Comparison of Time-Series Data Transport Formats for Smallest Storage: Avro, Parquet, CSV
My financial time-series data is currently collected and stored in hundreds of gigabytes of SQLite files on non-clustered, RAIDed Linux machines. I have an experimental cluster computer running Spark, but I also have access to AWS ML tools, as well as partners with their own ML tools and environments (TensorFlow, Keras, etc.). My goal this weekend is to experiment with and implement a compact and efficient data transport format.
Results Summary
Parquet v2 with internal GZip achieved an impressive 83% compression on my real data and achieved an extra 10 GB in savings over compressed CSVs. Compressed CSVs achieved a 78% compression. Both took a similar amount of time for the compression, but Parquet files are more easily ingested by Hadoop HDFS.
Preliminary tests
Using a sample of 35 random symbols with only integers, here are the aggregate data sizes under various storage formats and compression codecs on Windows. They are sorted by increasing the compression ratio using plain CSVs as a baseline.
| Format | Internal Compression | Post-Compression | Size (KB) ⯆ | Ratio ⯅ |
|---|---|---|---|---|
| SQLite | 148,173 | -92% | ||
| CSV | 77,280 | 0% | ||
| SQLite | Deflate | 47,395 | 39% | |
| Avro | None | 45,969 | 41% | |
| Avro | Snappy | 27,916 | 64% | |
| SQLite | LZMA | 27,330 | 64% | |
| Parquet | None | 26,108 | 66% | |
| Parquet | Snappy | 24,793 | 68% | |
| Avro | GZip(1) | 19,563 | 75% | |
| Avro | GZip(9) | 18,781 | 76% | |
| Parquet | GZip | 18,524 | 76% | |
| Parquet | Snappy | Deflate | 18,231 | 76% |
| Avro | Snappy | LMZA | 18,093 | 76% |
| Parquet | None | Deflate | 17,895 | 77% |
| Avro | BZip2 | 17,810 | 77% | |
| Parquet | GZip | Deflate | 17,711 | 77% |
| Parquet | GZip | LZMA | 17,677 | 77% |
| Parquet (v2) | Snappy | 16,785 | 78% | |
| Avro | XZ(1) | 16,606 | 78% | |
| Avro | XZ(9) | 15,528 | 80% | |
| CSV | Deflate | 15,469 | 80% | |
| Parquet | Snappy | LZMA | 14,821 | 81% |
| Parquet (v2) | GZip | 14,764 | 81% | |
| Parquet | None | LZMA | 14,588 | 81% |
| Avro | None | LMZA | 14,555 | 81% |
| CSV | LZMA | 13,274 | 83% |
Note: The rows highlighted above show the transport formats with the most promise.
org.apache.hadoop.io.compress.GzipCodec. Snappy is supplied by org.apache.parquet.hadoop.codec.SnappyCodec. XZ is supplied by org.apache.commons.compress.compressors.xz. BZip2 is supplied by org.apache.commons.compress.compressors.bzip2. Deflate is supplied by 7-Zip on ultra compression. LZMA is supplied by 7-Zip on ultra compression. Other compression codecs for Parquet on Windows are not available without Hadoop installed.Test data: Compressed CSVs
The schema doesn’t change for the majority of the data, so CSV is simple, convenient, and plus it is human-readable. TensorFlow, for example, ingests CSV easily. In the preliminary tests above it outperformed all other transport formats when post-compressed with LZMA on ultra compression (83%). The major drawback is that the compressed transport file needs to be decompressed into bloated CSV files first (0%).
| Internal Compression | Post-Compression | Size (KB) ⯆ | Ratio ⯅ |
|---|---|---|---|
| None | LZMA | 13,274 | 83% |
Test data: Avro and Parquet (v1) with post-compression
The next most efficient data transport formats are uncompressed Avro and Parquet (version 1) with post-compression of LMZA set to ultra compression (81% and 81%). Avro is a record-based data format that contains the schema and can be split up into several files. Parquet is a column-based data format that is quick to look up or join a subset of columns. Both formats are natively used in the Apache ecosystem, for instance in Hadoop and Spark. The drawback again is that the transport files must be expanded into individual Avro and Parquet files (41% and 66%). In the sample data, expanded Parquet files occupy less space than Avro files.
| Format | Internal Compression | Post-Compression | Size (KB) ⯆ | Ratio ⯅ |
|---|---|---|---|---|
| Parquet (v1) | None | LZMA | 14,588 | 81% |
| Avro | None | LMZA | 14,555 | 81% |
![]()
Test data: Parquet (v2) with GZip
It turns out Parquet (version 2) files with GZip column-compression yield an 81% compression ratio without the need for additional post-compression. This means these Parquet files can be ingested by Hadoop’s HDFS directly without the additional pre-decompression step. An observed 81% compression is comparable to the 83% compressed CSV files.
| Internal Compression | Post-Compression | Size (KB) ⯆ | Ratio ⯅ |
|---|---|---|---|
| GZip | Store | 14,764 | 81% |
Results on full data
A cleaned export of real data into CSV format results in 146 GB (149,503 MB) of plain CSV files. When converted into the above transport formats, here are the results1:
| Format | Internal Compression | Post-Compression | Size (MB) ⯆ | Ratio ⯅ | Time (hrs) |
|---|---|---|---|---|---|
| CSV | – | – | 149,503 | 0% | – |
| SQLite | – | Deflate | 58,327 | 61% | – |
| Parquet (v1) | GZip | Store | 34,089 | 77% | 11.9 (11.1 + 0.8) |
| CSV | – | LMZA | 32,877 | 78% | 13.8 (7.2 + 6.6) |
| Parquet (v2) | GZip | Store | 25,632 | 83% | 14.0 (13.2 + 0.8) |
Full data: Compressed CSVs
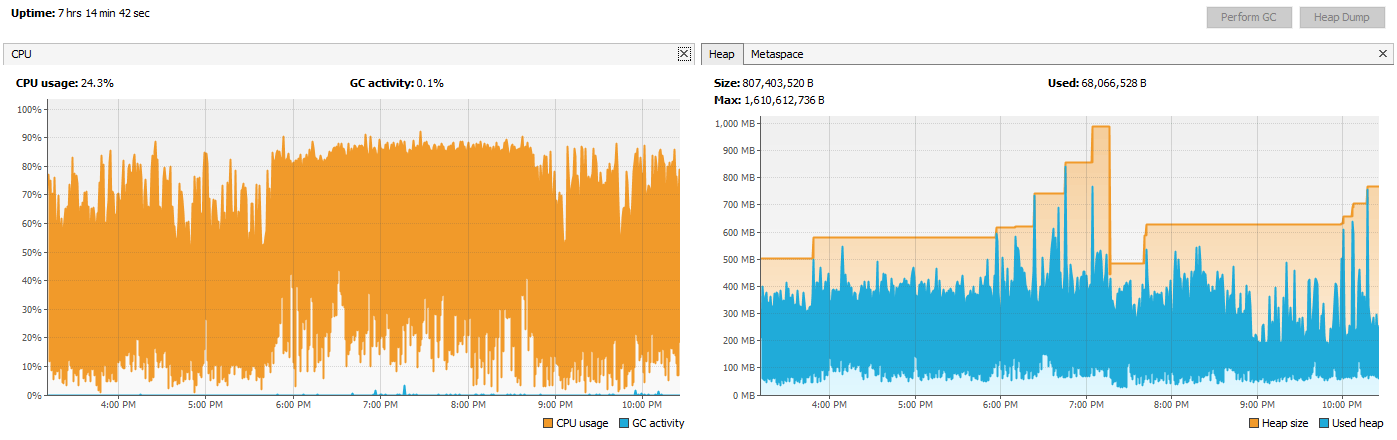
On real data, it took 7.2 hours to export to plain CSVs and another 6.6 hours to compress all the files (GZip level 6) to a single transport zip file. The 13.8 hours of processing resulted in a 78% compression. CPU and heap activity looked like below.
| Internal Compression | Post-Compression | Size (MB) ⯆ | Ratio ⯅ | Time (hrs) |
|---|---|---|---|---|
| None | LMZA | 32,877 | 78% | 13.8 (7.2 + 6.6) |
Full data: Parquet (v1) with GZip
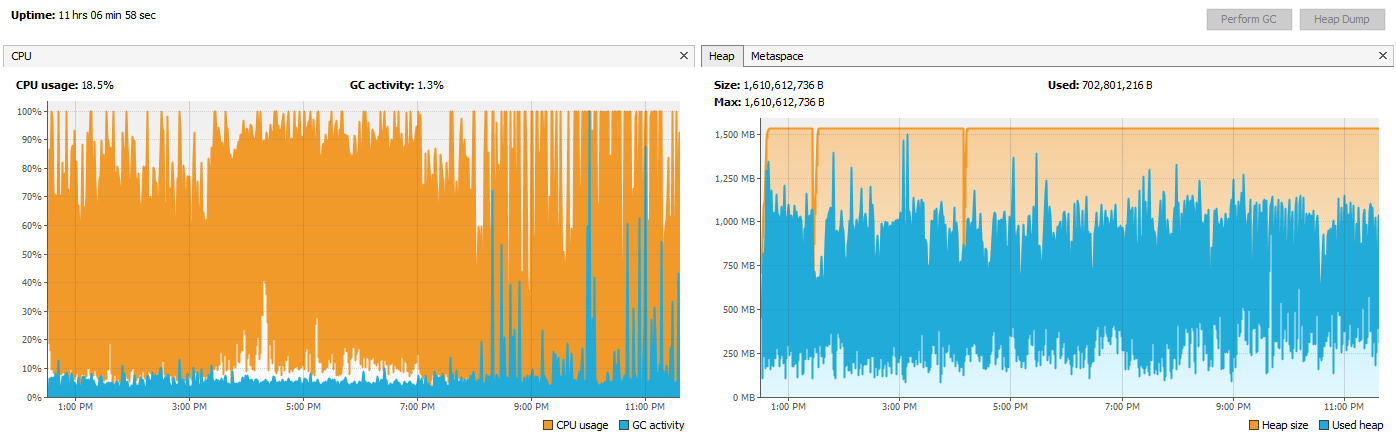
Exporting to Parquet v1 and then storing the files to a single archive took 11.9 hours resulted in a 78% compression. CPU and heap activity is as follows.
| Internal Compression | Post-Compression | Size (MB) ⯆ | Ratio ⯅ | Time (hrs) |
|---|---|---|---|---|
| GZip | Store | 34,089 | 77% | 11.9 (11.1 + 0.8) |
Full data: Parquet (v2) with GZip
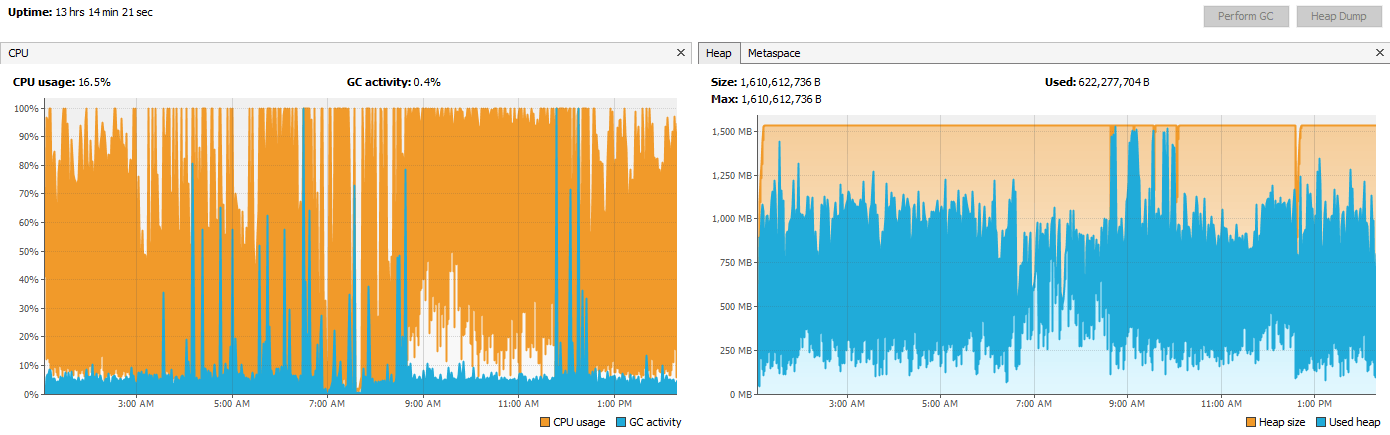
Exporting to Parquet v2 and then storing all the files to a single archive took 14 hours and achieved an 83% compression. The total CPU and heap activity is shown below.
| Internal Compression | Post-Compression | Size (MB) ⯆ | Ratio ⯅ | Time (hrs) |
|---|---|---|---|---|
| GZip | Store | 25,632 | 83% | 14.0 (13.2 + 0.8) |
Discussion
The default Parquet writer is version one. Then what is the difference between Parquet version one and two? Parquet version two uses delta encoding which is extremely well-suited for sorted timestamp columns. Instead of storing a series of four bytes for a timestamp column, only one or two bytes may be needed per entry. For instance, the difference in timestamp seconds between two minute-candles is 60 which fits in a single byte. This explains the huge compression advantage of Parquet version two – extra nearly 10 GB in savings over compressed CSVs.
Notes:
- Time in brackets denote export time then storage time to a single transport file. ↩