacement("playerAdParams", "$..playerAdParams", {}), JSONPathReplacement("showCompanion", "$..showCompanion", False), JSONPathReplacement("showInstream", "$..showInstream", False), JSONPathReplacement("useGut", "$..useGut", False), JSONPathReplacement("gutParams", "$..gutParams", {}), ] @staticmethod def in_allowed_ads_window(): """Allow ads 5% of the time to support content creators which follows the CRTC rules for Student Radio. REF: https://crtc.gc.ca/eng/television/publicit/publicit.htm""" now = datetime.now() return 0 <= now.minute <= 2 """The following methods are hooks that are called during the normal flow of MITMProxy""" # noinspection PyMethodMayBeStatic def load(self, _): # Do not allow piped requests we could miss ctx.options.http2 = False try: ctx.options.update(http2=False, anticomp=True, mode="transparent", termlog_verbosity="debug") except KeyError: ctx.options.update(http2=False, anticomp=True, mode="transparent") logger.warn(f"{self.__class__.__name__} loaded") def running(self): """Intercept requests only for YouTube domains""" if ctx.options.allow_hosts != [self.intercept_hosts]: ctx.options.allow_hosts = [self.intercept_hosts] ctx.options.ignore_hosts = [] next_layer_addon: NextLayer = ctx.master.addons.get("NextLayer".lower()) next_layer_addon.configure("allow_hosts") logger.warn(f"Updated interceptable YouTube hosts") def next_layer(self, nextlayer: layer.NextLayer): """Allow blocked domains that resolve the blackhole IP to pass through""" if nextlayer.context.server.address and nextlayer.context.server.address[0].startswith(self.blackhole_ip_prefix): nextlayer.layer = layers.TCPLayer(nextlayer.context, ignore=True) # noinspection PyMethodMayBeStatic def error(self, flow: http.HTTPFlow): """The TLS failed due to an adblocker info page with no verified TLS""" if flow.error and ("OpenSSL Error" in flow.error.msg and "alert internal error" in flow.error.msg): flow.kill() def request(self, flow: http.HTTPFlow) -> None: """Block ad URLs that pfBlockerNG and Pi-hole cannot detect""" # Skip inspecting certain requests if flow.response or flow.error or (flow.reply and flow.reply.state == "taken"): return # Occasionally skip blocking ads to support content creators if self.in_allowed_ads_window(): return test_url: str = flow.request.url test_host: str = flow.request.pretty_host.lower() for host, partials in self.blocked_partials.items(): if test_host.endswith(host): for partial in partials: if partial in test_url.lower(): msg = f"✘ [{host} -> {partial}] blocking {trunc(flow.request.pretty_url)}..." logger.info(msg) # Should be a connection refused error flow.kill() flow.error = KilledError(msg) return def response(self, flow: http.HTTPFlow): """This is the main workhorse. Intercept JSON and Protobuf responses and modify them to remove or denature ad information""" # Skip inspecting certain responses if not flow.response or flow.error or not flow.response.headers: return logger.warn(f">> {flow.request}\n<< {flow.response}\n\n") # Occasionally skip blocking ads to support content creators if self.in_allowed_ads_window(): return test_path: str = flow.request.url.lower() test_content_type: str = str(flow.response.headers.get("content-type")).lower() # Examine the Protobuf payload if "protobuf" in test_content_type: logger.warn(f"Intercepting {trunc(test_path)} Protobuf") try: # Capture rich Protobuf information to disk for offline analysis if DEBUG_MODE: # TODO: This copying can be avoided, but this is debug mode, so we allow it body = bytearray(flow.response.get_content(strict=False) or b"") lines = self.protobuf_parser.format_response(body) filename = "".join(x for x in test_path[:100] if (x.isalnum() or x in "._- ")) filename = f"protobuf-{filename}-{hashlib.md5(test_path.encode()).hexdigest()}" with open(f"{filename}.formatted", mode="w", buffering=True) as f: for line in lines: f.write(f"{line}\n") with open(f"{filename}.raw", mode="wb") as f: f.write(flow.response.raw_content or b"") with open(f"{filename}.decoded", mode="wb") as f: f.write(body or b"") # TODO: Use a memory view or some more efficient search structure body: bytearray = bytearray(flow.response.get_content(strict=False) or b"") # Find a telltale ad URL, but limit the search distance = body[: self.ad_url_search_limit].find(self.ad_url_search_string) if distance < 0: return logger.warn(f"Found {self.ad_url_search_string} at position {distance}") # Search forward for an ad URL signature, then backtrack to find the field tag tag_bytes = TagBytes(self.target_field_tag, WIRETYPE_LENGTH_DELIMITED) new_bytes = TagBytes(self.target_field_tag - 1, WIRETYPE_LENGTH_DELIMITED) target_pos = body[: distance - 1][::-1].find(tag_bytes[::-1]) if target_pos > 0: target_pos = distance - 1 - target_pos - len(tag_bytes) logger.warn(f"Found {self.target_field_tag} at position {target_pos}") assert body[target_pos] == tag_bytes[0] assert body[target_pos + 1] == tag_bytes[1] assert body[target_pos + 2] == tag_bytes[2] for ind, b in enumerate(new_bytes): body[target_pos + ind] = b """NOTE: There are other field keys in different sections, and there may be multiple ad sections to denature. What preceded is a PoC of the technique that already blocks 90% of ads.""" # Example Protobuf path: b"4 {" b" 49399797 {" # Damage this key b" 1 {" b" ... /pagead/" # Example Protobuf path b" 1 {" b" 50195462 {" # Damage this key b" 1 {" b" 153515154 {" b" ... /pagead/" # Put the contents back in the response body flow.response.set_content(bytes(body)) except Exception as e: _, _, exc_traceback = sys.exc_info() traceback_ = traceback.format_tb(exc_traceback) logger.alert(f"{e!r}, {traceback_}") elif "json" in test_content_type: logger.warn(f"Intercepting {trunc(test_path)} JSON") # Examine the JSON payload try: obj = flow.response.json() for replacement in self.json_replacements: replacement.update(obj) flow.response.set_content(json.dumps(obj, ensure_ascii=False).encode()) except (TypeError, JSONDecodeError): pass # Do not stop the show except Exception as e: _, _, exc_traceback = sys.exc_info() traceback_ = traceback.format_tb(exc_traceback) logger.alert(f"{e!r}, {traceback_}") # Register the addon addons = [YouTubeAdBlocker()] |
This script works in Python for a TLS-decrypting man-in-the-middle proxy that is also written in Python. As a working proof-of-concept, it’s pretty rad. Of course, it can be rewritten in Rust, Go, or any language other than single-threaded Python, but, as an intellectual exercise to defeat ads served from the same domain as content, it’s elegant.
YouTube Premium
It’s unknown if CAD $9.99/mo $11.99/mo (about $13.43/mo with tax) is even reasonable: Do I personally incur CAD $11.99 of cost to advertisers each month?

Since ads are auctioned, the CPV (cost-per-view) varies. Also, many ad campaigns have a capped daily budget, so theoretically there should be fewer ads in the evening as budgets run out during the day.
Experiment in Ad Viewing
I watched YouTube on and off for a day on a clean notebook computer with private browsing. My history shows that I only “watched” ten videos:
- I fast-forwarded through a few to skip the “like and subscribe” padding.
- I jumped to the end of one just to get to the “top three” in a “top twenty” list.
- Two were low-quality, so I left early.
- The rest were music videos.
In all, for watching parts of ten videos, I was exposed to eight ads, and only two were skippable (which I skipped).
$0.15 as a Ballpark CPV
Let’s use USD $0.15 as a CPV. In one day, let’s say I incurred 8 x $0.15, or $1.20 to advertisers. Extrapolated to one month, that is roughly USD $36/mo. Do I really cost advertisers USD $36/mo for very casual YouTube viewing? That sounds terrible for advertisers.
CPV from U.S. Advertising Spend Divided by Total Views
From Statista, U.S. advertisers spent $15.1 billion on YouTube in 2019, while U.S. residents watched 916 billion videos (ref). That averages to $15.1B / 916B, or USD $0.0165 per view. For me, that’s only about USD $0.13 per day.
Extrapolated to one month, I theoretically caused advertisers to spend roughly USD $3.96. Wait, that’s nowhere near USD $10 for Premium. Hmmm…
Is YouTube Premium Worth It?

During my ad-viewing experiment I muted the hardware and often looked away, so ad spend was wasted on me—sorry about that. Yet I still want to support creators. At CAD $13.48 per month, Premium costs more than the ads I am personally served, and more than a Netflix subscription. The only way to justify Premium is to run YouTube constantly in the background.
However, I truly enjoy a handful of creators, so I may let their videos loop in the background. I’ll try the three-month Premium trial while still monitoring what Google tracks about me.
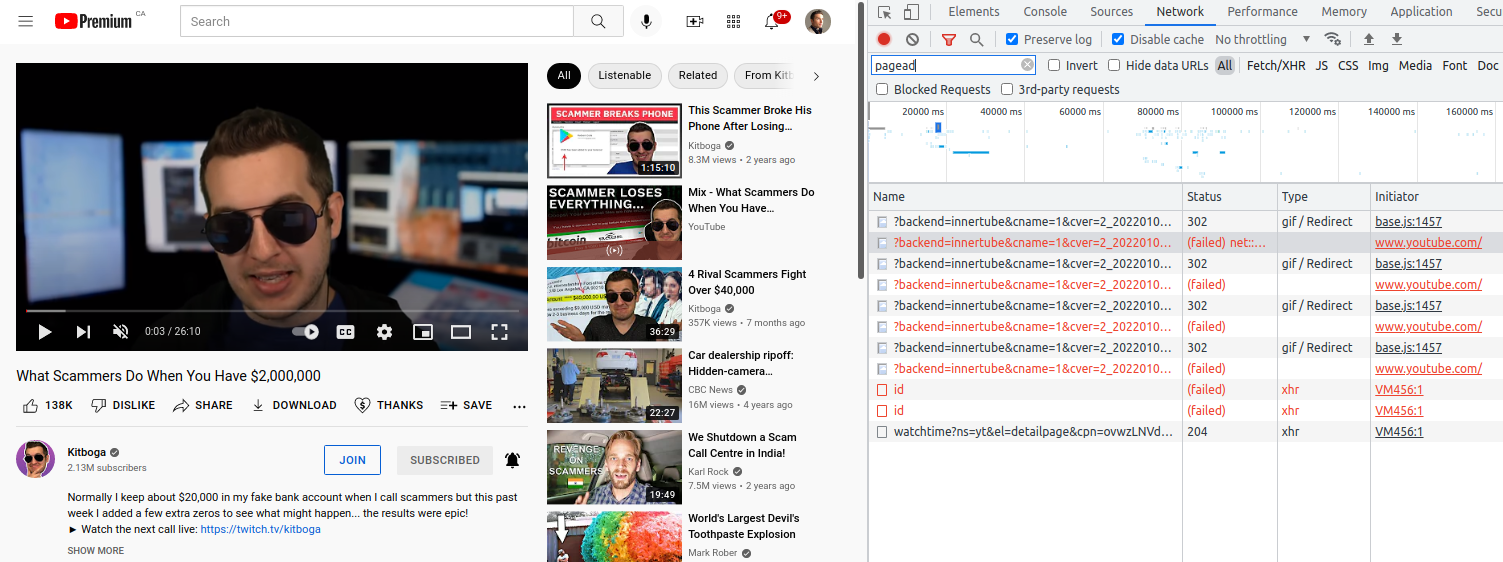
DMCA, Sony, Viacom
Recently I learned that because of abuses of the Digital Millennium Copyright Act of 1998, YouTube creators who make reaction videos or “easter-egg” breakdowns can have their videos claimed by companies like Sony or Viacom. From the moment a claim is filed, all ad revenue flows to the claimant, not to the creator—so I may unknowingly be giving nothing to my favorite channels.
Summary of Accomplishments
I rarely give up, so this is an instance of going into an extreme problem-solving mode to solve a fun problem loosely using cryptography and reverse-engineering. In the end, a single byte turned it all around, so it was all worth it to come to an elegant and satisfying solution.
Note: Now that the hard part is done, I’ll consider paying for YouTube Premium—trackers are still heavily blocked.
Notes:
- Adios, My Friend ↩